AWS Big Data Blog
Author: Juan Yu
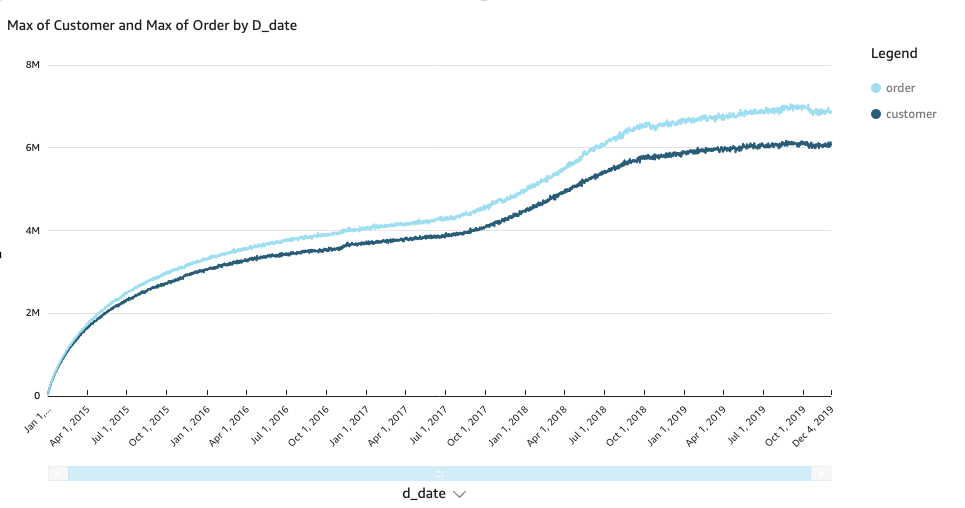
Use HyperLogLog for trend analysis with Amazon Redshift
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of […]

Speed up your ELT and BI queries with Amazon Redshift materialized views
The Amazon Redshift materialized views function helps you achieve significantly faster query performance on repeated or predictable workloads such as dashboard queries from Business Intelligence (BI) tools, such as Amazon QuickSight. It also speeds up and simplifies extract, load, and transform (ELT) data processing. You can use materialized views to store frequently used precomputations and […]

Working with nested data types using Amazon Redshift Spectrum
Redshift Spectrum is a feature of Amazon Redshift that allows you to query data stored on Amazon S3 directly and supports nested data types. This post discusses which use cases can benefit from nested data types, how to use Amazon Redshift Spectrum with nested data types to achieve excellent performance and storage efficiency, and some […]