AWS Big Data Blog
Author: Michael Chau
How Drop used the Amazon EMR runtime for Apache Spark to halve costs and get results 5.4 times faster
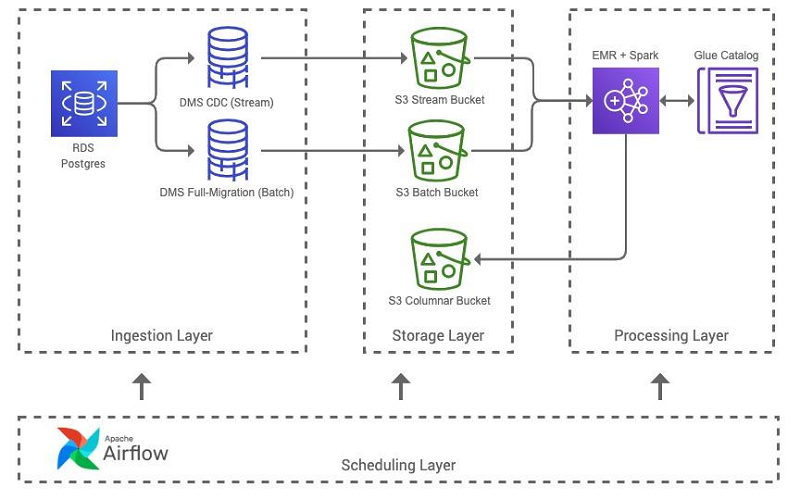
This post details how we designed and implemented our data lake’s batch ETL pipeline to use Amazon EMR, and the numerous ways we iterated on its architecture to reduce Apache Spark runtimes from hours to minutes and save over 50% on operational costs.