AWS Big Data Blog
How Drop used the Amazon EMR runtime for Apache Spark to halve costs and get results 5.4 times faster
February 2022 update – When this Blog post was published in June 2020 AWS Glue V1 offered an average starting time of 10 minutes. In September 2020 Glue V2 was released offering 10X faster start times. Because of this the part of this blog post that compares the starting times between AWS Glue and Amazon EMR is no longer valid and should not be consider as part of the selection process between these two services.
This is a guest post by Michael Chau, software engineer with Drop, and Leonardo Gomez, AWS big data specialist solutions architect. In their own words, “Drop is on a mission to level up consumer lives, one reward at a time. Through our personalized commerce platform, we intelligently surface the right brands, at the right time, to make our members’ everyday better than it was before. Powered by machine learning, we match consumers with over 200+ partner brands to satisfy two main goals: to earn points from their purchases and redeem them for instant rewards. Calling Toronto home but operating under a global mindset, Drop is building the next-level experience for our 3 million+ members across North America. Learn more by visiting www.joindrop.com.”
Overview
At Drop, our data lake infrastructure plays a foundational role in enabling better data-informed product and business decisions. A critical feature is its ability to process vast amounts of raw data and produce reconciled datasets that follow our data lake’s standardized file format and partitioning structure. Our business intelligence, experimentation analytics, and machine learning (ML) systems use these transformed datasets directly.
This post details how we designed and implemented our data lake’s batch ETL pipeline to use Amazon EMR, and the numerous ways we iterated on its architecture to reduce Apache Spark runtimes from hours to minutes and save over 50% on operational costs.
Building the pipeline
Drop’s data lake serves as the center and source of truth for the company’s entire data infrastructure upon which our downstream business intelligence, experimentation analytics, and ML systems critically rely. Our data lake’s goal is to ingest vast amounts of raw data from various sources and generate reliable and reconciled datasets that our downstream systems can access via Amazon Simple Storage Service (Amazon S3). To accomplish this, we architected our data lake’s batch ETL pipeline to follow the Lambda architecture processing model and used a combination of Apache Spark and Amazon EMR to transform the raw ingested data that lands into our Amazon S3 lake into reconciled columnar datasets. When designing and implementing this pipeline, we adopted the following core guiding principles and considerations:
- Keep our tech stack simple
- Use infrastructure as code
- Work with transient resources
Keeping our tech stack simple
We aimed to keep our tech stack simple by using existing and proven AWS technologies and only adopting services that would drive substantial impact. Drop is primarily an AWS shop, so continuing to use AWS technologies made sense due to our existing experience, the ability to prototype new features quickly, and the inherent integration benefits of using other services within Amazon’s ecosystem.
Another effort to keep our tech stack simple was to limit the overhead and complexity of newly adopted open-source Apache Hadoop technologies. Our engineering team initially had limited experience working with these technologies, so we made a conscious effort to mitigate additional technical overhead to our stack by using proven fully-managed services. We integrated Amazon EMR as part of our idempotent data pipelines because we could use the service when our pipeline operations required it, which eliminated the need to maintain the service when no longer required. This allowed us to reduce the technical overhead of constantly maintaining production clusters.
Using infrastructure as code
We use Apache Airflow to manage and schedule our data lake pipeline operations. Using Airflow enables us to build our entire workflows and infrastructure as code via Airflow Directed Acyclic Graphs (DAGs). This key decision also simplified our engineering development and deployment processes, while providing version control for all aspects of our data infrastructure.
Working with transient resources
To reduce operational costs, we made a key decision to build our data processing pipelines using transient resources. By designing our pipelines to spin up EMR clusters only upon operational demand and terminate upon job completion, we can use Amazon Elastic Compute Cloud (Amazon EC2) Spot and On-Demand Instances without paying for idle resources. This approach has enabled a dramatic reduction in costs associated with idle clusters.
Batch ETL pipeline overview
The following diagram illustrates our batch ETL pipeline architecture.
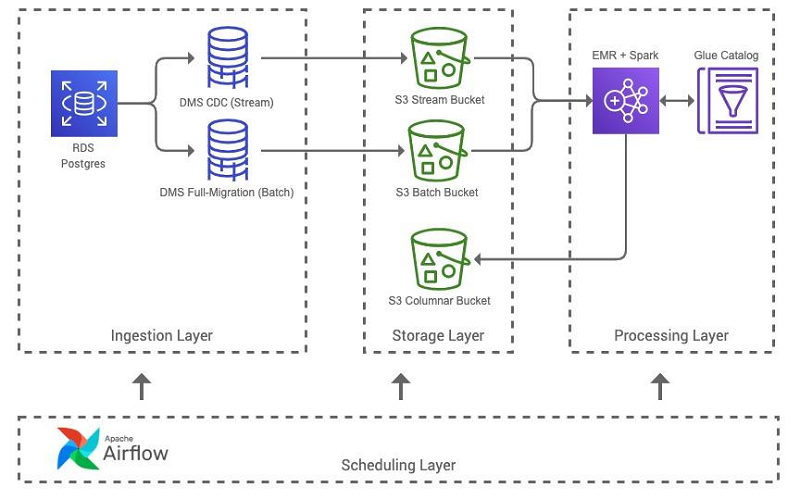
The pipeline includes the following steps:
- A core requirement for the Lambda architecture data model is to have access to both batch and stream data sources of a dataset. The batch ETL pipeline primarily ingests data in batch and stream formats from our Amazon Relational Database Service (Amazon RDS) Postgres database using AWS Database Migration Service (AWS DMS). The pipeline initiates full-migration AWS DMS tasks for comprehensive batch snapshots using Airflow, and ingests stream data using ongoing replication AWS DMS tasks for 1-minute latency change data capture (CDC) files. Data from both batch and stream formats are landed into our Amazon S3 lake, and cataloged in our AWS Glue Data Catalog using AWS Glue crawlers.
- The batch ETL pipeline Apache Airflow DAG runs a series of tasks, which begins with uploading our Lambda architecture Spark application to Amazon S3, spinning up an EMR cluster, and ultimately running the Spark application as an Amazon EMR step. Depending on the characteristics of the datasets, the necessary Amazon EMR resources are calibrated to produce the reconciled dataset. To produce the resultant datasets in Apache Parquet format, we must allocate sufficient CPU and memory to our clusters.
- Upon completion of all of the Amazon EMR steps, the cluster is terminated, and the newly produced dataset is crawled using AWS Glue crawlers to update the dataset’s metadata within the Data Catalog. The output dataset is now ready for consumer systems to access via Amazon S3 or query using Amazon Athena or Amazon Redshift Spectrum.
Evolving the EMR pipeline
Our engineering team is constantly iterating on the architecture of our batch ETL pipeline in an effort to reduce its runtime duration and operational costs. The following iterations and notable feature enhancements have generated the largest impact to the downstream systems, as well as the end-users that rely on this pipeline.
Migrating from AWS Glue to Amazon EMR
The first iteration of our batch ETL pipeline used AWS Glue to process our Spark applications rather than Amazon EMR due to our limited in-house Hadoop experience in the initial stages. AWS Glue was an appealing first solution due to its “ETL as a service” features, and simplified resource allocation. The AWS Glue solution successfully delivered desired results; however, as we gained experience with Hadoop technologies, we recognized a significant opportunity to use Amazon EMR to improve pipeline performance and reduce operational costs.
The migration from AWS Glue to Amazon EMR was seamless and only required EMR cluster configurations and minor modifications to our Spark application that used AWS Glue libraries. Thanks to this, we achieved the following operational benefits:
- Faster cluster bootstrapping and resource provisioning durations. We found that AWS Glue clusters have a cold start time of 10–12 minutes, whereas EMR clusters have a cold start time of 7–8 minutes.
- An 80% reduction in cost while using equivalent resources. We swapped the standard AWS Glue worker type at the cost of $0.44 per DPU-Hour, for the resource equivalent m5.xlarge Amazon EMR instance type, which has a Spot Instance price of approximately $0.085 per instnace per hour.
File committers
Our original partitioning strategy attempted to use Spark’s dynamic write partitioning feature to reduce the number of written files per run. See the following code:
sparkSession.conf.set(“spark.sql.sources.partitionOverwriteMode”, “dynamic”)
This strategy didn’t translate well in our pipeline’s performance; we quickly experienced the limitations and considerations of working with cloud object stores. By pivoting our Spark application’s file-writing strategy to completely overwrite an existing directory and using the Amazon EMR EMRFS S3-optimized committer, we could realize critical performance gains. In scenarios where datasets were nearly a terabyte, deployment of this optimized file committer reduced runtime from hours to less than half an hour! It’s worth noting that Amazon EMR 5.30.0 includes an optimization that should help with dynamic partitionOverwriteMode.
Upgrading Amazon EMR versions to 5.28+
Our datasets often exceed billions of rows, which necessitated the comparison and processing of hundreds of thousands of stream files against large batch files. The ability to execute these Spark operations given the input data sources comes at a high cost to query and process the data.
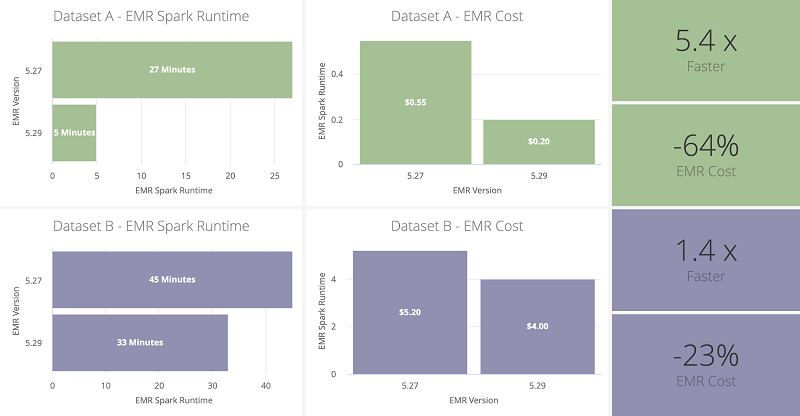
A huge improvement in our pipeline’s overall performance came from using the Amazon EMR runtime for Apache Spark feature introduced in Amazon EMR version 5.28. We saw immediate performance gains by upgrading from Amazon EMR 5.27 to 5.29, without having to make any additional changes to our existing pipeline. Our Spark application total runtime and subsequent Amazon EMR cost was reduced by over 35% using identical resource configurations. These improvements were benchmarked against two of our datasets and averaged against three production runs.
The following table summarizes the dataset and EMR cluster properties.
| Dataset | Table Rows | Total Batch Files Size | Total Stream Files Size | Count Stream Files | EC2 Instance Type | Count EC2 Instances |
| Dataset A | ~3.5M | ~0.5GB | ~0.2GB | ~100k | m5.xlarge | 10 |
| Dataset B | ~3,500M | ~500GB | ~120GB | ~250k | r5.2xlarge | 30 |
The following diagrams summarize the Amazon EMR upgrade performance benchmarks and metrics. We calculated these cost metrics with Amazon EMR bootstrapping and resource provisioning time included.
Amazon EMR step concurrency
Early iterations of our pipeline architecture involved creating a new batch ETL pipeline per dataset, as well as a dedicated EMR cluster for that dataset. Cloning new pipelines was a quick and simple way to scale our processing capabilities because our infrastructure was written as code and the operations and resources were self-contained. Although this enabled pipeline generation quickly for our most important datasets, there was ample opportunity for operational improvements.
The following screenshot shows Drop’s batch ETL processing DAG. All of the clusters are named after the Drop engineering team’s pets.
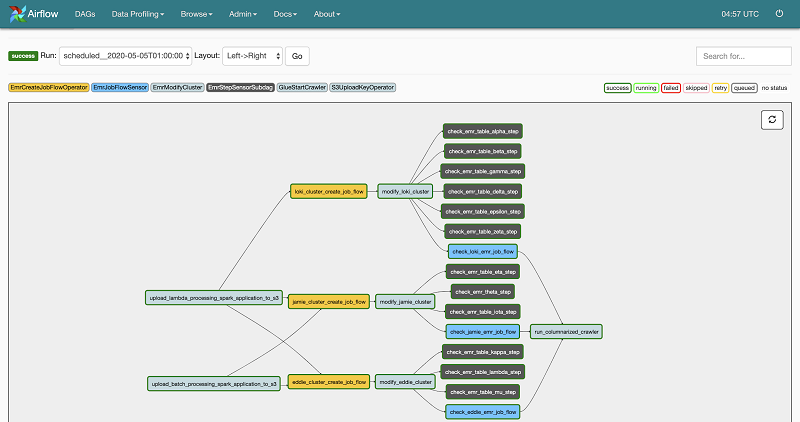
The evolution of the pipeline architecture involved grouping datasets based on its Amazon EMR resource requirements and running them as Spark application Amazon EMR steps in a common EMR cluster concurrently using Amazon EMR step concurrency. Re-architecting our batch ETL pipelines in this manner allowed us to do the following:
- Remove the EMR cluster bootstrapping and provisioning duration associated within individual EMR clusters per dataset
- Reduce overall Spark runtimes in aggregate
- Simplify our Amazon EMR resource configurations with fewer EMR clusters
On average, our clusters required 8–10 minutes to bootstrap and source the Spot Instances requested. By migrating multiple Spark applications to a common EMR cluster, we removed this bottleneck, and ultimately reduced overall runtime and Amazon EMR costs. Amazon EMR step concurrency also allowed us to run multiple applications at the same time against a dramatically reduced set of resources. For our smaller datasets (under 15 million rows), we learned that running Spark applications concurrently with reduced resources didn’t have a linear effect on overall runtime, and we could achieve shorter runtimes with fewer resources compared to the previous architecture in aggregate. However, our larger datasets (over 1 billion rows) didn’t exhibit the same performance behaviors or gains as the smaller tables when running Amazon EMR steps concurrently. Therefore, EMR clusters for larger tables required additional resources and fewer steps; however, the overall result is still marginally better in terms of cost and overall runtime in aggregate compared to the previous architecture.
Amazon EMR instance fleets
Working with Amazon EMR and Amazon EC2 Spot Instances has allowed us to realize tremendous cost savings, but it can come at the expense of EMR cluster reliability. We have experienced Spot Instance availability issues due to Spot Instance type supply constraints. This directly contributes to overall pipeline performance degradation in the form of longer EMR cluster resource provisioning and longer Spark runtimes, due to lost nodes.
To improve our pipeline reliability and protect against these risks, we began to use Amazon EMR instance fleets. Instance fleets addressed both pain points—they limited supply of a specific EC2 Spot Instance type by sourcing an alternative Amazon EMR instance type, and the ability to automatically switch to On-Demand Instances if provisioning Spot Instances exceeds a specified threshold duration. Prior to using instance fleets, about 15% of our Amazon EMR production runs were affected by limitations related to Spot Instances capacity availability, due to the limited ability to diversify instance types in Uniform Groups, which can be done in Instance Fleets. Since implementing instance fleets, we haven’t had a cluster fail or experienced prolonged resource provisioning past programmed thresholds.
Conclusion
Amazon EMR has played a critical role in Drop’s ability to use data to make better-informed product and business decisions. We have had tremendous success in capitalizing Amazon EMR features to improve our data processing pipeline’s overall performance and cost efficiency, and will continue to explore new ways to constantly improve our pipeline. One of the easiest ways to learn about these new opportunities to improve our systems is to stay current with the latest AWS technologies and Amazon EMR features.
About the Authors
 Michael Chau is a Software Engineer at Drop. He has experience moving data from A to B and sometimes transforming it along the way.
Michael Chau is a Software Engineer at Drop. He has experience moving data from A to B and sometimes transforming it along the way.
 Leonardo Gómez is a Big Data Specialist Solutions Architect at AWS. Based in Toronto, Canada, He works with customers across Canada to design and build big data architectures.
Leonardo Gómez is a Big Data Specialist Solutions Architect at AWS. Based in Toronto, Canada, He works with customers across Canada to design and build big data architectures.