AWS Big Data Blog
Tag: Apache Spark

Secure Apache Spark writes to Amazon S3 on Amazon EMR with dynamic AWS KMS encryption
When processing data at scale, many organizations use Apache Spark on Amazon EMR to run shared clusters that handle workloads across tenants, business units, or classification levels. In such multi-tenant environments, different datasets often require distinct AWS Key Management Service (AWS KMS) keys to enforce strict access controls and meet compliance requirements. At the same […]

Modernize Apache Spark workflows using Spark Connect on Amazon EMR on Amazon EC2
In this post, we demonstrate how to implement Apache Spark Connect on Amazon EMR on Amazon Elastic Compute Cloud (Amazon EC2) to build decoupled data processing applications. We show how to set up and configure Spark Connect securely, so you can develop and test Spark applications locally while executing them on remote Amazon EMR clusters.

Deploy Apache YuniKorn batch scheduler for Amazon EMR on EKS
This post explores Kubernetes scheduling fundamentals, examines the limitations of the default kube-scheduler for batch workloads, and demonstrates how YuniKorn addresses these challenges. We discuss how to deploy YuniKorn as a custom scheduler for Amazon EMR on EKS, its integration with job submissions, how to configure queues and placement rules, and how to establish resource quotas. We also show these features in action through practical Spark job examples.

Centralize Apache Spark observability on Amazon EMR on EKS with external Spark History Server
This post demonstrates how to centralize Apache Spark observability using SHS on EMR on EKS. We showcase how to enhance SHS with performance monitoring tools, with a pattern applicable to many monitoring solutions such as SparkMeasure and DataFlint.

Use Batch Processing Gateway to automate job management in multi-cluster Amazon EMR on EKS environments
AWS customers often process petabytes of data using Amazon EMR on EKS. In enterprise environments with diverse workloads or varying operational requirements, customers frequently choose a multi-cluster setup due to the following advantages: Better resiliency and no single point of failure – If one cluster fails, other clusters can continue processing critical workloads, maintaining business […]

Detect and handle data skew on AWS Glue
October 2024: This post was reviewed and updated for accuracy. AWS Glue is a fully managed, serverless data integration service provided by Amazon Web Services (AWS) that uses Apache Spark as one of its backend processing engines (as of this writing, you can use Python Shell or Spark). Data skew occurs when the data being […]

Introducing Amazon EMR on EKS job submission with Spark Operator and spark-submit
Amazon EMR on EKS provides a deployment option for Amazon EMR that allows organizations to run open-source big data frameworks on Amazon Elastic Kubernetes Service (Amazon EKS). With EMR on EKS, Spark applications run on the Amazon EMR runtime for Apache Spark. This performance-optimized runtime offered by Amazon EMR makes your Spark jobs run fast […]

Run Apache Spark workloads 3.5 times faster with Amazon EMR 6.9
In this post, we analyze the results from our benchmark tests running a TPC-DS application on open-source Apache Spark and then on Amazon EMR 6.9, which comes with an optimized Spark runtime that is compatible with open-source Spark. We walk through a detailed cost analysis and finally provide step-by-step instructions to run the benchmark. With Amazon EMR 6.9.0, you can now run your Apache Spark 3.x applications faster and at lower cost without requiring any changes to your applications. In our performance benchmark tests, derived from TPC-DS performance tests at 3 TB scale, we found the EMR runtime for Apache Spark 3.3.0 provides a 3.5 times (using total runtime) performance improvement on average over open-source Apache Spark 3.3.0.

Design considerations for Amazon EMR on EKS in a multi-tenant Amazon EKS environment
Many AWS customers use Amazon Elastic Kubernetes Service (Amazon EKS) in order to take advantage of Kubernetes without the burden of managing the Kubernetes control plane. With Kubernetes, you can centrally manage your workloads and offer administrators a multi-tenant environment where they can create, update, scale, and secure workloads using a single API. Kubernetes also […]
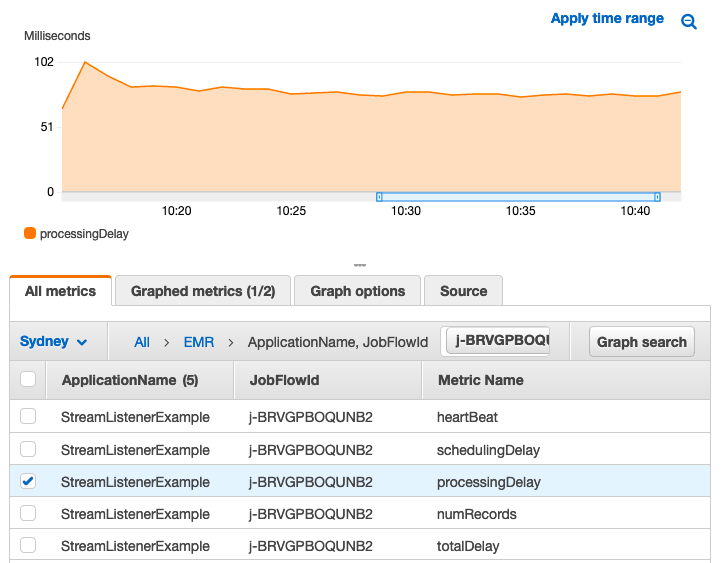
Monitor Spark streaming applications on Amazon EMR
This post demonstrates how to implement a simple SparkListener, monitor and observe Spark streaming applications, and set up some alerts. The post also shows how to use alerts to set up automatic scaling on Amazon EMR clusters, based on your CloudWatch custom metrics.