AWS Big Data Blog
Amazon Redshift Spectrum Extends Data Warehousing Out to Exabytes—No Loading Required
When we first looked into the possibility of building a cloud-based data warehouse many years ago, we were struck by the fact that our customers were storing ever-increasing amounts of data, and yet only a small fraction of that data ever made it into a data warehouse or Hadoop system for analysis. We saw that this wasn’t just a cloud-specific anomaly. It was also true in the broader industry, where the growth rate of the enterprise storage market segment greatly surpassed that of the data warehousing market segment.
We dubbed this the “dark data” problem. Our customers knew that there was untapped value in the data they collected; why else would they spend money to store it? But the systems available to them to analyze this data were simply too slow, complex, and expensive for them to use on all but a select subset of this data. They were storing it with optimistic hope that, someday, someone would find a solution.
Amazon Redshift became one of the fastest-growing AWS services because it helped solve the dark data problem. It was at least an order of magnitude less expensive and faster than most alternatives available. And Amazon Redshift was fully managed from the start—you didn’t have to worry about capacity, provisioning, patching, monitoring, backups, and a host of other DBA headaches. Many customers, including Vevo, Yelp, Redfin, and Edmunds, migrated to Amazon Redshift to improve query performance, reduce DBA overhead, and lower the cost of analytics.
And our customers’ data continues to grow at a very fast rate. Across the board, gigabytes to petabytes, the average Amazon Redshift customer doubles the data analyzed every year. That’s why we implement features that help customers handle their growing data, for example to double the query throughput or improve the compression ratios from 3x to 4x. That gives our customers some time before they have to consider throwing away data or removing it from their analytic environments. However, there is an increasing number of AWS customers who each generate a petabyte of data every day—that’s an exabyte in only three years. There wasn’t a solution for customers like that. If your data is doubling every year, it’s not long before you have to find new, disruptive approaches that transform the cost, performance, and simplicity curves for managing data.
Let’s look at the options available today. You can use Hadoop-based technologies like Apache Hive with Amazon EMR. This is actually a pretty great solution because it makes it easy and cost-effective to operate directly on data in Amazon S3 without ingestion or transformation. You can spin up clusters as you wish when you need, and size them right for that specific job you’re running. These systems are great at high scale-out processing like scans, filters, and aggregates. On the other hand, they’re not that good at complex query processing. For example, join processing requires data to be shuffled across nodes—for a large amount of data and large numbers of nodes that gets very slow. And joins are intrinsic to any meaningful analytics problem.
You can also use a columnar MPP data warehouse like Amazon Redshift. These systems make it simple to run complex analytic queries with orders of magnitude faster performance for joins and aggregations performed over large datasets. Amazon Redshift, in particular, leverages high-performance local disks, sophisticated query execution. and join-optimized data formats. Because it is just standard SQL, you can keep using your existing ETL and BI tools. But you do have to load data, and you have to provision clusters against the storage and CPU requirements you need.
Both solutions have powerful attributes, but they force you to choose which attributes you want. We see this as a “tyranny of OR.” You can have the throughput of local disks OR the scale of Amazon S3. You can have sophisticated query optimization OR high-scale data processing. You can have fast join performance with optimized formats OR a range of data processing engines that work against common data formats. But you shouldn’t have to choose. At this scale, you really can’t afford to choose. You need “all of the above.”
Redshift Spectrum
We built Redshift Spectrum to end this “tyranny of OR.” With Redshift Spectrum, Amazon Redshift customers can easily query their data in Amazon S3. Like Amazon EMR, you get the benefits of open data formats and inexpensive storage, and you can scale out to thousands of nodes to pull data, filter, project, aggregate, group, and sort. Like Amazon Athena, Redshift Spectrum is serverless and there’s nothing to provision or manage. You just pay for the resources you consume for the duration of your Redshift Spectrum query. Like Amazon Redshift itself, you get the benefits of a sophisticated query optimizer, fast access to data on local disks, and standard SQL. And like nothing else, Redshift Spectrum can execute highly sophisticated queries against an exabyte of data or more—in just minutes.
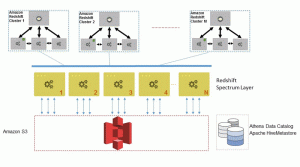
Redshift Spectrum is a built-in feature of Amazon Redshift, and your existing queries and BI tools will continue to work seamlessly. Under the covers, we manage a fleet of thousands of Redshift Spectrum nodes spread across multiple Availability Zones. These are transparently scaled and allocated to your queries based on the data that you need to process, with no provisioning or commitments. Redshift Spectrum is also highly concurrent—you can access your Amazon S3 data from any number of Amazon Redshift clusters.
The life of a Redshift Spectrum query
It all starts when Redshift Spectrum queries are submitted to the leader node of your Amazon Redshift cluster. The leader node optimizes, compiles, and pushes the query execution to the compute nodes in your Amazon Redshift cluster. Next, the compute nodes obtain the information describing the external tables from your data catalog, dynamically pruning nonrelevant partitions based on the filters and joins in your queries. The compute nodes also examine the data available locally and push down predicates to efficiently scan only the relevant objects in Amazon S3.
The Amazon Redshift compute nodes then generate multiple requests depending on the number of objects that need to be processed, and submit them concurrently to Redshift Spectrum, which pools thousands of Amazon EC2 instances per AWS Region. The Redshift Spectrum worker nodes scan, filter, and aggregate your data from Amazon S3, streaming required data for processing back to your Amazon Redshift cluster. Then, the final join and merge operations are performed locally in your cluster and the results are returned to your client.

Redshift Spectrum’s architecture offers several advantages. First, it elastically scales compute resources separately from the storage layer in Amazon S3. Second, it offers significantly higher concurrency because you can run multiple Amazon Redshift clusters and query the same data in Amazon S3. Third, Redshift Spectrum leverages the Amazon Redshift query optimizer to generate efficient query plans, even for complex queries with multi-table joins and window functions. Fourth, it operates directly on your source data in its native format (Parquet, RCFile, CSV, TSV, Sequence, Avro, RegexSerDe and more to come soon). This means that no data loading or transformation is needed. This also eliminates data duplication and associated costs. Fifth, operating on open data formats gives you the flexibility to leverage other AWS services and execution engines across your various teams to collaborate on the same data in Amazon S3. You get all of this, and because Redshift Spectrum is a feature of Amazon Redshift, you get the same level of end-to-end security, compliance, and certifications as with Amazon Redshift.
Designed for performance and cost-effectiveness
With Amazon Redshift Spectrum, you pay only for the queries you run against the data that you actually scan. We encourage you to leverage file partitioning, columnar data formats, and data compression to significantly minimize the amount of data scanned in Amazon S3. This is important for data warehousing because it dramatically improves query performance and reduces cost. Partitioning your data in Amazon S3 by date, time, or any other custom keys enables Redshift Spectrum to dynamically prune nonrelevant partitions to minimize the amount of data processed. If you store data in a columnar format, such as Parquet, Redshift Spectrum scans only the columns needed by your query, rather than processing entire rows. Similarly, if you compress your data using one of Redshift Spectrum’s supported compression algorithms, less data is scanned.
Amazon Redshift and Redshift Spectrum give you the best of both worlds. If you need to run frequent queries on the same data, you can normalize it, store it in Amazon Redshift, and get all of the benefits of a fully featured data warehouse for storing and querying structured data at a flat rate. At the same time, you can keep your additional data in multiple open file formats in Amazon S3, whether it is historical data or the most recent data, and extend your Amazon Redshift queries across your Amazon S3 data lake.
And that is how Amazon Redshift Spectrum scales data warehousing to exabytes—with no loading required. Redshift Spectrum ends the “tyranny of OR,” enabling you to store your data where you want, in the format you want, and have it available for fast processing using standard SQL when you need it, now and in the future.
Additional Reading
10 Best Practices for Amazon Redshift Spectrum
Amazon QuickSight Adds Support for Amazon Redshift Spectrum
Amazon Redshift Spectrum – Exabyte-Scale In-Place Queries of S3 Data
About the Author
 Maor Kleider is a Senior Product Manager for Amazon Redshift, a fast, simple and cost-effective data warehouse. Maor is passionate about collaborating with customers and partners, learning about their unique big data use cases and making their experience even better. In his spare time, Maor enjoys traveling and exploring new restaurants with his family.
Maor Kleider is a Senior Product Manager for Amazon Redshift, a fast, simple and cost-effective data warehouse. Maor is passionate about collaborating with customers and partners, learning about their unique big data use cases and making their experience even better. In his spare time, Maor enjoys traveling and exploring new restaurants with his family.