AWS Big Data Blog
Tag: Data Lake

Improve DynamoDB analytics with AWS Glue zero-ETL schema and partition controls
In this post, you learn how to replicate Amazon DynamoDB data to Apache Iceberg tables in Amazon S3 through a zero-ETL integration. We walk through the challenges that the DynamoDB nested, schema-flexible data model introduces for analytics workloads, and show you how to configure schema unnesting and data partitioning for a sample product catalog table. We also cover how to query the replicated data in Amazon Athena using standard SQL.

Building a scalable, transactional data lake using dbt, Amazon EMR, and Apache Iceberg
Growing data volume, variety, and velocity has made it crucial for businesses to implement architectures that efficiently manage and analyze data, while maintaining data integrity and consistency. In this post, we show you a solution that combines Apache Iceberg, Data Build Tool (dbt), and Amazon EMR to create a scalable, ACID-compliant transactional data lake. You can use this data lake to process transactions and analyze data simultaneously while maintaining data accuracy and real-time insights for better decision-making.
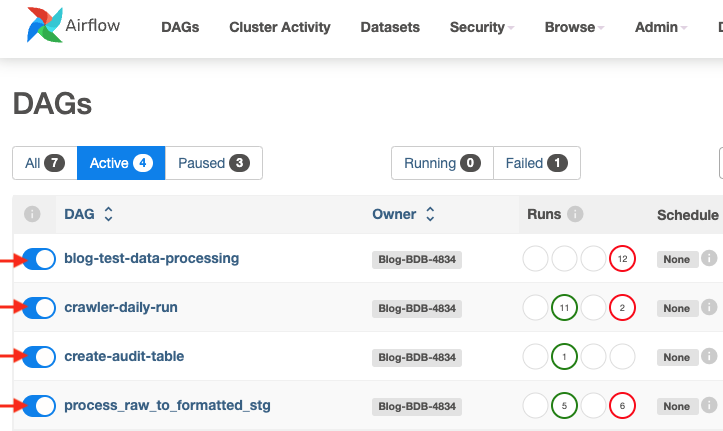
Building scalable AWS Lake Formation governed data lakes with dbt and Amazon Managed Workflows for Apache Airflow
Organizations often struggle with building scalable and maintainable data lakes—especially when handling complex data transformations, enforcing data quality, and monitoring compliance with established governance. Traditional approaches typically involve custom scripts and disparate tools, which can increase operational overhead and complicate access control. A scalable, integrated approach is needed to simplify these processes, improve data reliability, […]

Modernize your legacy databases with AWS data lakes, Part 2: Build a data lake using AWS DMS data on Apache Iceberg
This is part two of a three-part series where we show how to build a data lake on AWS using a modern data architecture. This post shows how to load data from a legacy database (SQL Server) into a transactional data lake (Apache Iceberg) using AWS Glue. We show how to build data pipelines using AWS Glue jobs, optimize them for both cost and performance, and implement schema evolution to automate manual tasks. To review the first part of the series, where we load SQL Server data into Amazon Simple Storage Service (Amazon S3) using AWS Database Migration Service (AWS DMS), see Modernize your legacy databases with AWS data lakes, Part 1: Migrate SQL Server using AWS DMS.

Unleash deeper insights with Amazon Redshift data sharing for data lake tables
Amazon Redshift now enables the secure sharing of data lake tables—also known as external tables or Amazon Redshift Spectrum tables—that are managed in the AWS Glue Data Catalog, as well as Redshift views referencing those data lake tables. By using granular access controls, data sharing in Amazon Redshift helps data owners maintain tight governance over who can access the shared information. In this post, we explore powerful use cases that demonstrate how you can enhance cross-team and cross-organizational collaboration, reduce overhead, and unlock new insights by using this innovative data sharing functionality.

Accelerate Amazon Redshift Data Lake queries with AWS Glue Data Catalog Column Statistics
Over the last year, Amazon Redshift added several performance optimizations for data lake queries across multiple areas of query engine such as rewrite, planning, scan execution and consuming AWS Glue Data Catalog column statistics. In this post, we highlight the performance improvements we observed using industry standard TPC-DS benchmarks. Overall execution time of TPC-DS 3 TB benchmark improved by 3x. Some of the queries in our benchmark experienced up to 12x speed up.

Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. Managing projects with Jira leads to rich datasets, which can provide historical and predictive insights about project and development efforts. Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other […]

Build a semantic search engine for tabular columns with Transformers and Amazon OpenSearch Service
Finding similar columns in a data lake has important applications in data cleaning and annotation, schema matching, data discovery, and analytics across multiple data sources. The inability to accurately find and analyze data from disparate sources represents a potential efficiency killer for everyone from data scientists, medical researchers, academics, to financial and government analysts. Conventional […]

Automate replication of relational sources into a transactional data lake with Apache Iceberg and AWS Glue
Organizations have chosen to build data lakes on top of Amazon Simple Storage Service (Amazon S3) for many years. A data lake is the most popular choice for organizations to store all their organizational data generated by different teams, across business domains, from all different formats, and even over history. According to a study, the […]

How BookMyShow saved 80% in costs by migrating to an AWS modern data architecture
This is a guest post co-authored by Mahesh Vandi Chalil, Chief Technology Officer of BookMyShow. BookMyShow (BMS), a leading entertainment company in India, provides an online ticketing platform for movies, plays, concerts, and sporting events. Selling up to 200 million tickets on an annual run rate basis (pre-COVID) to customers in India, Sri Lanka, Singapore, […]