AWS Big Data Blog
Category: AWS Glue DataBrew

Detect, mask, and redact PII data using AWS Glue before loading into Amazon OpenSearch Service
Many organizations, small and large, are working to migrate and modernize their analytics workloads on Amazon Web Services (AWS). There are many reasons for customers to migrate to AWS, but one of the main reasons is the ability to use fully managed services rather than spending time maintaining infrastructure, patching, monitoring, backups, and more. Leadership […]

Clean up your Excel and CSV files without writing code using AWS Glue DataBrew
Managing data within an organization is complex. Handling data from outside the organization adds even more complexity. As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. In this blog post, we’ll explore a […]

Empower your Jira data in a data lake with Amazon AppFlow and AWS Glue
In the world of software engineering and development, organizations use project management tools like Atlassian Jira Cloud. Managing projects with Jira leads to rich datasets, which can provide historical and predictive insights about project and development efforts. Although Jira Cloud provides reporting capability, loading this data into a data lake will facilitate enrichment with other […]

Use AWS Glue DataBrew recipes in your AWS Glue Studio visual ETL jobs
AWS Glue Studio is now integrated with AWS Glue DataBrew. AWS Glue Studio is a graphical interface that makes it easy to create, run, and monitor extract, transform, and load (ETL) jobs in AWS Glue. DataBrew is a visual data preparation tool that enables you to clean and normalize data without writing any code. The […]

Simplify semi-structured nested JSON data analysis with AWS Glue DataBrew and Amazon QuickSight
As the industry grows with more data volume, big data analytics is becoming a common requirement in data analytics and machine learning (ML) use cases. Data comes from many different sources in structured, semi-structured, and unstructured formats. For semi-structured data, one of the most common lightweight file formats is JSON. However, due to the complex […]

Create single output files for recipe jobs using AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. AWS Glue DataBrew offers over 350 pre-built transformations to automate data preparation tasks (such as filtering anomalies, standardizing formats, and correcting invalid values) that would otherwise require days or weeks writing hand-coded transformations. You can now choose single or multiple output files instead of autogenerated files for […]

A serverless operational data lake for retail with AWS Glue, Amazon Kinesis Data Streams, Amazon DynamoDB, and Amazon QuickSight
Do you want to reduce stockouts at stores? Do you want to improve order delivery timelines? Do you want to provide your customers with accurate product availability, down to the millisecond? A retail operational data lake can help you transform the customer experience by providing deeper insights into a variety of operational aspects of your […]
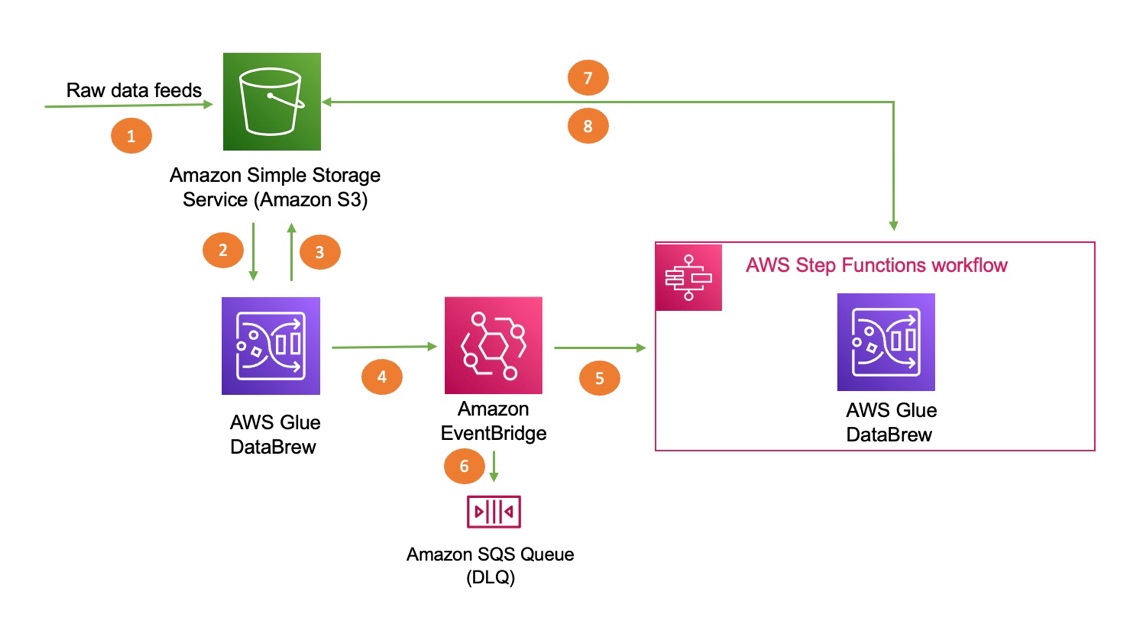
Trigger an AWS Glue DataBrew job based on an event generated from another DataBrew job
Organizations today have continuous incoming data, and analyzing this data in a timely fashion is becoming a common requirement for data analytics and machine learning (ML) use cases. As part of this, you need clean data in order to gain insights that can enable enterprises to get the most out of their data for business […]

Write prepared data directly into JDBC-supported destinations using AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. AWS Glue DataBrew offers over 250 pre-built transformations to automate data preparation tasks (such as filtering anomalies, standardizing formats, and correcting invalid values) that would otherwise require days or weeks writing hand-coded transformations. You can now write cleaned and normalized data directly into JDBC-supported databases and data […]

Build a data pipeline to automatically discover and mask PII data with AWS Glue DataBrew
Personally identifiable information (PII) data handling is a common requirement when operating a data lake at scale. Businesses often need to mitigate the risk of exposing PII data to the data science team while not hindering the productivity of the team to get to the data they need in order to generate valuable data insights. […]