AWS Big Data Blog
Category: AWS Glue DataBrew

Build event-driven data quality pipelines with AWS Glue DataBrew
Businesses collect more and more data every day to drive processes like decision-making, reporting, and machine learning (ML). Before cleaning and transforming your data, you need to determine whether it’s fit for use. Incorrect, missing, or malformed data can have large impacts on downstream analytics and ML processes. Performing data quality checks helps identify issues […]
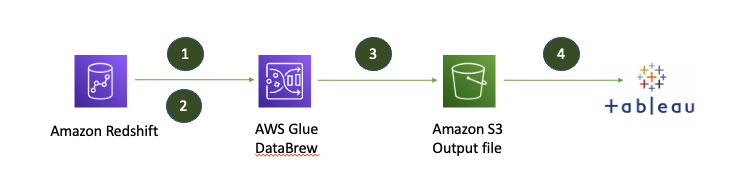
Transform data and create dashboards using AWS Glue DataBrew and Tableau
Before you can create visuals and dashboards that convey useful information, you need to transform and prepare the underlying data. With AWS Glue DataBrew, you can now easily transform and prepare datasets from Amazon Simple Storage Service (Amazon S3), an Amazon Redshift data warehouse, Amazon Aurora, and other Amazon Relational Database Service (Amazon RDS) databases […]

Enrich datasets for descriptive analytics with AWS Glue DataBrew
Data analytics remains a constantly hot topic. More and more businesses are beginning to understand the potential their data has to allow them to serve customers more effectively and give them a competitive advantage. However, for many small to medium businesses, gaining insight from their data can be challenging because they often lack in-house data […]

Simplify Snowflake data loading and processing with AWS Glue DataBrew
May 2024: Connecting to Snowflake as a data source is now supported natively. To learn more, visit our documentation. Historically, inserting and retrieving data from a given database platform has been easier compared to a multi-platform architecture for the same operations. To simplify bringing data in from a multi-database platform, AWS Glue DataBrew supports bringing […]

Enforce customized data quality rules in AWS Glue DataBrew
GIGO (garbage in, garbage out) is a concept common to computer science and mathematics: the quality of the output is determined by the quality of the input. In modern data architecture, you bring data from different data sources, which creates challenges around volume, velocity, and veracity. You might write unit tests for applications, but it’s […]
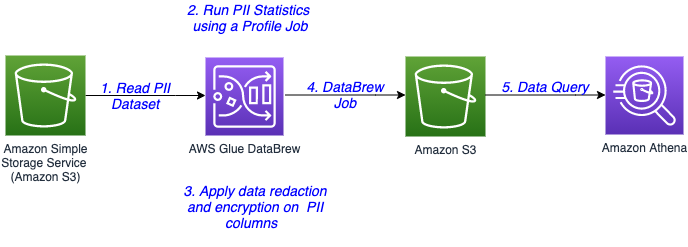
Introducing PII data identification and handling using AWS Glue DataBrew
AWS Glue DataBrew, a visual data preparation tool, now allows users to identify and handle sensitive data by applying advanced transformations like redaction, replacement, encryption, and decryption on their personally identifiable information (PII) data, and other types of data they deem sensitive. With exponential growth of data, companies are handling huge volumes and a wide […]

Integrate AWS Glue DataBrew and Amazon PinPoint to launch marketing campaigns
Marketing teams often rely on data engineers to provide a consumer dataset that they can use to launch marketing campaigns. This can sometimes cause delays in launching campaigns and consume data engineers’ bandwidth. The campaigns are often launched using complex solutions that are either code heavy or using licensed tools. The processes of both extract, […]

Extract, prepare, and analyze Salesforce.com data using Amazon AppFlow, AWS Glue DataBrew, and Amazon Athena
As organizations embark on their data modernization journey, big data analytics and machine learning (ML) use cases are becoming even more integral parts of business. The ease for data preparation and seamless integration with third-party data sources is of paramount importance in order to gain insights quickly and make critical business decisions faster. AWS Glue […]

Prepare, transform, and orchestrate your data using AWS Glue DataBrew, AWS Glue ETL, and AWS Step Functions
Data volumes in organizations are increasing at an unprecedented rate, exploding from terabytes to petabytes and in some cases exabytes. As data volume increases, it attracts more and more users and applications to use the data in many different ways—sometime referred to as data gravity. As data gravity increases, we need to find tools and […]

Centralize feature engineering with AWS Step Functions and AWS Glue DataBrew
One of the key phases of a machine learning (ML) workflow is data preprocessing, which involves cleaning, exploring, and transforming the data. AWS Glue DataBrew, announced in AWS re:Invent 2020, is a visual data preparation tool that enables you to develop common data preparation steps without having to write any code or installation. In this […]