AWS Big Data Blog
Build event-driven data quality pipelines with AWS Glue DataBrew
Businesses collect more and more data every day to drive processes like decision-making, reporting, and machine learning (ML). Before cleaning and transforming your data, you need to determine whether it’s fit for use. Incorrect, missing, or malformed data can have large impacts on downstream analytics and ML processes. Performing data quality checks helps identify issues earlier in your workflow so you can resolve them faster. Additionally, doing these checks using an event-based architecture helps you reduce manual touchpoints and scale with growing amounts of data.
AWS Glue DataBrew is a visual data preparation tool that makes it easy to find data quality statistics such as duplicate values, missing values, and outliers in your data. You can also set up data quality rules in DataBrew to perform conditional checks based on your unique business needs. For example, a manufacturer might need to ensure that there are no duplicate values specifically in a Part ID column, or a healthcare provider might check that values in an SSN column are a certain length. After you create and validate these rules with DataBrew, you can use Amazon EventBridge, AWS Step Functions, AWS Lambda, and Amazon Simple Notification Service (Amazon SNS) to create an automated workflow and send a notification when a rule fails a validation check.
In this post, we walk you through the end-to-end workflow and how to implement this solution. This post includes a step-by-step tutorial, an AWS Serverless Application Model (AWS SAM) template, and example code that you can use to deploy the application in your own AWS environment.
Solution overview
The solution in this post combines serverless AWS services to build a completely automated, end-to-end event-driven pipeline for data quality validation. The following diagram illustrates our solution architecture.
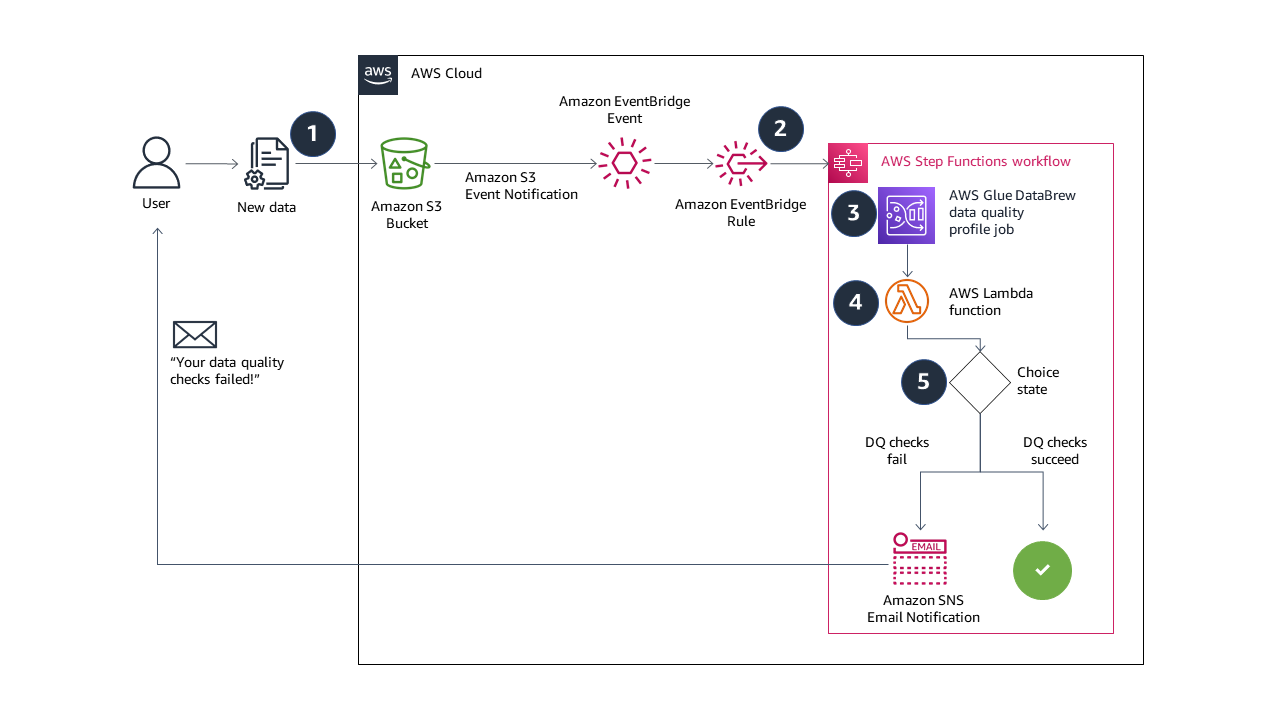
The solution workflow contains the following steps:
- When you upload new data to your Amazon Simple Storage Service (Amazon S3) bucket, events are sent to EventBridge.
- An EventBridge rule triggers a Step Functions state machine to run.
- The state machine starts a DataBrew profile job, configured with a data quality ruleset and rules. If you’re considering building a similar solution, the DataBrew profile job output location and the source data S3 buckets should be unique. This prevents recursive job runs. We deploy our resources with an AWS CloudFormation template, which creates unique S3 buckets.
- A Lambda function reads the data quality results from Amazon S3, and returns a Boolean response into the state machine. The function returns
falseif one or more rules in the ruleset fail, and returnstrueif all rules succeed. - If the Boolean response is
false, the state machine sends an email notification with Amazon SNS and the state machine ends in afailedstatus. If the Boolean response istrue, the state machine ends in asucceedstatus. You can also extend the solution in this step to run other tasks on success or failure. For example, if all the rules succeed, you can send an EventBridge message to trigger another transformation job in DataBrew.
In this post, you use AWS CloudFormation to deploy a fully functioning demo of the event-driven data quality validation solution. You test the solution by uploading a valid comma-separated values (CSV) file to Amazon S3, followed by an invalid CSV file.
The steps are as follows:
- Launch a CloudFormation stack to deploy the solution resources.
- Test the solution:
- Upload a valid CSV file to Amazon S3 and observe the data quality validation and Step Functions state machine succeed.
- Upload an invalid CSV file to Amazon S3 and observe the data quality validation and Step Functions state machine fail, and receive an email notification from Amazon SNS.
All the sample code can be found in the GitHub repository.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account.
- The AWS Command Line Interface (AWS CLI) installed and configured. Follow the instructions for your operating system.
Deploy the solution resources using AWS CloudFormation
You use a CloudFormation stack to deploy the resources needed for the event-driven data quality validation solution. The stack includes an example dataset and ruleset in DataBrew.
- Sign in to your AWS account and then choose Launch Stack:

- On the Quick create stack page, for EmailAddress, enter a valid email address for Amazon SNS email notifications.
- Leave the remaining options set to the defaults.
- Select the acknowledgement check boxes.
- Choose Create stack.

The CloudFormation stack takes about 5 minutes to reach CREATE_COMPLETE status.
- Check the inbox of the email address you provided and accept the SNS subscription.
You need to review and accept the subscription confirmation in order to demonstrate the email notification feature at the end of the walkthrough.
On the Outputs tab of the stack, you can find the URLs to browse the DataBrew and Step Functions resources that the template created. Also note the completed AWS CLI commands you use in later steps.

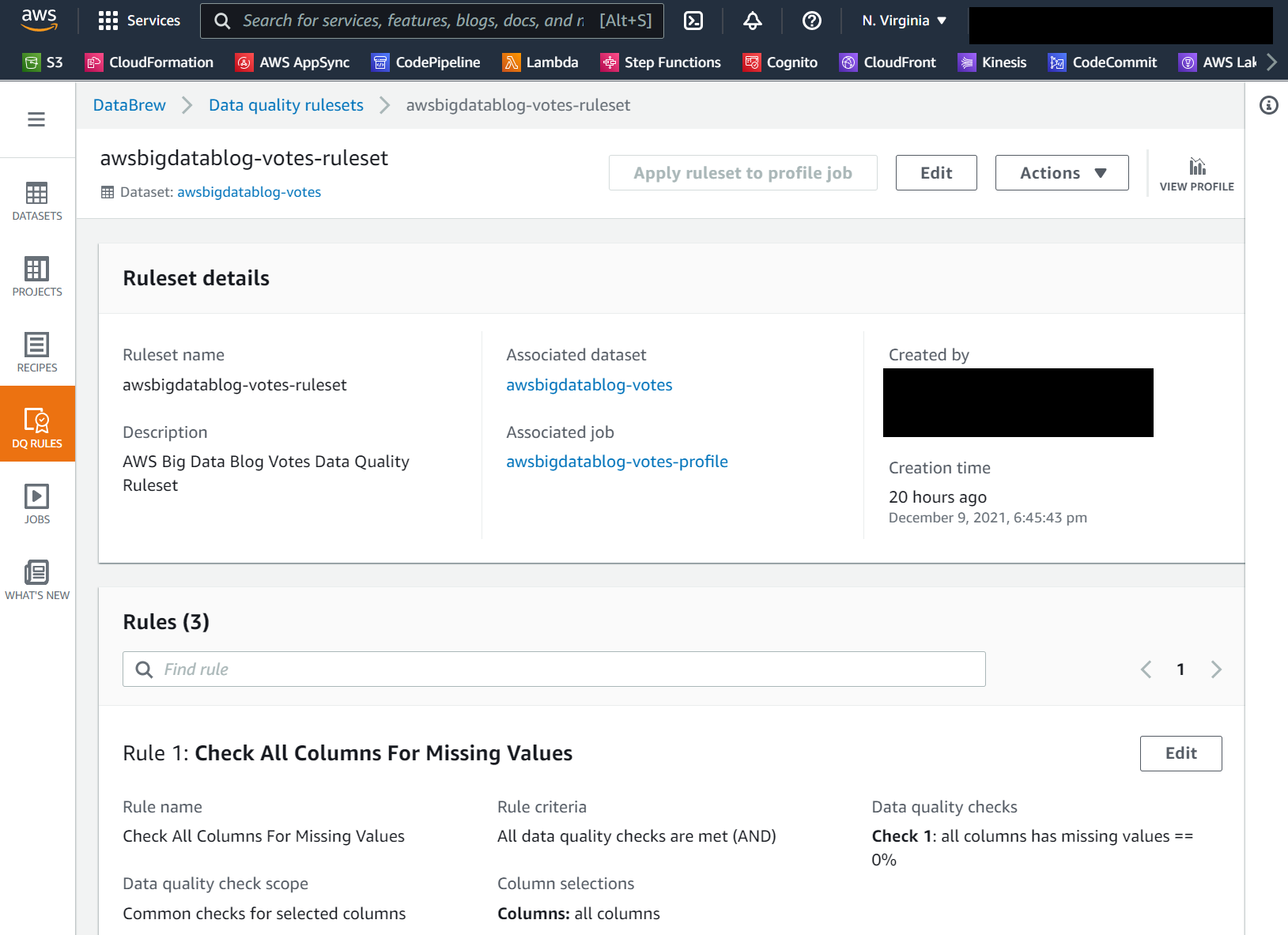
If you choose the AWSGlueDataBrewRuleset value link, you should see the ruleset details page, as in the following screenshot. In this walkthrough, we create a data quality ruleset with three rules that check for missing values, outliers, and string length.
Test the solution
In the following steps, you use the AWS CLI to upload correct and incorrect versions of the CSV file to test the event-driven data quality validation solution.
- Open a terminal or command line prompt and use the AWS CLI to download sample data. Use the command from the CloudFormation stack output with the key name
CommandToDownloadTestData: - Use the AWS CLI again to upload the unchanged CSV file to your S3 bucket. Replace the string <your_bucket> with your bucket name, or copy and paste the command provided to you from the CloudFormation template output:
- On the Step Functions console, locate the state machine created by the CloudFormation template.
You can find a URL in the CloudFormation outputs noted earlier.
- On the Executions tab, you should see a new run of the state machine.
- Choose the run’s URL to view the state machine graph and monitor its progress.

The following image shows the workflow of our state machine.

To demonstrate a data quality rule’s failure, you make at least one edit to the votes.csv file.
- Open the file in your preferred text editor or spreadsheet tool, and delete just one cell.
In the following screenshots, I use the GNU nano editor on Linux. You can also use a spreadsheet editor to delete a cell. This causes the “Check All Columns For Missing Values” rule to fail.
The following screenshot shows the CSV file before modification.
The following screenshot shows the changed CSV file.
- Save the edited
votes.csvfile and return to your command prompt or terminal. - Use the AWS CLI to upload the file to your S3 bucket one more time. You use the same command as before:
- On the Step Functions console, navigate to the latest state machine run to monitor it.
The data quality validation fails, triggering an SNS email notification and the failure of the overall state machine’s run.
The following image shows the workflow of the failed state machine.

The following screenshot shows an example of the SNS email.
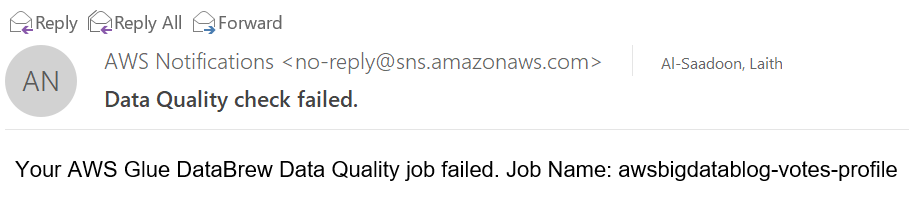
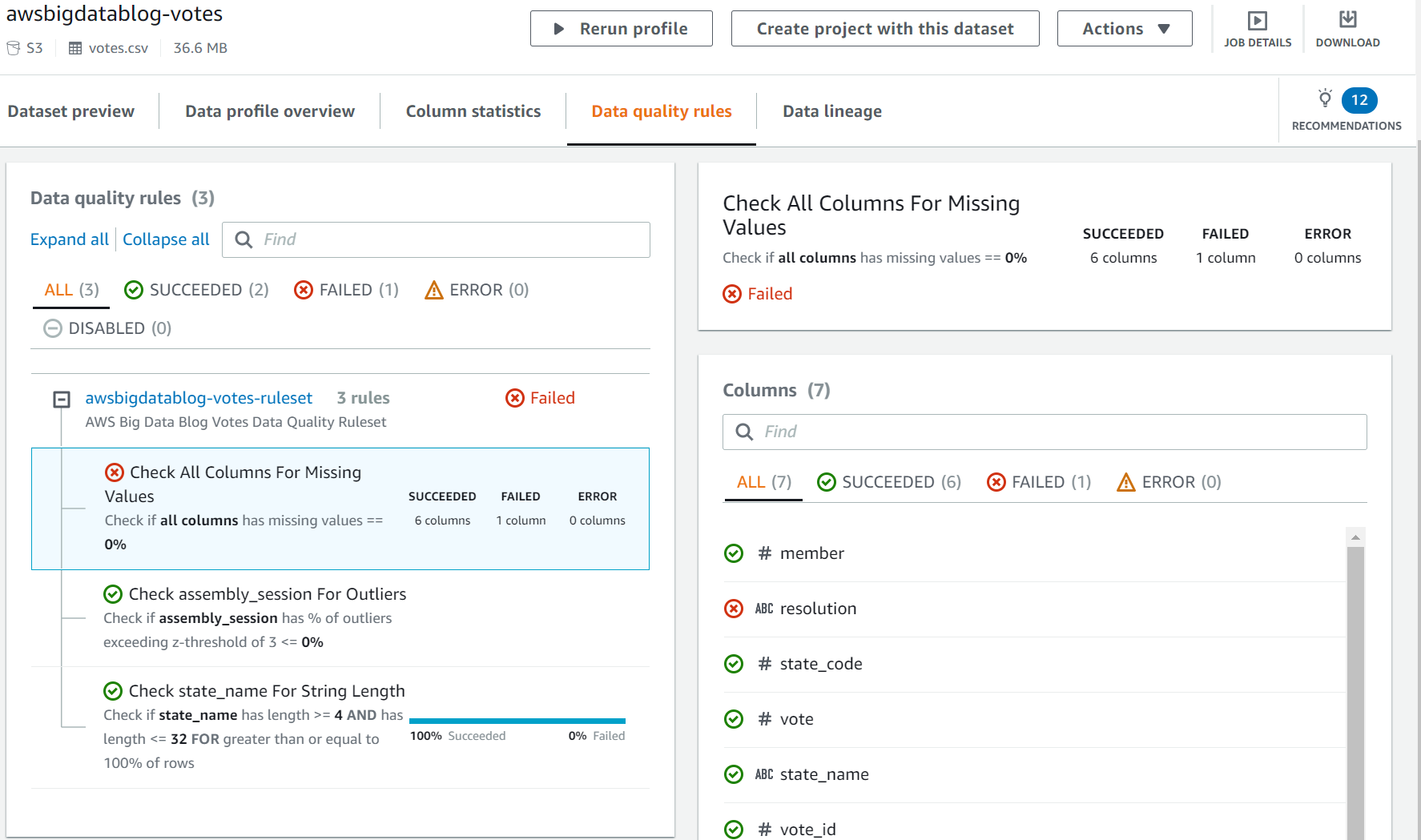
- You can investigate the rule failure on the DataBrew console by choosing the
AWSGlueDataBrewProfileResultsvalue in the CloudFormation stack outputs.
Clean up
To avoid incurring future charges, delete the resources. On the AWS CloudFormation console, delete the stack named AWSBigDataBlogDataBrewDQSample.
Conclusion
In this post, you learned how to build automated, event-driven data quality validation pipelines. With DataBrew, you can define data quality rules, thresholds, and rulesets for your business and technical requirements. Step Functions, EventBridge, and Amazon SNS allow you to build complex pipelines with customizable error handling and alerting tailored to your needs.
You can learn more about this solution and the source code by visiting the GitHub repository. To learn more about DataBrew data quality rules, visit AWS Glue DataBrew now allows customers to create data quality rules to define and validate their business requirements or refer to Validating data quality in AWS Glue DataBrew.
About the Authors
 Laith Al-Saadoon is a Principal Prototyping Architect on the Envision Engineering team. He builds prototypes and solutions using AI, machine learning, IoT & edge computing, streaming analytics, robotics, and spatial computing to solve real-world customer problems. In his free time, Laith enjoys outdoor activities such as photography, drone flights, hiking, and paintballing.
Laith Al-Saadoon is a Principal Prototyping Architect on the Envision Engineering team. He builds prototypes and solutions using AI, machine learning, IoT & edge computing, streaming analytics, robotics, and spatial computing to solve real-world customer problems. In his free time, Laith enjoys outdoor activities such as photography, drone flights, hiking, and paintballing.
 Gordon Burgess is a Senior Product Manager with AWS Glue DataBrew. He is passionate about helping customers discover insights from their data, and focuses on building user experiences and rich functionality for analytics products. Outside of work, Gordon enjoys reading, coffee, and building computers.
Gordon Burgess is a Senior Product Manager with AWS Glue DataBrew. He is passionate about helping customers discover insights from their data, and focuses on building user experiences and rich functionality for analytics products. Outside of work, Gordon enjoys reading, coffee, and building computers.