AWS Big Data Blog
Centralize feature engineering with AWS Step Functions and AWS Glue DataBrew
One of the key phases of a machine learning (ML) workflow is data preprocessing, which involves cleaning, exploring, and transforming the data. AWS Glue DataBrew, announced in AWS re:Invent 2020, is a visual data preparation tool that enables you to develop common data preparation steps without having to write any code or installation.
In this post, we show how to integrate the standard data preparation steps with training an ML model and running inference on a pre-trained model via DataBrew and AWS Step Functions. The solution is architected with an ML pipeline that trains the publicly available Air Quality Dataset to predict the CO levels in New York City.
Overview of solution
The following architecture diagram shows an overview of the ML workflow, which employs DataBrew for data preparation and scheduling jobs, and uses AWS Lambda and Step Functions to orchestrate ML model training and inference using the AWS Step Functions Data Science SDK. We use Amazon EventBridge to trigger the Step Functions state machine when the DataBrew job is complete.

The steps in this solution are as follows:
- Import your dataset to Amazon Simple Storage Service (Amazon S3).
- Launch the AWS CloudFormation stack, which deploys the following:
- DataBrew recipes for training and inference data.
- The DataBrew job’s schedule for training and inference.
- An EventBridge rule.
- A Lambda function that triggers the Step Functions state machine, which in turn orchestrates the states.
- The training state includes the following steps:
- Runs an Amazon SageMaker processing job to remove column headers.
- Performs SageMaker model training.
- Outputs the data to an S3 bucket to store the trained model.
- The inference state includes the following steps:
- Runs a SageMaker processing job to remove column headers.
- Performs a SageMaker batch transform.
- Outputs the data to an S3 bucket to store the predictions.
Prerequisites
For this solution, you should have the following prerequisites:
- An AWS account
- AWS Identity and Access Management (IAM) role permissions
- An S3 bucket (to store data and model artifacts)
- Public data access
- Python 3.7+ with pandas installed
Load the dataset to Amazon S3
In this first step, we load our air quality dataset into Amazon S3.
- Download the Outdoor Air Quality Dataset for the years 2018, 2019, and 2020, limiting to the following options:
- Pollutant – CO
- Geographic Area – New York
- Monitor Site – All Sites
- For each year of data, split by year, month, and day, and use the data for 2018–2019 to train the model and the 2020 data to run inference.
- Run the following script, which stores the output into the
NY_XXXXfolder:
- Create an S3 bucket in the
us-east-1Region and upload the foldersNY_2018andNY_2019to the pathS3://<artifactbucket>/train_raw_data/.

- Upload the folder
NY_2020toS3:// <artifactbucket>/inference_raw_data/.

Deploy your resources
For a quick start of this solution, you can deploy the provided AWS CloudFormation stack. This creates all the required resources in your account (us-east-1 Region), including the DataBrew datasets, jobs, projects, and recipes; the Step Functions train and inference state machines (which include SageMaker processing, model training, and batch transform jobs); an EventBridge rule; and the Lambda function to deploy an end-to-end ML pipeline for a predefined S3 bucket.
- Launch the following stack:

- For ArtifactBucket, enter the name of the S3 bucket you created in the previous step.
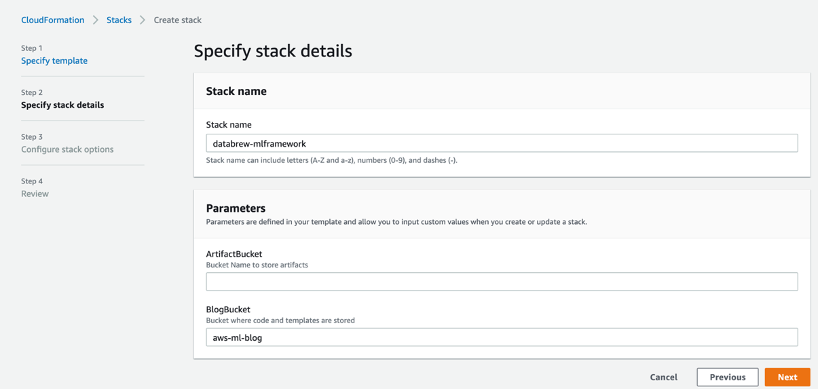
- Select the three acknowledgement check boxes.
- Choose Create stack.

Test the solution
As part of the CloudFormation template, the DataBrew job km-mlframework-trainingfeatures-job was created, which is scheduled to run every Monday at 10:00 AM UTC. This job creates the features required to train the model.
When the template deployment is successfully completed, you can manually activate the training pipeline. For this, navigate to the DataBrew console, select the DataBrew job km-mlframework-trainingfeatures-job, and choose Run job.

The job writes the features to s3://<artifactbucket>/train_features/.
When the job is complete, an EventBridge rule invokes the Lambda function, which orchestrates the SageMaker training jobs via Step Functions.

When the job is complete, the output of the model is stored in s3://<artifactbucket>/artifact-repo/model/.
In the next step, we trigger the DataBrew job km-mlframework-inferencefeatures-job, which is scheduled to run every Tuesday at 10:00 AM UTC. This job creates the inference features that are used to run inference on the trained model.
You can also activate the inference pipeline by manually triggering the DataBrew job on the DataBrew console.

The job writes the features to s3://<artifactbucket>/ inference_features/.
When the job is complete, an EventBridge rule invokes the Lambda function, which orchestrates the SageMaker batch transform job via Step Functions.

When the job is complete, the predictions are written to s3://<artifactbucket>/predictions/.
For more information on DataBrew steps and building a DataBrew recipe, see Preparing data for ML models using AWS Glue DataBrew in a Jupyter notebook.
Clean up
To avoid incurring future charges, complete the following steps:
- Wait for any currently running activity to complete, or manually stop it (DataBrew, Step Functions, SageMaker).
- Delete the scheduled DataBrew jobs
km-mlframework-trainingfeatures-jobandkm-mlframework-inferencefeatures-job. This ensures the jobs aren’t started by the schedule. - Delete the S3 bucket created to store data and model artifacts.
- Delete the CloudFormation stack created earlier.
Conclusion
DataBrew is designed to support data engineers and data scientists to experiment with data preparation steps via a visual interface. With more than 250 built-in transformations, DataBrew can be a strong tool to accelerate your ML lifecycle for development and production stages.
In this post, we walked through the process of creating an end-to-end ML framework with DataBrew, which you can use to train an ML model as well as run inferences on a schedule. You can use the same framework with your own DataBrew recipe prepared using any dataset.
To learn more on applying the most frequently used transformations from within DataBrew, see 7 most common data preparation transformations in AWS Glue DataBrew.
About the Authors
 Gayatri Ghanakota is a Machine Learning Engineer with AWS Professional Services, where she helps customers build machine learning solutions on AWS. She is passionate about developing, deploying, and explaining ML models.
Gayatri Ghanakota is a Machine Learning Engineer with AWS Professional Services, where she helps customers build machine learning solutions on AWS. She is passionate about developing, deploying, and explaining ML models.
 Surbhi Dangi is a product and design leader at Amazon Web Services. She focusses on providing ease of use and rich functionality for her analytics and monitoring on both her products – Amazon CloudWatch Synthetics and AWS Glue DataBrew. When not working, she mentors aspiring product managers, hiking, and traveling the world.
Surbhi Dangi is a product and design leader at Amazon Web Services. She focusses on providing ease of use and rich functionality for her analytics and monitoring on both her products – Amazon CloudWatch Synthetics and AWS Glue DataBrew. When not working, she mentors aspiring product managers, hiking, and traveling the world.