AWS Big Data Blog
Tag: Data Lake

Scale read and write workloads with Amazon Redshift
Amazon Redshift is a fast, fully managed, petabyte-scale cloud data warehouse that enables you to analyze large datasets using standard SQL. The concurrency scaling feature in Amazon Redshift automatically adds and removes capacity by adding concurrency scaling to handle demands from thousands of concurrent users, thereby providing consistent SLAs for unpredictable and spiky workloads such […]

How Epos Now modernized their data platform by building an end-to-end data lake with the AWS Data Lab
Epos Now provides point of sale and payment solutions to over 40,000 hospitality and retailers across 71 countries. Their mission is to help businesses of all sizes reach their full potential through the power of cloud technology, with solutions that are affordable, efficient, and accessible. Their solutions allow businesses to leverage actionable insights, manage their […]

Accelerate self-service analytics with Amazon Redshift Query Editor V2
August 2023: This post was reviewed and updated with new features. Amazon Redshift is a fast, fully managed cloud data warehouse. Tens of thousands of customers use Amazon Redshift as their analytics platform. Users such as data analysts, database developers, and data scientists use SQL to analyze their data in Amazon Redshift data warehouses. Amazon […]

How MEDHOST’s cardiac risk prediction successfully leveraged AWS analytic services
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. MEDHOST has been providing products and services to healthcare facilities of all types and sizes for over 35 years. Today, more than 1,000 healthcare facilities are partnering with MEDHOST and enhancing their […]
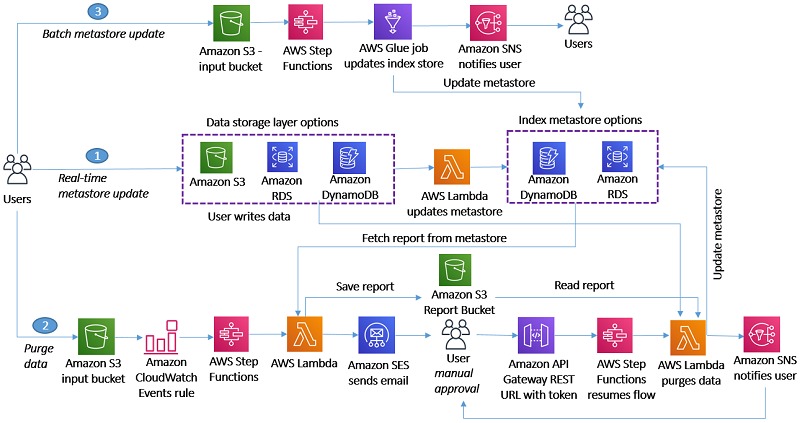
How to delete user data in an AWS data lake
General Data Protection Regulation (GDPR) is an important aspect of today’s technology world, and processing data in compliance with GDPR is a necessity for those who implement solutions within the AWS public cloud. One article of GDPR is the “right to erasure” or “right to be forgotten” which may require you to implement a solution […]

Enhancing customer safety by leveraging the scalable, secure, and cost-optimized Toyota Connected Data Lake
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Toyota Motor Corporation (TMC), a global automotive manufacturer, has made “connected cars” a core priority as part of its broader transformation from an auto company to a mobility company. In recent years, […]
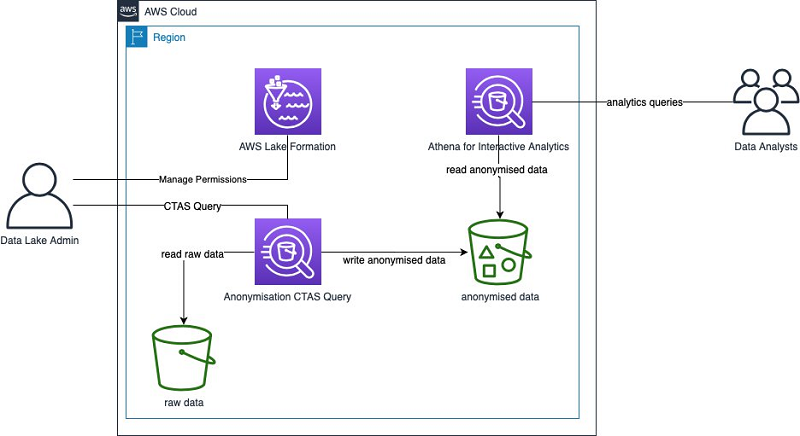
Anonymize and manage data in your data lake with Amazon Athena and AWS Lake Formation
Most organizations have to comply with regulations when dealing with their customer data. For that reason, datasets that contain personally identifiable information (PII) is often anonymized. A common example of PII can be tables and columns that contain personal information about an individual (such as first name and last name) or tables with columns that, if joined with another table, can trace back to an individual. You can use AWS Analytics services to anonymize your datasets. In this post, I describe how to use Amazon Athena to anonymize a dataset. You can then use AWS Lake Formation to provide the right access to the right personas.
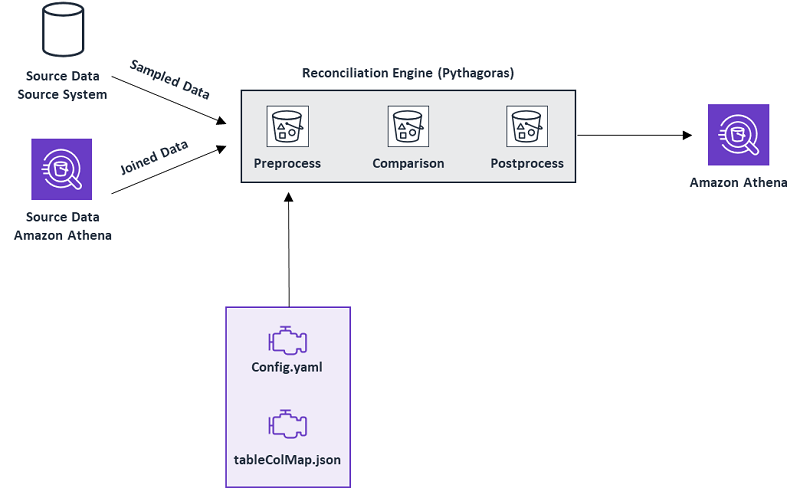
Build a distributed big data reconciliation engine using Amazon EMR and Amazon Athena
This is a guest post by Sara Miller, Head of Data Management and Data Lake, Direct Energy; and Zhouyi Liu, Senior AWS Developer, Direct Energy. Enterprise companies like Direct Energy migrate on-premises data warehouses and services to AWS to achieve fully manageable digital transformation of their organization. Freedom from traditional data warehouse constraints frees up […]

Enforce column-level authorization with Amazon QuickSight and AWS Lake Formation
Amazon QuickSight is a fast, cloud-powered, business intelligence service that makes it easy to deliver insights and integrates seamlessly with your data lake built on Amazon Simple Storage Service (Amazon S3). QuickSight users in your organization often need access to only a subset of columns for compliance and security reasons. Without having a proper solution […]
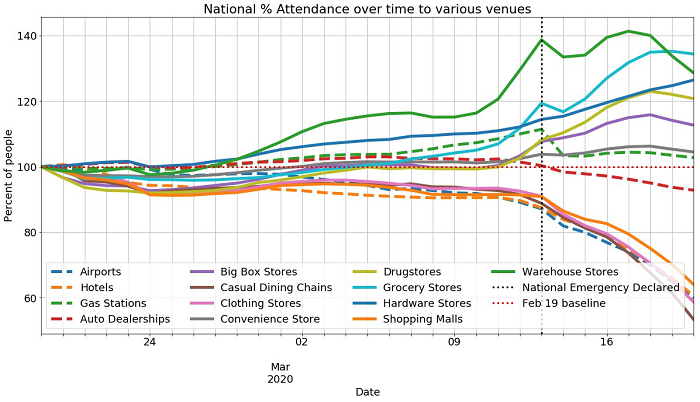
Exploring the public AWS COVID-19 data lake
This post walks you through accessing the AWS COVID-19 data lake through the AWS Glue Data Catalog via Amazon SageMaker or Jupyter and using the open-source AWS Data Wrangler library. AWS Data Wrangler is an open-source Python package that extends the power of Pandas library to AWS and connects DataFrames and AWS data-related services (such as Amazon Redshift, Amazon S3, AWS Glue, Amazon Athena, and Amazon EMR). For more information about what you can build by using this data lake, see the associated public Jupyter notebook on GitHub.