AWS Big Data Blog
Tag: Data Lake

How Siemens built a fully managed scheduling mechanism for updates on Amazon S3 data lakes
Siemens is a global technology leader with more than 370,000 employees and 170 years of experience. To protect Siemens from cybercrime, the Siemens Cyber Defense Center (CDC) continuously monitors Siemens’ networks and assets. To handle the resulting enormous data load, the CDC built a next-generation threat detection and analysis platform called ARGOS. ARGOS is a […]

ETL and ELT design patterns for modern data architecture using Amazon Redshift: Part 2
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks. Part 1 of this multi-post series, ETL and ELT design patterns for modern data architecture using Amazon Redshift: Part 1, […]

ETL and ELT design patterns for lake house architecture using Amazon Redshift: Part 1
New: Read Amazon Redshift continues its price-performance leadership to learn what analytic workload trends we’re seeing from Amazon Redshift customers, new capabilities we have launched to improve Redshift’s price-performance, and the results from the latest benchmarks. Part 1 of this multi-post series discusses design best practices for building scalable ETL (extract, transform, load) and ELT (extract, […]
Matching patient records with the AWS Lake Formation FindMatches transform
Patient matching is a major obstacle in achieving healthcare interoperability. Mismatched patient records and inability to retrieve patient history can cause significant barriers to informed clinical decision-making and result in missed diagnoses or delayed treatments. Additionally, healthcare providers often invest in patient data deduplication, especially when the number of patient records is growing rapidly in […]
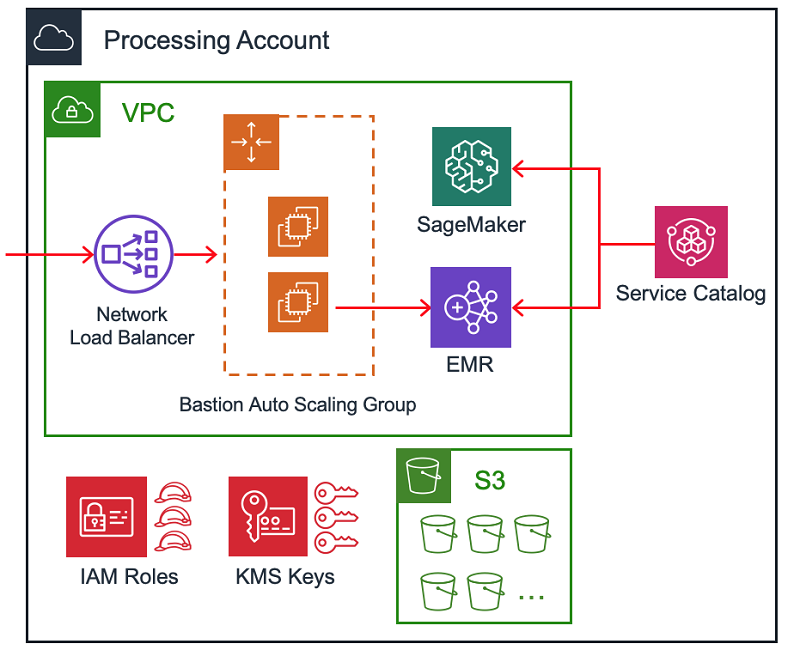
Provisioning the Intuit Data Lake with Amazon EMR, Amazon SageMaker, and AWS Service Catalog
This post outlines the approach taken by Intuit, though it is important to remember that there are many ways to build a data lake (for example, AWS Lake Formation). We’ll cover the technologies and processes involved in creating the Intuit Data Lake at a high level, including the overall structure and the automation used in provisioning accounts and resources. Watch this space in the future for more detailed blog posts on specific aspects of the system, from the other teams and engineers who worked together to build the Intuit Data Lake.

Access and manage data from multiple accounts from a central AWS Lake Formation account
his post shows how to access and manage data in multiple accounts from a central AWS Lake Formation account. The walkthrough demonstrates a centralized catalog residing in the master Lake Formation account, with data residing in the different accounts. The post shows how to grant access permissions from the Lake Formation service to read, write and update the catalog and access data in different accounts.

Discover metadata with AWS Lake Formation: Part 2
In this post, you will learn how to use the metadata search capabilities of Lake Formation. By defining specific user permissions, Lake Formation allows you to grant and revoke access to metadata in the Data Catalog as well as the underlying data stored in S3.

Getting started with AWS Lake Formation
June 2024: This post was reviewed and updated for accuracy. AWS Lake Formation enables you to set up a secure data lake. A data lake is a centralized, curated, and secured repository storing all your structured and unstructured data, at any scale. You can store your data as-is, without having first to structure it. And […]

Integrate and deduplicate datasets using AWS Lake Formation FindMatches
AWS Lake Formation FindMatches is a new machine learning (ML) transform that enables you to match records across different datasets as well as identify and remove duplicate records, with little to no human intervention. FindMatches is part of Lake Formation, a new AWS service that helps you build a secure data lake in a few simple steps.
To use FindMatches, you don’t have to write code or know how ML works. Your data doesn’t have to include a unique identifier, nor must fields match exactly.
Amazon EMR Migration Guide
Today, we’re introducing the Amazon EMR Migrations Guide (first published June 2019.) This paper is a comprehensive guide to offer sound technical advice to help customers in planning how to move from on-premises big data deployments to EMR.