AWS Big Data Blog
From Data Lake to Data Warehouse: Enhancing Customer 360 with Amazon Redshift Spectrum
Achieving a 360o-view of your customer has become increasingly challenging as companies embrace omni-channel strategies, engaging customers across websites, mobile, call centers, social media, physical sites, and beyond. The promise of a web where online and physical worlds blend makes understanding your customers more challenging, but also more important. Businesses that are successful in this medium have a significant competitive advantage.
The big data challenge requires the management of data at high velocity and volume. Many customers have identified Amazon S3 as a great data lake solution that removes the complexities of managing a highly durable, fault tolerant data lake infrastructure at scale and economically.
AWS data services substantially lessen the heavy lifting of adopting technologies, allowing you to spend more time on what matters most—gaining a better understanding of customers to elevate your business. In this post, I show how a recent Amazon Redshift innovation, Redshift Spectrum, can enhance a customer 360 initiative.
Customer 360 solution
A successful customer 360 view benefits from using a variety of technologies to deliver different forms of insights. These could range from real-time analysis of streaming data from wearable devices and mobile interactions to historical analysis that requires interactive, on demand queries on billions of transactions. In some cases, insights can only be inferred through AI via deep learning. Finally, the value of your customer data and insights can’t be fully realized until it is operationalized at scale—readily accessible by fleets of applications. Companies are leveraging AWS for the breadth of services that cover these domains, to drive their data strategy.
A number of AWS customers stream data from various sources into a S3 data lake through Amazon Kinesis. They use Kinesis and technologies in the Hadoop ecosystem like Spark running on Amazon EMR to enrich this data. High-value data is loaded into an Amazon Redshift data warehouse, which allows users to analyze and interact with data through a choice of client tools. Redshift Spectrum expands on this analytics platform by enabling Amazon Redshift to blend and analyze data beyond the data warehouse and across a data lake.
The following diagram illustrates the workflow for such a solution.
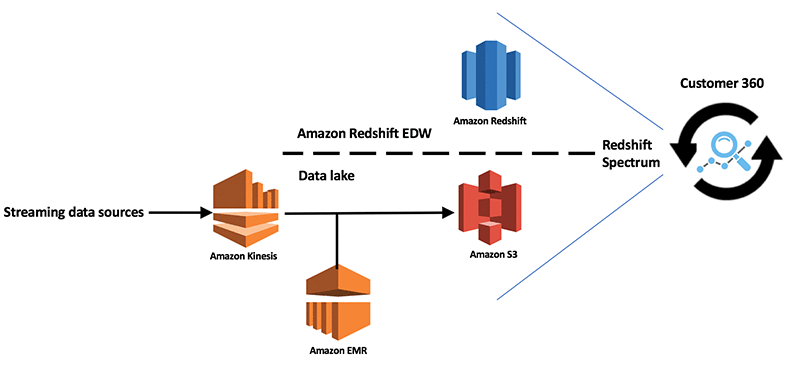
This solution delivers value by:
- Reducing complexity and time to value to deeper insights. For instance, an existing data model in Amazon Redshift may provide insights across dimensions such as customer, geography, time, and product on metrics from sales and financial systems. Down the road, you may gain access to streaming data sources like customer-care call logs and website activity that you want to blend in with the sales data on the same dimensions to understand how web and call center experiences maybe correlated with sales performance. Redshift Spectrum can join these dimensions in Amazon Redshift with data in S3 to allow you to quickly gain new insights, and avoid the slow and more expensive alternative of fully integrating these sources with your data warehouse.
- Providing an additional avenue for optimizing costs and performance. In cases like call logs and clickstream data where volumes could be many TBs to PBs, storing the data exclusively in S3 yields significant cost savings. Interactive analysis on massive datasets may now be economically viable in cases where data was previously analyzed periodically through static reports generated by inexpensive batch processes. In some cases, you can improve the user experience while simultaneously lowering costs. Spectrum is powered by a large-scale infrastructure external to your Amazon Redshift cluster, and excels at scanning and aggregating large volumes of data. For instance, your analysts maybe performing data discovery on customer interactions across millions of consumers over years of data across various channels. On this large dataset, certain queries could be slow if you didn’t have a large Amazon Redshift cluster. Alternatively, you could use Redshift Spectrum to achieve a better user experience with a smaller cluster.
Proof of concept walkthrough
To make evaluation easier for you, I’ve conducted a Redshift Spectrum proof-of-concept (PoC) for the customer 360 use case. For those who want to replicate the PoC, the instructions, AWS CloudFormation templates, and public data sets are available in the GitHub repository.
The remainder of this post is a journey through the project, observing best practices in action, and learning how you can achieve business value. The walkthrough involves:
- An analysis of performance data from the PoC environment involving queries that demonstrate blending and analysis of data across Amazon Redshift and S3. Observe that great results are achievable at scale.
- Guidance by example on query tuning, design, and data preparation to illustrate the optimization process. This includes tuning a query that combines clickstream data in S3 with customer and time dimensions in Amazon Redshift, and aggregates ~1.9 B out of 3.7 B+ records in under 10 seconds with a small cluster!
- Guidance and measurements to help assess deciding between two options: accessing and analyzing data exclusively in Amazon Redshift, or using Redshift Spectrum to access data left in S3.
Stream ingestion and enrichment
The focus of this post isn’t stream ingestion and enrichment on Kinesis and EMR, but be mindful of performance best practices on S3 to ensure good streaming and query performance:
- Use random object keys: The data files provided for this project are prefixed with SHA-256 hashes to prevent hot partitions. This is important to ensure that optimal request rates to support PUT requests from the incoming stream in addition to certain queries from large Amazon Redshift clusters that could send a large number of parallel GET requests.
- Micro-batch your data stream: S3 isn’t optimized for small random write workloads. Your datasets should be micro-batched into large files. For instance, the “parquet-1” dataset provided batches >7 million records per file. The optimal file size for Redshift Spectrum is usually in the 100 MB to 1 GB range.
If you have an edge case that may pose scalability challenges, AWS would love to hear about it. For further guidance, talk to your solutions architect.
Environment
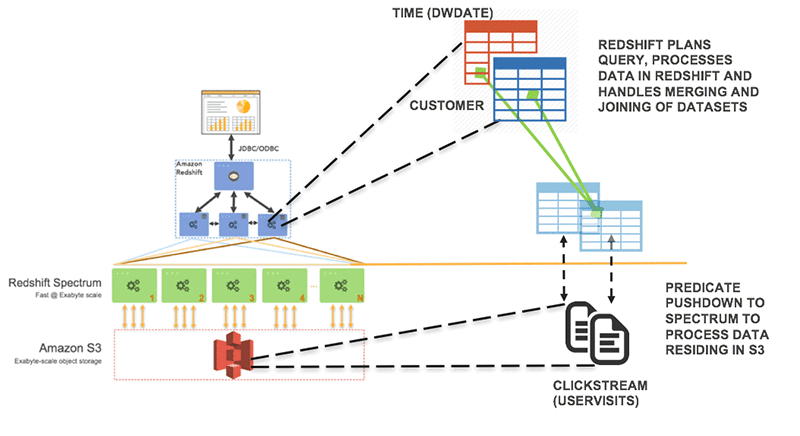
The project consists of the following environment:
- Amazon Redshift cluster: 4 X dc1.large
- Data:
- Time and customer dimension tables are stored on all Amazon Redshift nodes (ALL distribution style):
- The data originates from the DWDATE and CUSTOMER tables in the Star Schema Benchmark
- The customer table contains attributes for 3 million customers.
- The time data is at the day-level granularity, and spans 7 years, from the start of 1992 to the end of 1998.
- The clickstream data is stored in an S3 bucket, and serves as a fact table.
- Various copies of this dataset in CSV and Parquet format have been provided, for reasons to be discussed later.
- The data is a modified version of the uservisits dataset from AMPLab’s Big Data Benchmark, which was generated by Intel’s Hadoop benchmark tools.
- Changes were minimal, so that existing test harnesses for this test can be adapted:
- Increased the 751,754,869-row dataset 5X to 3,758,774,345 rows.
- Added surrogate keys to support joins with customer and time dimensions. These keys were distributed evenly across the entire dataset to represents user visits from six customers over seven years.
- Values for the visitDate column were replaced to align with the 7-year timeframe, and the added time surrogate key.
- Time and customer dimension tables are stored on all Amazon Redshift nodes (ALL distribution style):
Queries across the data lake and data warehouse
Imagine a scenario where a business analyst plans to analyze clickstream metrics like ad revenue over time and by customer, market segment and more. The example below is a query that achieves this effect:

The query part highlighted in red retrieves clickstream data in S3, and joins the data with the time and customer dimension tables in Amazon Redshift through the part highlighted in blue. The query returns the total ad revenue for three customers over the last three months, along with info on their respective market segment.
Unfortunately, this query takes around three minutes to run, and doesn’t enable the interactive experience that you want. However, there’s a number of performance optimizations that you can implement to achieve the desired performance.
Performance analysis
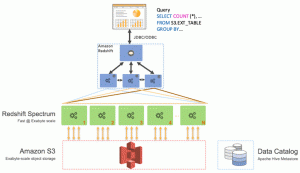
Two key utilities provide visibility into Redshift Spectrum:
- EXPLAIN
Provides the query execution plan, which includes info around what processing is pushed down to Redshift Spectrum. Steps in the plan that include the prefix S3 are executed on Redshift Spectrum. For instance, the plan for the previous query has the step “S3 Seq Scan clickstream.uservisits_csv10”, indicating that Redshift Spectrum performs a scan on S3 as part of the query execution. - SVL_S3QUERY_SUMMARY
Statistics for Redshift Spectrum queries are stored in this table. While the execution plan presents cost estimates, this table stores actual statistics for past query runs.
You can get the statistics of your last query by inspecting the SVL_S3QUERY_SUMMARY table with the condition (query = pg_last_query_id()). Inspecting the previous query reveals that the entire dataset of nearly 3.8 billion rows was scanned to retrieve less than 66.3 million rows. Improving scan selectivity in your query could yield substantial performance improvements.
Partitioning
Partitioning is a key means to improving scan efficiency. In your environment, the data and tables have already been organized, and configured to support partitions. For more information, see the PoC project setup instructions. The clickstream table was defined as:
The entire 3.8 billion-row dataset is organized as a collection of large files where each file contains data exclusive to a particular customer and month in a year. This allows you to partition your data into logical subsets by customer and year/month. With partitions, the query engine can target a subset of files:
- Only for specific customers
- Only data for specific months
- A combination of specific customers and year/months
You can use partitions in your queries. Instead of joining your customer data on the surrogate customer key (that is, c.c_custkey = uv.custKey), the partition key “customer” should be used instead:
This query should run approximately twice as fast as the previous query. If you look at the statistics for this query in SVL_S3QUERY_SUMMARY, you see that only half the dataset was scanned. This is expected because your query is on three out of six customers on an evenly distributed dataset. However, the scan is still inefficient, and you can benefit from using your year/month partition key as well:
All joins between the tables are now using partitions. Upon reviewing the statistics for this query, you should observe that Redshift Spectrum scans and returns the exact number of rows, 66,270,117. If you run this query a few times, you should see execution time in the range of 8 seconds, which is a 22.5X improvement on your original query!
Predicate pushdown and storage optimizations
Previously, I mentioned that Redshift Spectrum performs processing through large-scale infrastructure external to your Amazon Redshift cluster. It is optimized for performing large scans and aggregations on S3. In fact, Redshift Spectrum may even out-perform a medium size Amazon Redshift cluster on these types of workloads with the proper optimizations. There are two important variables to consider for optimizing large scans and aggregations:
- File size and count. As a general rule, use files 100 MB-1 GB in size, as Redshift Spectrum and S3 are optimized for reading this object size. However, the number of files operating on a query is directly correlated with the parallelism achievable by a query. There is an inverse relationship between file size and count: the bigger the files, the fewer files there are for the same dataset. Consequently, there is a trade-off between optimizing for object read performance, and the amount of parallelism achievable on a particular query. Large files are best for large scans as the query likely operates on sufficiently large number of files. For queries that are more selective and for which fewer files are operating, you may find that smaller files allow for more parallelism.
- Data format. Redshift Spectrum supports various data formats. Columnar formats like Parquet can sometimes lead to substantial performance benefits by providing compression and more efficient I/O for certain workloads. Generally, format types like Parquet should be used for query workloads involving large scans, and high attribute selectivity. Again, there are trade-offs as formats like Parquet require more compute power to process than plaintext. For queries on smaller subsets of data, the I/O efficiency benefit of Parquet is diminished. At some point, Parquet may perform the same or slower than plaintext. Latency, compression rates, and the trade-off between user experience and cost should drive your decision.
To help illustrate how Redshift Spectrum performs on these large aggregation workloads, run a basic query that aggregates the entire ~3.7 billion record dataset on Redshift Spectrum, and compared that with running the query exclusively on Amazon Redshift:
For the Amazon Redshift test case, the clickstream data is loaded, and distributed evenly across all nodes (even distribution style) with optimal column compression encodings prescribed by the Amazon Redshift’s ANALYZE command.
The Redshift Spectrum test case uses a Parquet data format with each file containing all the data for a particular customer in a month. This results in files mostly in the range of 220-280 MB, and in effect, is the largest file size for this partitioning scheme. If you run tests with the other datasets provided, you see that this data format and size is optimal and out-performs others by ~60X.
Performance differences will vary depending on the scenario. The important takeaway is to understand the testing strategy and the workload characteristics where Redshift Spectrum is likely to yield performance benefits.
The following chart compares the query execution time for the two scenarios. The results indicate that you would have to pay for 12 X DC1.Large nodes to get performance comparable to using a small Amazon Redshift cluster that leverages Redshift Spectrum.

Chart showing simple aggregation on ~3.7 billion records
So you’ve validated that Spectrum excels at performing large aggregations. Could you benefit by pushing more work down to Redshift Spectrum in your original query? It turns out that you can, by making the following modification:

The clickstream data is stored at a day-level granularity for each customer while your query rolls up the data to the month level per customer. In the earlier query that uses the day/month partition key, you optimized the query so that it only scans and retrieves the data required, but the day level data is still sent back to your Amazon Redshift cluster for joining and aggregation. The query shown here pushes aggregation work down to Redshift Spectrum as indicated by the query plan:

In this query, Redshift Spectrum aggregates the clickstream data to the month level before it is returned to the Amazon Redshift cluster and joined with the dimension tables. This query should complete in about 4 seconds, which is roughly twice as fast as only using the partition key. The speed increase is evident upon reviewing the SVL_S3QUERY_SUMMARY table:
- Bytes scanned is 22X less because of the Parquet data format.
- Only 9 records are returned back to the Amazon Redshift cluster as a result of the push-down, instead of ~66.2 million, leading to substantially less join overhead, and about 795 MB less data sent back to your cluster.
- No adverse change in average parallelism.
Assessing the value of Amazon Redshift vs. Redshift Spectrum
At this point, you might be asking yourself, why would I ever not use Redshift Spectrum? Well, you still get additional value for your money by loading data into Amazon Redshift, and querying in Amazon Redshift vs. querying S3.
In fact, it turns out that the last version of our query runs even faster when executed exclusively in native Amazon Redshift, as shown in the following chart:

Chart comparing Amazon Redshift vs. Redshift Spectrum with pushdown aggregation over 3 months of data
As a general rule, queries that aren’t dominated by I/O and which involve multiple joins are better optimized in native Amazon Redshift. For instance, the performance difference between running the partition key query entirely in Amazon Redshift versus with Redshift Spectrum is twice as large as that that of the pushdown aggregation query, partly because the former case benefits more from better join performance.
Furthermore, the variability in latency in native Amazon Redshift is lower. For use cases where you have tight performance SLAs on queries, you may want to consider using Amazon Redshift exclusively to support those queries.
On the other hand, when you perform large scans, you could benefit from the best of both worlds: higher performance at lower cost. For instance, imagine that you wanted to enable your business analysts to interactively discover insights across a vast amount of historical data. In the example below, the pushdown aggregation query is modified to analyze seven years of data instead of three months:
This query requires scanning and aggregating nearly 1.9 billion records. As shown in the chart below, Redshift Spectrum substantially speeds up this query. A large Amazon Redshift cluster would have to be provisioned to support this use case. With the aid of Redshift Spectrum, you could use an existing small cluster, keep a single copy of your data in S3, and benefit from economical, durable storage while only paying for what you use via the pay per query pricing model.

Chart comparing Amazon Redshift vs. Redshift Spectrum with pushdown aggregation over 7 years of data
Summary
Redshift Spectrum lowers the time to value for deeper insights on customer data queries spanning the data lake and data warehouse. It can enable interactive analysis on datasets in cases that weren’t economically practical or technically feasible before.
There are cases where you can get the best of both worlds from Redshift Spectrum: higher performance at lower cost. However, there are still latency-sensitive use cases where you may want native Amazon Redshift performance. For more best practice tips, see the 10 Best Practices for Amazon Redshift post.
Please visit the Amazon Redshift Spectrum PoC Environment Github page. If you have questions or suggestions, please comment below.
Additional Reading
Learn more about how Amazon Redshift Spectrum extends data warehousing out to exabytes – no loading required.
About the Author
 Dylan Tong is an Enterprise Solutions Architect at AWS. He works with customers to help drive their success on the AWS platform through thought leadership and guidance on designing well architected solutions. He has spent most of his career building on his expertise in data management and analytics by working for leaders and innovators in the space.
Dylan Tong is an Enterprise Solutions Architect at AWS. He works with customers to help drive their success on the AWS platform through thought leadership and guidance on designing well architected solutions. He has spent most of his career building on his expertise in data management and analytics by working for leaders and innovators in the space.