AWS Big Data Blog
Category: AWS CloudFormation

Migrate to Apache Flink 2.2 on Amazon Managed Service for Apache Flink
In this post, we explain what’s new in Amazon Managed Service for Apache Flink 2.2, provide a guided migration using CLI commands, console instructions, and code examples, and show you how to monitor the upgrade and roll back if needed.

How Huron built an Amazon QuickSight Asset Catalogue with AWS CDK Based Deployment Pipeline
This is a guest blog post co-written with Corey Johnson from Huron. Having an accurate and up-to-date inventory of all technical assets helps an organization ensure it can keep track of all its resources with metadata information such as their assigned owners, last updated date, used by whom, how frequently, and more. It helps engineers, […]

Automate Amazon Redshift Serverless data warehouse management using AWS CloudFormation and the AWS CLI
Amazon Redshift Serverless makes it simple to run and scale analytics without having to manage the instance type, instance size, lifecycle management, pausing, resuming, and so on. It automatically provisions and intelligently scales data warehouse compute capacity to deliver fast performance for even the most demanding and unpredictable workloads, and you pay only for what […]

Automate your validated dataset deployment using Amazon QuickSight and AWS CloudFormation
A lot of the power behind business intelligence (BI) and data visualization tools such as Amazon QuickSight comes from the ability to work interactively with data through a GUI. Report authors create dashboards using GUI-based tools, then in just a few clicks can share the dashboards with business users and decision-makers. This workflow empowers authors […]

Automate Amazon Redshift Cluster management operations using AWS CloudFormation
Amazon Redshift is a fast, petabyte-scale cloud data warehouse delivering the best price-performance. Tens of thousands of customers run business-critical workloads on Amazon Redshift. Amazon Redshift offers many features that enable you to build scalable, highly performant, cost-effective, and easy-to-manage workloads. For example, you can scale an Amazon Redshift cluster up or down based on […]
Increase Amazon Elasticsearch Service performance by upgrading to Graviton2
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. Amazon OpenSearch Service supports multiple instance types based on your use case. In 2021, AWS announced general purpose (M6g), compute optimized (C6g), and memory optimized (R6g, R6gd) instance types for Amazon OpenSearch Service version 7.9 or later powered by AWS […]
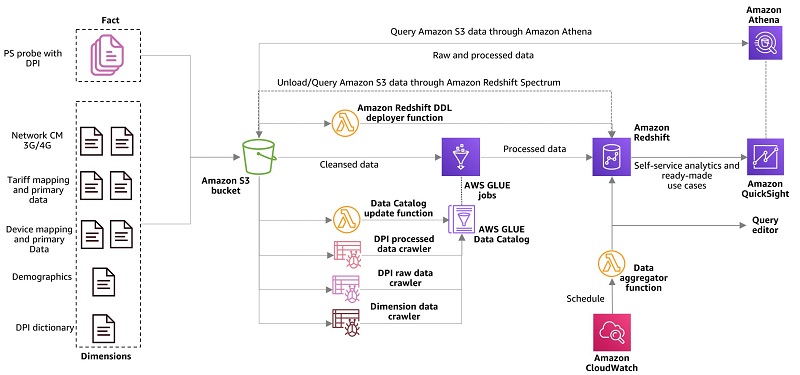
Data monetization and customer experience optimization using telco data assets: Part 2
Part 1 of this series explains the importance of building and implementing a customer experience (CX) management and data monetization strategy for telecom service providers (TSPs), and the major challenges driving these initiatives. It also includes an AWS CloudFormation template to set up a demonstration of the solution using AWS services. It covers transforming and enriching […]

Accelerating Amazon Redshift federated query to Amazon Aurora MySQL with AWS CloudFormation
Amazon Redshift federated query allows you to combine data from one or more Amazon Relational Database Service (Amazon RDS) for MySQL and Amazon Aurora MySQL databases with data already in Amazon Redshift. You can also combine such data with data in an Amazon Simple Storage Service (Amazon S3) data lake. This post shows you how […]

A public data lake for analysis of COVID-19 data
April 2024: This post was reviewed for accuracy. As the COVID-19 pandemic continues to threaten and take lives around the world, we must work together across organizations and scientific disciplines to fight this disease. Innumerable healthcare workers, medical researchers, scientists, and public health officials are already on the front lines caring for patients, searching for […]

Automate Amazon Redshift cluster creation using AWS CloudFormation
In this post, I explain how to automate the deployment of an Amazon Redshift cluster in an AWS account. AWS best practices for security and high availability drive the cluster’s configuration, and you can create it quickly by using AWS CloudFormation. I walk you through a set of sample CloudFormation templates, which you can customize as per your needs.