AWS Big Data Blog
Automate Amazon Redshift cluster creation using AWS CloudFormation
Updated February 2022 to incorporate recent Redshift features such as AQUA, RA3, Cross-AZ relocation, Amazon Redshift cluster access using query editor v2, and simplified CloudFormation templates.
Amazon Redshift is a fast, fully managed, widely popular cloud data warehouse that allows tens of thousands of our customers to gain insights from their data. You can easily get started with Amazon Redshift using the AWS Management Console. However, many customers prefer to use AWS CloudFormation to speed up cloud provisioning with infrastructure as code while following security best practices. This post explains how you can easily set up an Amazon Redshift cluster on an existing virtual private cloud (VPC) or build an entire AWS infrastructure from scratch using a CloudFormation template and follow the best practices of the AWS Well-Architected Framework.
Benefits of using CloudFormation templates
With a CloudFormation template, you can condense hundreds of manual procedures into a few steps listed in a text file. The declarative code in the file captures the intended state of the resources to create, and you can choose to automate the creation of hundreds of AWS resources. This template becomes the single source of truth for your infrastructure.
A CloudFormation template acts as an accelerator. It helps you automate the deployment of technology and infrastructure in a safe and repeatable manner across multiple Regions and multiple accounts with the least amount of effort and time.
Solution overview
The following architecture diagram describes the solution that this post uses.
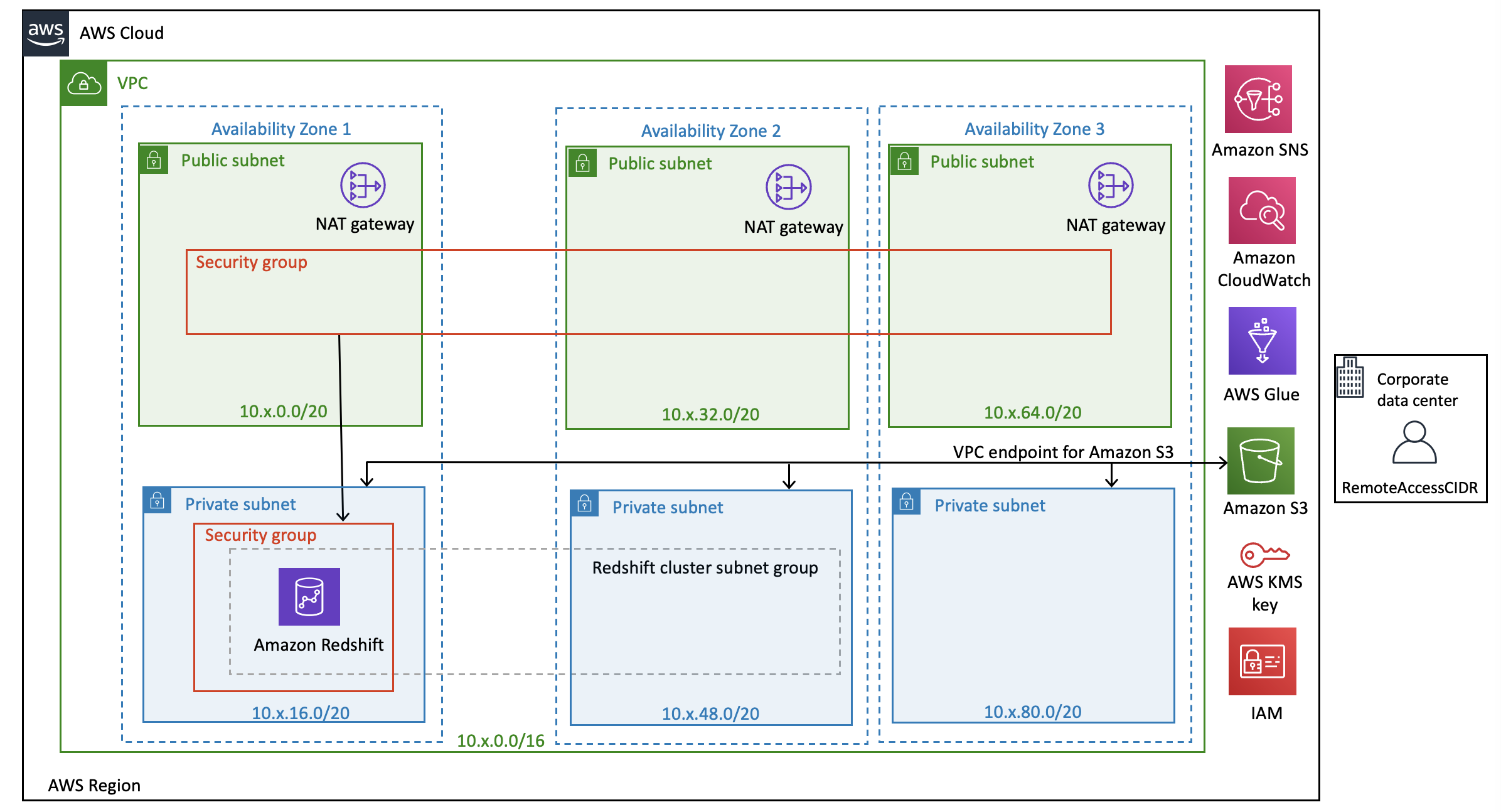
The sample CloudFormation templates provision the network infrastructure and all the components shown in the architecture diagram:
- The first template sets up a VPC, subnets, route tables, internet gateway, NAT gateway, Amazon Simple Storage Service (Amazon S3) gateway endpoint, and other networking components
- A second template sets up an Amazon Redshift cluster, Amazon CloudWatch alarms, AWS Glue Data Catalog, and an Amazon Redshift AWS Identity and Access Management (IAM) role for Amazon Redshift Spectrum and ETL jobs
Best practices
The architecture built by these CloudFormation templates supports AWS best practices for high availability and security.
The VPC CloudFormation template takes care of the following:
- Configures three Availability Zones for high availability and disaster recovery. It geographically distributes the zones within a Region for best insulation and stability in the event of a natural disaster.
- Provisions one public subnet and one private subnet for each Availability Zone. I recommend using public subnets for external-facing resources and private subnets for internal resources to reduce the risk of data exfiltration.
- Creates and associates network ACLs with default rules to the private and public subnets. AWS recommends using network ACLs as firewalls to control inbound and outbound traffic at the subnet level. These network ACLs provide individual controls that you can customize as a second layer of defense.
- Creates and associates independent routing tables for each of the private subnets, which you can configure to control the flow of traffic within and outside the VPC. The public subnets share a single routing table because they all use the same internet gateway as the sole route to communicate with the internet.
- Creates a NAT gateway in each of the three public subnets for high availability. NAT gateways offer significant advantages over NAT instances in terms of deployment, availability, and maintenance. NAT gateways allow instances in a private subnet to connect to the internet or other AWS services even as they prevent the internet from initiating a connection with those instances.
- Creates an Amazon Virtual Private Cloud (Amazon VPC) endpoint for Amazon S3. Amazon Redshift and other AWS resources—running in a private subnet of a VPC—can connect privately to access S3 buckets. For example, data loading from Amazon S3 and unloading data to Amazon S3 happens over a private, secure, and reliable connection.
The Amazon Redshift cluster CloudFormation template takes care of the following key resources and features:
- Encryption at rest – Creates an AWS Key Management Service (AWS KMS) customer managed key and encrypts the Amazon Redshift cluster with that key to ensure encryption at rest.
- Encryption in transit – Creates a custom Amazon Redshift parameter group with
require_sslset totrueto ensure encryption in transit. - Audit logging – Enables database audit logging to monitor connection logs, user logs, and user activity logs in the Amazon Redshift cluster. These logs are stored in an S3 bucket with a lifecycle rule that archives logs older than 14 days to Amazon S3 Glacier.
- Enhanced VPC routing – Enables enhanced VPC routing for your cluster, which forces all COPY and UNLOAD traffic between your cluster and data repositories through your VPC.
- Advanced Query Accelerator (AQUA) – Enables the AQUA feature for Amazon Redshift RA3 instances, which is a new distributed and hardware-accelerated cache that enables Amazon Redshift to run up to 10 times faster for certain types of queries.
- Security group – Creates an Amazon Elastic Compute Cloud (Amazon EC2) security group and associates it with the Amazon Redshift cluster. This allows you to lock down access to the Amazon Redshift cluster to known CIDR scopes and ports.
- Cluster subnet group – Creates an Amazon Redshift cluster subnet group that spans across multiple Availability Zones so that you can create different clusters into different zones to minimize the impact of failure of one zone. According to security best practices, we recommend you configure the Amazon Redshift cluster in the private subnets and use the non-default port.
- Availability Zone relocation – Enables cluster relocation for Amazon Redshift RA3 instances to move your cluster to another Availability Zone without any loss of data or changes to your applications, improving the service availability.
- Number of nodes – Creates a minimum two-node cluster, unless you choose 1 against the input parameter
NumberOfNodes. AWS recommends using at least two nodes per cluster for production. For more information, see Availability and Durability. - Concurrency scaling – Enables concurrency scaling to automatically add additional capacity to process an increase in workloads.
- Redshift Spectrum – Allows you to add your existing S3 bucket for Redshift Spectrum access. It creates an IAM role with a policy to grant the minimum permissions required to use Redshift Spectrum to access Amazon S3, CloudWatch Logs, and AWS Glue. It then associates this IAM role with Amazon Redshift.
- AWS Glue Data Catalog – Creates an AWS Glue Data Catalog as a metadata store for your AWS data lake.
- AWS Secrets Manager integration – Integrates with AWS Secrets Manager to securely store and rotate the primary user credentials of the Amazon Redshift cluster.
- IAM integration – Adds an IAM role to the Amazon Redshift cluster, which is the preferred method to supply security credentials for Amazon Redshift to access other AWS services.
- Snapshot retention – Configures Amazon Redshift automatic snapshots with retention to 35 days for production environments and 8 days for non-production environments. This allows you to recover your production database to any point in time in the last 35 days (or 8 days for a non-production database).
- Delete stack configuration – Takes a final snapshot of the Amazon Redshift database automatically when you delete the Amazon Redshift cluster by deleting the CloudFormation stack. This prevents data loss from the accidental deletion of your CloudFormation stack.
- Restore cluster from snapshot – Provides an option to restore the Amazon Redshift cluster from a previously taken snapshot.
- Notifications with CloudWatch alarms – Enables a CloudWatch alarm to send email notifications when CPU utilization exceeds a 95% threshold. For more information, see Managing alarms.
- Tags – Attaches optional common tags to the Amazon Redshift clusters and other resources. AWS recommends assigning tags to your cloud infrastructure resources to manage resource access control, cost tracking, automation, and organization.
- Cluster parameter group – Creates an Amazon Redshift cluster parameter group with the following configuration and associates it with the Amazon Redshift cluster. These parameters are only a general guide. Review and customize them to suit your needs.
| Parameter | Value | Description |
enable_user_activity_logging |
true |
This enables the user activity log. For more information, see Database Audit Logging. |
require_ssl |
true |
This enables SSL connections to the Amazon Redshift cluster. |
wlm_json_configuration |
This creates a custom workload management queue (WLM) with the following configuration:
You can create different rules based on your needs and choose different actions (stop or change priority or log). |
|
max_concurrency_scaling_clusters |
1 (or what you chose) |
This sets the maximum number of concurrency scaling clusters allowed when concurrency scaling is enabled. |
auto_analyze |
TRUE |
If true, Amazon Redshift continuously monitors your database and automatically performs analyze operations in the background. |
statement_timeout |
43200000 |
This stops any statement that takes more than the specified number of milliseconds. The statement_timeout value is the maximum amount of time a query can run before Amazon Redshift stops it. |
Prerequisites
Before setting up the CloudFormation stacks, you must have an AWS account and an IAM user with sufficient permissions to interact with the console and the services listed in the architecture. Your IAM permissions must also include access to create IAM roles and policies created by the CloudFormation template.
Set up the resources using AWS CloudFormation
This blog provides these CloudFormation templates as a general guide. Review and customize them to suit your needs. Some of the resources deployed by these stacks incur costs as long as they remain in use.
Set up the VPC, subnets, and other networking components
In this step, you create a VPC, subnets, route tables, internet gateway, NAT gateway, Amazon S3 gateway endpoint, and other networking components using the provided CloudFormation template. Complete the following steps to create these resources in your AWS account:
- Sign in to the console.
- In the navigation bar, choose the AWS Region in which to create the stack, and choose Next.
This CloudFormation stack requires three Availability Zones for setting up the public and private subnets. Choose a Region that has at least three Availability Zones.
- Choose Launch Stack to launch AWS CloudFormation in your AWS account with a template:

- For Stack name, enter a meaningful name for the stack, for example,
rsVPC. - For ClassB 2nd Octet, specify the second octet of the IPv4 CIDR block for the VPC (10.XXX.0.0/16).
You can specify any number between and including 0–255; for example, specify 33 to create a VPC with IPv4 CIDR block 10.33.0.0/16. To learn more about VPC and subnet sizing for IPv4, see VPC and Subnet Sizing for IPv4.
- Choose Next.

- On the next screen, enter any required tags, an IAM role, or any advanced options, then choose Next.
- Review the details on the final screen and choose Create stack.
Stack creation takes a few minutes. Check the stack’s Resources tab to see the physical IDs of the various components set up by this stack.
You’re now ready to set up the Amazon Redshift cluster.
Set up the Amazon Redshift cluster
In this step, you set up an Amazon Redshift cluster, CloudWatch alarms, AWS Glue Data Catalog, Amazon Redshift IAM role, and required configuration using the CloudFormation template. Complete the following steps to create these resources in the VPC:
- On the navigation bar, choose the Region where you want to create the stack, then choose Next.
- Choose Launch Stack:
- Enter the mandatory parameters listed in the following table.
| Parameter | Default Value | Description |
Stack name |
. | Enter a meaningful name for the stack, for example, rsdb. |
VPC ID |
. | The VPC identifier for your existing VPC. |
Private Subnet 1 Id |
. | The IP range (CIDR notation) for the first private subnet. |
Private Subnet 2 Id |
. | The IP range (CIDR notation) for the second private subnet. |
Permitted IP range |
. | Allowed CIDR block to access Redshift cluster. |
Node Type for Redshift cluster |
ra3.xlplus |
The type of node to be provisioned. |
Number of nodes |
2 |
The number of compute nodes in the cluster. |
Redshift database name |
rsdev01 |
The name of the first database to be created when the cluster is created. Must start with a–z and contain only a–z or 0–9. |
Email address for SNS notifications |
ops@company.com |
The email notification list that is used to configure an Amazon Simple Notification Service (Amazon SNS) topic for sending CloudWatch alarm and event notifications. The recipient must choose the Confirm subscription link in this email to set up notifications. |
- Configure the optional parameters listed in the following table.
| Parameter | Default Value | Description |
Redshift master user name |
rsadmin |
A database primary user name, for example, rsadmin. Must start with a–z and contain only a–z or 0–9. |
Enable Redshift logging to S3 |
true |
If you choose true for this parameter, the stack enables database auditing for the newly created S3 bucket. |
Concurrency Scaling |
auto |
If you choose auto, concurrency scaling is enabled for the WLM queue. Choose off to disable this feature. |
Max. number of concurrent clusters |
1 |
Enter any number between 1–10 for concurrency scaling. To configure more than 10, you must request a limit increase by submitting an Amazon Redshift Limit Increase Form. |
Enable AQUA |
auto |
If you choose auto, Amazon Redshift determines whether to use AQUA. If you choose disabled, Amazon Redshift doesn’t use AQUA. |
Redshift cluster port |
5439 |
TCP/IP port for the Amazon Redshift cluster, for example, 5439. |
Make Redshift publicly accessible |
False |
If you choose false, public access to the Amazon Redshift cluster is disabled. |
Enable VPC enhanced routing |
true |
If you choose true, the Amazon Redshift cluster is configured for enhanced VPC routing. |
Enable cross-AZ relocation |
true |
If you choose true, the cross-AZ relocation is enabled for the Amazon cluster. This is applicable only for RA3 nodes. |
Encryption at rest |
true |
If you choose true, the database encrypts your data with the KMS key. |
Amazon S3 bucket for Redshift IAM role |
. | Enter the existing S3 bucket. The stack automatically creates an IAM role and associates it with the Amazon Redshift cluster with GET and LIST access to this bucket. |
Glue catalog database name |
default |
The name of your Data Catalog database, for example, dev-catalog-01. Keep the value default if you don’t want to create a new Data Catalog. |
Maintenance window |
sat:05:00-sat:05:30 |
Enter a maintenance window for your Amazon Redshift cluster. For example, sat:05:00-sat:05:30. |
Maintenance Track |
current |
The maintenance track for the Amazon Redshift cluster. |
Automatic password rotation interval (in days) |
30 |
Number of days after which the primary user password is automatically rotated. |
Redshift snapshot identifier |
N/A |
The Amazon Redshift snapshot identifier. Keep the value N/A for a new cluster. Enter the snapshot identifier only if you want to restore from a snapshot. |
AWS account-ID of the Redshift Snapshot |
N/A |
The AWS account number where the Amazon Redshift snapshot was created. Keep the value N/A if the snapshot was created in the current AWS account. |
Environment |
none |
Select the environment stage (dev, test, pre-prod, prod, or none) for the cluster. If you specify prod, it sets snapshot retention to 35 days, sets the enable_user_activity_logging parameter to true, and creates CloudWatch alarms for high CPU-utilization and high disk space usage. Setting dev, test, or pre-prod for this parameter sets snapshot retention to 8 days, sets the enable_user_activity_logging parameter to false, and creates CloudWatch alarms only for high disk space usage. |
Unique friendly name |
redshift |
This tag designates a unique, friendly name to append as a NAME tag to all AWS resources that this stack manages. |
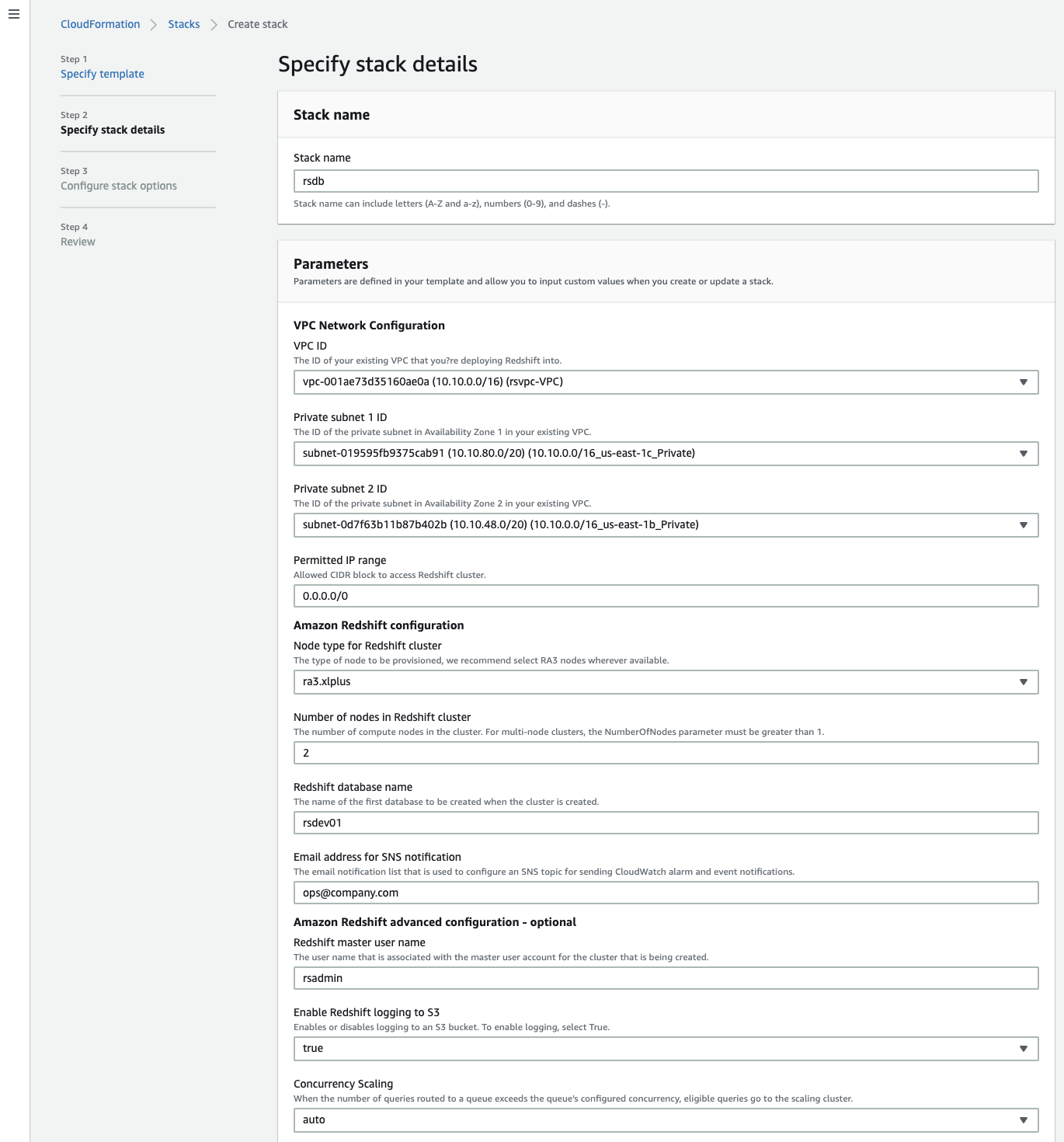
- After entering and reviewing the default parameter values, choose Next.
- Enter any required tags, an IAM role, or any advanced options, and choose Next.
- Review the details, then select the check boxes for I acknowledge that AWS CloudFormation might create IAM resources, I acknowledge that AWS CloudFormation might create IAM resources with custom names, and I acknowledge that AWS CloudFormation might require the following capability: CAPABILITY_AUTO_EXPAND.
- Choose Create stack.
Stack creation takes a few minutes. Check the stack’s Resources tab to see the physical IDs of the various components set up by these stacks.
With setup complete, you can log in to the Amazon Redshift cluster and run some basic commands to test it.
Access the Amazon Redshift cluster using the Amazon Redshift query editor
Amazon Redshift allows you to query the cluster right from the console. The following instructions assume that you have permission to access Amazon Redshift query editor.
- From your cluster on the Amazon Redshift console, choose Query data and then choose Query in query editor V2.

An editor opens that allows you to run queries when connected to the database.
- Choose your cluster in the query editor.
- When prompted, enter the database name and user name.
- Choose Create connection to connect to the database.

After you’re connected to the database, you can see the database name and user in the editor. Let’s run some sample queries:
The following screenshot shows our query results.

Next steps
Before you use the Amazon Redshift cluster to set up your application-related database objects, consider creating the following:
- An application schema
- A user with full access to create and modify objects in the application schema
- A user with read and write access to the application schema
- A user with read-only access to the application schema
Use the primary user that you set up with the Amazon Redshift cluster only for administering the Amazon Redshift cluster. To create and modify application-related database objects, use the user with full access to the application schema. Your application should use the read/write user for storing, updating, deleting, and retrieving data. Any reporting or read-only application should use the read-only user. Granting the minimum privileges required to perform operations is a database security best practice.
You can also take advantage of AWS CloudTrail, AWS Config, and Amazon GuardDuty and configure them for your AWS account according to AWS security best practices. These services help you monitor activity in your AWS account; assess, audit, and evaluate the configurations of your AWS resources; monitor malicious or unauthorized behavior; and detect security threats against your resources.
Clean up
Some of the AWS resources deployed by the CloudFormation stacks in this post incur a cost as long as you continue to use them.
You can delete the CloudFormation stack to delete all AWS resources created by the stack. To clean up all your stacks, use the CloudFormation console to remove the CloudFormation stacks that you created in reverse order.
- On the Stacks page on the AWS CloudFormation console, choose the stack to delete.
The stack must be currently running.
- In the stack details pane, choose Delete.
- Choose Delete stack when prompted.
After stack deletion begins, you can’t stop it. The stack proceeds to the DELETE_IN_PROGRESS state. When the stack deletion is complete, the stack changes to the DELETE_COMPLETE state. The AWS CloudFormation console doesn’t display stacks in the DELETE_COMPLETE state by default. To display deleted stacks, you must change the stack view filter. For more information, see Viewing deleted stacks on the AWS CloudFormation console.
If the delete fails, the stack enters the DELETE_FAILED state. For solutions, see Delete stack fails.
Summary
In this post, you learned how to automate the creation of an Amazon Redshift cluster and required AWS infrastructure based on AWS security and high availability best practices using AWS CloudFormation. We hope you find the sample CloudFormation templates helpful, and we encourage you to use and customize them to support your business needs.
For next steps, refer to the blog Automate Amazon Redshift Cluster management operations using AWS CloudFormation on how to use AWS CloudFormation and automate some of the most common Amazon Redshift cluster management operations.
If you have any comments or questions about this post, please use the comments section.
About the Authors
 Manash Deb is a Software Development Engineer in the AWS Directory Service team. He has worked on building end-to-end applications in different database and technologies for over 15 years. He loves to learn new technologies and solving, automating, and simplifying customer problems on AWS.
Manash Deb is a Software Development Engineer in the AWS Directory Service team. He has worked on building end-to-end applications in different database and technologies for over 15 years. He loves to learn new technologies and solving, automating, and simplifying customer problems on AWS.
 Sudhir Gupta is a Sr. Analytics Specialist Partner Solutions Architect, where he helps AWS partners and customers design, implement, and migrate database and analytic workloads to AWS.
Sudhir Gupta is a Sr. Analytics Specialist Partner Solutions Architect, where he helps AWS partners and customers design, implement, and migrate database and analytic workloads to AWS.
 Milind Oke is an Analytics Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift. He is focused on helping customers design and build enterprise-scale, well-architected analytics and decision support platforms.
Milind Oke is an Analytics Specialist Solutions Architect based out of New York. He has been building data warehouse solutions for over 15 years and specializes in Amazon Redshift. He is focused on helping customers design and build enterprise-scale, well-architected analytics and decision support platforms.