AWS Big Data Blog

Author: Vara Bonthu
Vara Bonthu is a dedicated technology professional and Worldwide Tech Leader for Data on EKS, specializing in assisting AWS customers ranging from strategic accounts to diverse organizations. He is passionate about open-source technologies, Data Analytics, AI/ML, and Kubernetes, and boasts an extensive background in development, DevOps, and architecture. Vara's primary focus is on building highly scalable Data and AI/ML solutions on Kubernetes platforms, helping customers harness the full potential of cutting-edge technology for their data-driven pursuits.
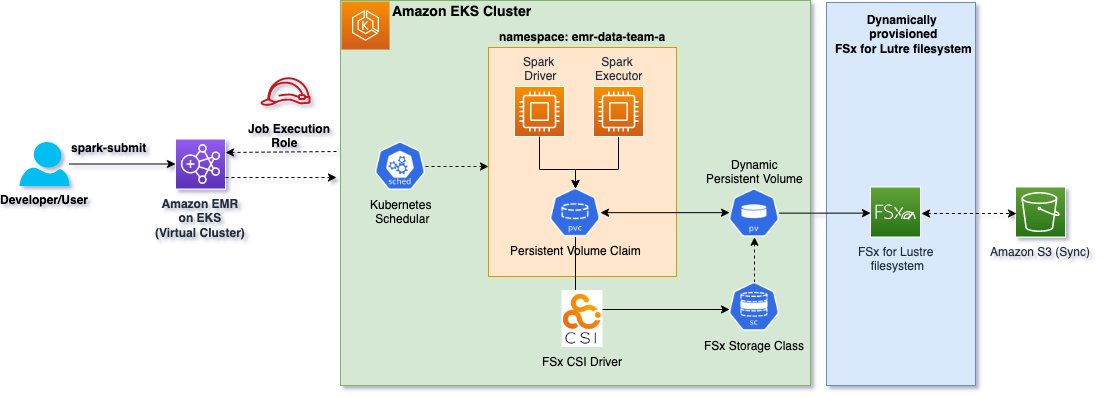
Run Apache Spark with Amazon EMR on EKS backed by Amazon FSx for Lustre storage
September 2023: This post was reviewed and updated for accuracy to reflect recent improvements and changes. Traditionally, Spark workloads have been run on a dedicated setup like a Hadoop stack with YARN or MESOS as a resource manager. Starting from Apache Spark 2.3, Spark added support for Kubernetes as a resource manager. The new Kubernetes […]

Building a serverless data quality and analysis framework with Deequ and AWS Glue
March 2023: You can now use AWS Glue Data Quality to measure and manage the quality of your data. AWS Glue Data Quality is built on DeeQu and it offers a simplified user experience for customers who want to this open-source package. Refer to the blog and documentation for additional details. With ever-increasing amounts of data […]