AWS Big Data Blog
Category: AWS Lake Formation

Discover metadata with AWS Lake Formation: Part 2
In this post, you will learn how to use the metadata search capabilities of Lake Formation. By defining specific user permissions, Lake Formation allows you to grant and revoke access to metadata in the Data Catalog as well as the underlying data stored in S3.

Discovering metadata with AWS Lake Formation: Part 1
In this post, you will create and edit your first data lake using the Lake Formation. You will use the service to secure and ingest data into an S3 data lake, catalog the data, and customize the metadata of the data sources. In part 2 of this series, we will show you how to discover your data by using the metadata search capabilities of Lake Formation.

Getting started with AWS Lake Formation
June 2024: This post was reviewed and updated for accuracy. AWS Lake Formation enables you to set up a secure data lake. A data lake is a centralized, curated, and secured repository storing all your structured and unstructured data, at any scale. You can store your data as-is, without having first to structure it. And […]

Integrate and deduplicate datasets using AWS Lake Formation FindMatches
AWS Lake Formation FindMatches is a new machine learning (ML) transform that enables you to match records across different datasets as well as identify and remove duplicate records, with little to no human intervention. FindMatches is part of Lake Formation, a new AWS service that helps you build a secure data lake in a few simple steps.
To use FindMatches, you don’t have to write code or know how ML works. Your data doesn’t have to include a unique identifier, nor must fields match exactly.
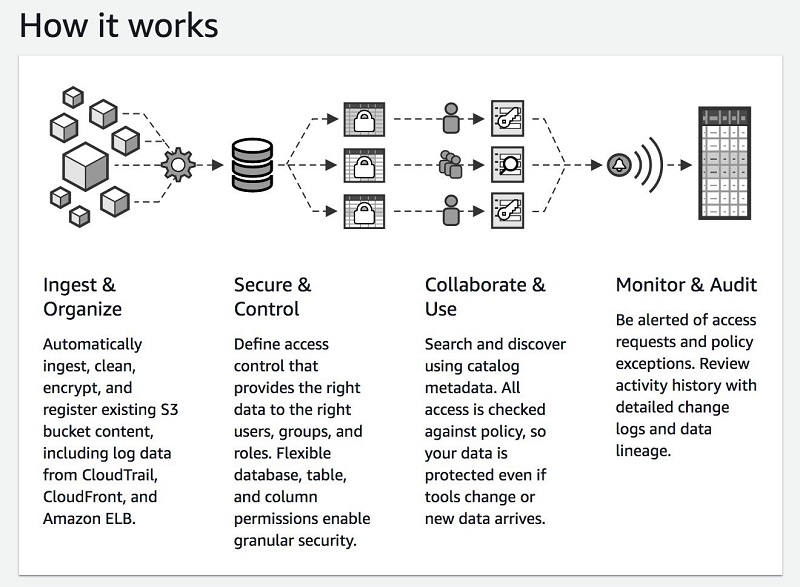
Build, secure, and manage data lakes with AWS Lake Formation
A data lake is a centralized store of a variety of data types for analysis by multiple analytics approaches and groups. Many organizations are moving their data into a data lake. In this post, we explore how you can use AWS Lake Formation to build, secure, and manage data lakes.