AWS Big Data Blog
How Buildkite Operates Test Analytics at Massive Scale with Amazon MSK and Amazon Managed Service for Apache Flink
When engineering teams at Slack, Reddit, Canva, Airbnb, Shopify, and Uber need to ship code with confidence, they rely on Buildkite. As a CI/CD platform, Buildkite orchestrates complex build, test, and deployment pipelines for some of the most demanding engineering organizations in the world. It handles everything from routine code commits to artificial intelligence (AI) model-training workloads, processing over 50 billion requests per month.
At the heart of Buildkite’s test orchestration portfolio is Test Engine, a specialized analytics product designed to help engineering teams understand and optimize their test suites at scale. Test Engine aggregates results across thousands of builds, flags flaky tests, runs parallel test execution across machine fleets, and delivers interactive analytics on test execution data. It supports arbitrary metadata tagging for dimensions like instance type, architecture, language version, cloud provider, and feature flags.
The challenge? Delivering all of this in real time, across multiple enterprise tenants, at a volume that would stress even the most robust data infrastructure. In this post, we explore how Buildkite uses Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink to power Test Engine’s streaming-first analytics architecture at scale.
The problem: When scale breaks traditional architectures
Buildkite’s Test Engine must ingest and serve analytics on test telemetry from thousands of distributed pipelines simultaneously, for multiple enterprise customers. The scale is unforgiving: 50 billion test executions per month, 500K events per second at peak ingestion, and webhook payloads reaching 21 MB.
The architectural evolution and its limits
The original Rails and PostgreSQL stack couldn’t sustain this growth. In 2024, the team re-architected around a distributed streaming layer, a stateful stream processor for pre-aggregations, and multiple specialized stores: a key-value store for fast lookups, a relational database for pre-computed aggregates, and an open table format (Iceberg) with a distributed query engine (Trino) for flexible querying.
Yet the core tension remained unsolved. Enterprise customers demanded interactive, arbitrary slicing of billions of records across high-cardinality dimensions, not canned reports. The stream processor couldn’t handle ad hoc aggregations at query time. The key-value store was blind to analytical queries. The distributed query engine offered flexibility but was too slow for interactive use.
The result was a system that was expensive and operationally complex. It included nine relational database clusters, sprawling ETL pipelines, and 24/7 pre-aggregation jobs running regardless of demand. It still couldn’t deliver the one thing customers needed most: fast, flexible, interactive analytics at scale.
Architecture and implementation: MSK and Amazon Managed Service for Apache Flink as the streaming backbone
The solution Buildkite arrived at centers on Amazon Managed Streaming for Apache Kafka (Amazon MSK) and Amazon Managed Service for Apache Flink as the real-time data streaming and processing layers, decoupling high-throughput ingestion from downstream analytics.
The data pipeline
The following diagram shows the end-to-end data flow from CI/CD agents through Amazon MSK and Amazon Managed Service for Apache Flink to the analytics layer.
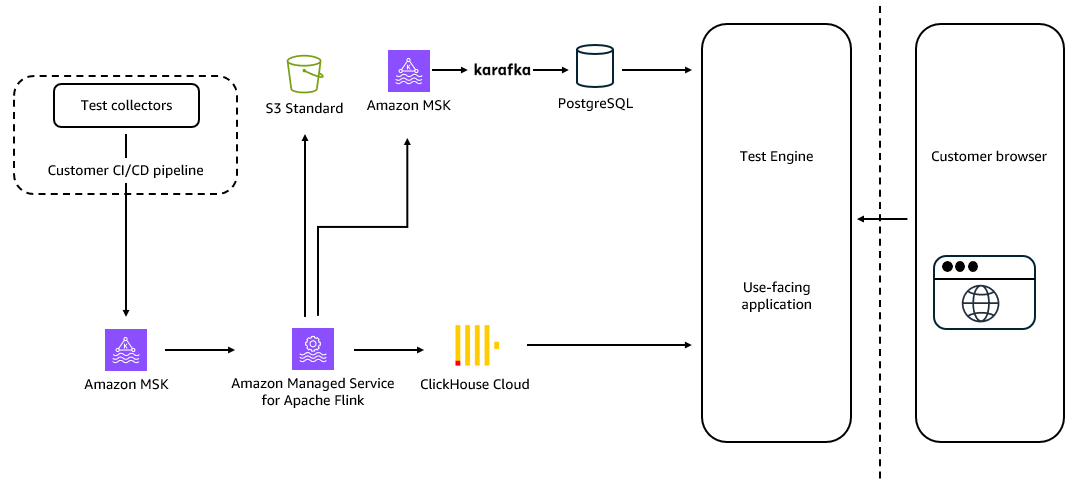
Amazon MSK sits at the critical junction between data producers (the distributed CI/CD agents and test collectors running across customer infrastructure) and the downstream processing and analytics layers. Amazon Managed Service for Apache Flink then transforms those raw event streams into enriched, queryable data before it reaches the analytics store.
High-throughput ingestion from CI/CD pipelines
Amazon MSK’s role begins at ingestion. Test collectors embedded in CI/CD pipelines publish test execution events directly to Kafka topics. The existing Amazon MSK cluster handles between 5 MB/sec and 100 MB/sec of inbound data under normal operating conditions. The architecture is designed to absorb the significant variance inherent in CI/CD workloads, where pipeline activity is bursty and correlated with engineering team working hours across global time zones.
When the Buildkite project was initiated, MSK Express Brokers were not yet available, leading the team to adopt MSK Tiered Storage as the primary mechanism for scaling and recovery. With MSK Express Brokers now generally available, the team is evaluating a migration of its most critical log ingestion workload, which sustains up to 1 GB/s at peak ingestion. MSK Express Brokers bring automatic storage scaling with zero storage management overhead, up to 20x faster scaling and 90% faster broker recovery, 3x higher per-broker throughput, 5x more partitions per broker, and built-in Intelligent Rebalancing.
Real-time stream processing with Amazon Managed Service for Apache Flink
Sitting between Amazon MSK and the analytics layer, Amazon Managed Service for Apache Flink acts as the stateful stream processing engine that transforms raw event streams before they reach downstream systems. Buildkite selected Flink for its exactly-once processing, mature stateful computation model, and deep Kafka integration. Handling sustained peaks of over 25,000 events per second, Amazon Managed Service for Apache Flink eliminates the operational overhead of cluster provisioning, version upgrades, checkpointing, and job recovery. This frees engineering teams to focus on application logic.
Amazon Managed Service for Apache Flink powers key stateful processing tasks, including flaky test detection through time-windowed pattern matching, enriching execution events with pipeline and customer metadata, and routing processed data to downstream systems such as ClickHouse for analytics, PostgreSQL for operational workloads, and Amazon Simple Storage Service (Amazon S3) for long-term archival.
Reliability and fault tolerance
Amazon MSK’s three-replica configuration ensures that no single broker failure can cause data loss or ingestion interruption. Combined with flexible data retention, the architecture provides a meaningful replay window. If a downstream consumer (Amazon Managed Service for Apache Flink, ClickHouse, or another service) experiences an outage, it can resume processing from its last committed offset without data loss.
During the migration to the current architecture, Buildkite employed a dual-write strategy: simultaneously writing to both the existing PostgreSQL pipeline and the new Amazon MSK/ClickHouse path. This approach allowed the team to validate data consistency and gradually shift traffic without risking customer-facing disruption. This pattern speaks to the operational maturity Amazon MSK provides.
Operational efficiency gains
The shift to a streaming-first architecture, combined with the downstream simplification of the analytics engine, produced significant operational improvements:
- Flink workloads reduced by 60%+: Eliminating pre-aggregation jobs that ran continuously regardless of demand.
- Key/value store completely retired: Amazon MSK’s buffering capability, combined with ClickHouse’s query performance, eliminated the need for a separate fast-lookup store.
- PostgreSQL capacity cut in half: Nine separate database clusters consolidated and right-sized.
- Thousands of lines of application code deleted: Simpler architecture means less ETL code, fewer failure modes, and faster onboarding for new engineers.
Platform performance at a glance
| Metric | Value |
| Monthly test executions (for test engine platform) | 50 billion (4x growth from 3B) |
| Sustained peak ingestion | 500K events/second |
| Total records in analytics store | 200 billion |
| Log ingestion requests | 70,000+ per second |
| Peak webhook throughput | 1.7 GB/second |
| MSK inbound throughput range | 5 MB/sec – 100 MB/sec |
Business and developer impact
The technical architecture ultimately exists to serve one purpose: helping developers ship better software faster. The streaming-first architecture built on Amazon MSK and Amazon Managed Service for Apache Flink delivers on that promise across four dimensions.
On-demand analytics replaced pre-computed reports. Customers can now interactively slice and dice 70 billion records across arbitrary metadata dimensions. They get answers to queries like “Show me P50 test durations by instance type and architecture for the last 30 days” in seconds, not hours. Real-time log streaming through the “live tail” feature means developers no longer wait for a build to complete before diagnosing failures. At 25,000 events per second, this experience scales across thousands of concurrent enterprise pipelines without degradation.
Smarter test intelligence comes from Amazon Managed Service for Apache Flink’s stateful flaky test detection: when a test begins exhibiting intermittent failure patterns, Amazon Managed Service for Apache Flink identifies it as it happens, not after the fact. This is what separates a proactive analytics platform from a reactive one. It requires publishing data to Kafka, processing with Flink, and letting ClickHouse handle the complex read requests.
Conclusion: Streaming as a strategic foundation
Buildkite’s journey from a Rails/Postgres monolith to a streaming-first analytics platform reflects a pattern increasingly common among enterprise SaaS companies: a reliable, high-throughput streaming and processing layer is not an optimization. It is a prerequisite for operating at scale.
Amazon MSK and Amazon Managed Service for Apache Flink form the backbone that helps Buildkite ingest 50 billion test executions per month, serve real-time interactive analytics to enterprise customers, and do so at lower cost than the more complex architecture it replaced. Amazon MSK handles durable, elastic event buffering. Amazon Managed Service for Apache Flink transforms raw streams into enriched, queryable data. Together they absorb the operational complexity that would otherwise consume engineering capacity.
For platform engineers evaluating streaming infrastructure for multi-tenant SaaS workloads, the signal is clear: invest in the streaming backbone early, and let managed services handle the operational complexity.
To learn more about Amazon MSK and Amazon Managed Service for Apache Flink, visit aws.amazon.com/msk and aws.amazon.com/managed-service-apache-flink.