AWS Big Data Blog
How Goldman Sachs built persona tagging using Apache Flink on Amazon EMR
The Global Investment Research (GIR) division at Goldman Sachs is responsible for providing research and insights to the firm’s clients in the equity, fixed income, currency, and commodities markets. One of the long-standing goals of the GIR team is to deliver a personalized experience and relevant research content to their research users. Previously, in order to customize the user experience for their various types of clients, GIR offered a few distinct editions of their research site that were provided to users based on broad criteria. However, GIR did not have any way to create a personally curated content flow at the individual user level. To provide this functionality, GIR wanted to implement a system to actively filter the content that is recommended to their users on a per-user basis, keyed on characteristics such as the user’s job title or working region. Having this kind of system in place would both improve the user experience and simplify the workflows of GIR’s research users, by reducing the amount of time and effort required to find the research content that they need.
The first step towards achieving this is to directly classify GIR’s research users based on their profiles and readership. To that end, GIR created a system to tag users with personas. Each persona represents a type or classification that individual users can be tagged with, based on certain criteria. For example, GIR has a series of personas for classifying a user’s job title, and a user tagged with the “Chief Investment Officer” persona will have different research content highlighted and have a different site experience compared to one that is tagged with the “Corporate Treasurer” persona. This persona-tagging system can both efficiently carry out the data operations required for tagging users, as well as have new personas created as needed to fit use cases as they emerge.
In this post, we look at how GIR implemented this system using Amazon EMR.
Challenge
Given the number of contacts (i.e., millions) and the growing number of publications maintained in GIR’s research data store, creating a system for classifying users and recommending content is a scalability challenge. A newly created persona could potentially apply to almost every contact, in which case a tagging operation would need to be performed on several million data entries. In general, the number of contacts, the complexity of the data stored per contact, and the amount of criteria for personalization can only increase. To future-proof their workflow, GIR needed to ensure that their solution could handle the processing of large amounts of data as an expected and frequent case.
GIR’s business goal is to support two kinds of workflows for classification criteria: ad hoc and ongoing. An ad hoc criteria causes users that currently fit the defining criteria condition to immediately get tagged with the required persona, and is meant to facilitate the one-time tagging of specific contacts. On the other hand, an ongoing criteria is a continuous process that automatically tags users with a persona if a change to their attributes causes them to fit the criteria condition. The following diagram illustrates the desired personalization flow:

In the rest of this post, we focus on the design and implementation of GIR’s ad hoc workflow.
Apache Flink on Amazon EMR
To meet GIR’s scalability demands, they determined that Amazon EMR was the best fit for their use case, being a managed big data platform meant for processing large amounts of data using open source technologies such as Apache Flink. Although GIR evaluated a few other options that addressed their scalability concerns (such as AWS Glue), GIR chose Amazon EMR for its ease of integration into their existing systems and possibility to be adapted for both batch and streaming workflows.
Apache Flink is an open source big data distributed stream and batch processing engine that efficiently processes data from continuous events. Flink offers exactly-once guarantees, high throughput and low latency, and is suited for handling massive data streams. Also, Flink provides many easy-to-use APIs and mitigates the need for the programmer to worry about failures. However, building and maintaining a pipeline based on Flink comes with operational overhead and requires considerable expertise, in addition to provisioning physical resources.
Amazon EMR empowers users to create, operate, and scale big data environments such as Apache Flink quickly and cost-effectively. We can optimize costs by using Amazon EMR managed scaling to automatically increase or decrease the cluster nodes based on workload. In GIR’s use case, their users need to be able to trigger persona-tagging operations at any time, and require a predictable completion time for their jobs. For this, GIR decided to launch a long-running cluster, which allows multiple Flink jobs to be submitted simultaneously to the same cluster.
Ad hoc persona-tagging infrastructure and workflow
The following diagram illustrates the architecture of GIR’s ad hoc persona-tagging workflow on the AWS Cloud.
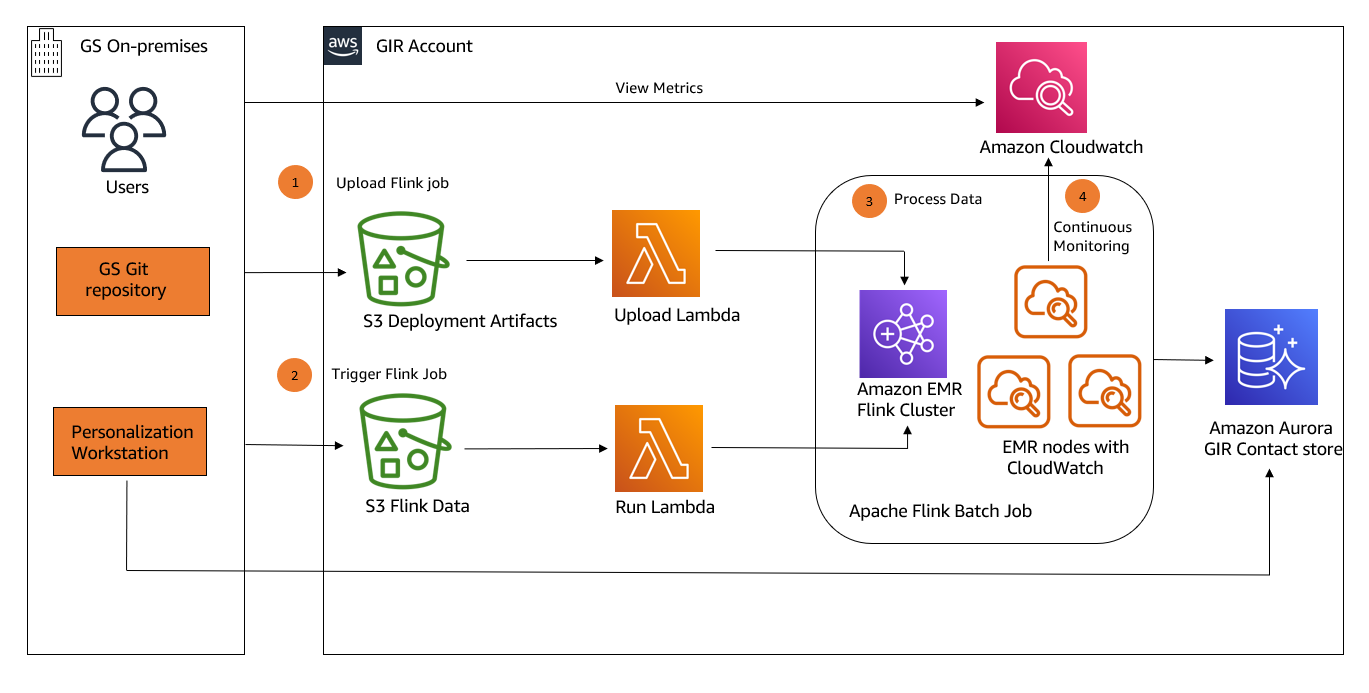
This is a broad overview, and the specifics of networking and security between components are out of scope for this post.
At a high level, we can discuss GIR’s workflow in four parts:
- Upload the Flink job artifacts to the EMR cluster.
- Trigger the Flink job.
- Within the Flink job, transform and then store user data.
- Continuous monitoring.
You can interact with Flink on Amazon EMR via the Amazon EMR console or the AWS Command Line Interface (AWS CLI). After launching the cluster, GIR used the Flink API to interact with and submit work to the Flink application. The Flink API provided a bit more functionality and was much easier to invoke from an AWS Lambda application.
The end goal of the setup is to have a pipeline where GIR’s internal users can freely make requests to update contact data (which in this use case is tagging or untagging contacts with various personas), and then have the updated contact data uploaded back to the GIR contact store.
Upload the Flink job artifacts to Amazon EMR
GIR has a GitLab project on-premises for managing the contents of their Flink job. To trigger the first part of their workflow and deploy a new version of the Flink job onto the cluster, a GitLab pipeline is run that first creates a .zip file containing the Flink job JAR file, properties, and config files.

The preceding diagram depicts the sequence of events that occurs in the job upload:
- The GitLab pipeline is manually triggered when a new Flink job should be uploaded. This transfers the .zip file containing the Flink job to an Amazon Simple Storage Service (Amazon S3) bucket on the GIR AWS account, labeled as “S3 Deployment artifacts”.
- A Lambda function (“Upload Lambda”) is triggered in response to the create event from Amazon S3.
- The function first uploads the Flink job JAR to the Amazon EMR Flink cluster, and retrieves the application ID for the Flink session.
- Finally, the function uploads the application properties file to a specific S3 bucket (“S3 Flink Job Properties”).
Trigger the Flink job
The second part of the workflow handles the submission of the actual Flink job to the cluster when job requests are generated. GIR has a user-facing web app called Personalization Workbench that provides the UI for carrying out persona-tagging operations. Admins and internal Goldman Sachs users can construct requests to tag or untag contacts with personas via this web app. When a request is submitted, a data file is generated that contains the details of the request.

The steps of this workflow are as follows:
- Personalization Workstation submits the details of the job request to the Flink Data S3 bucket, labeled as “S3 Flink data”.
- A Lambda function (“Run Lambda”) is triggered in response to the create event from Amazon S3.
- The function first reads the job properties file uploaded in the previous step to get the Flink job ID.
- Finally, the function makes an API call to run the required Flink job.
Process data
Contact data is processed according to the persona-tagging requests, and the transformed data is then uploaded back to the GIR contact store.

The steps of this workflow are as follows:
- The Flink job first reads the application properties file that was uploaded as part of the first step.
- Next, it reads the data file from the second workflow that contains the contact and persona data to be updated. The job then carries out the processing for the tagging or untagging operation.
- The results are uploaded back to the GIR contact store.
- Finally, both successful and failed requests are written back to Amazon S3.
Continuous monitoring
The final part of the overall workflow involves continuous monitoring of the EMR cluster in order to ensure that GIR’s tagging workflow is stable and that the cluster is in a healthy state. To ensure that the highest level of security is maintained with their client data, GIR wanted to avoid unconstrained SSH access to their AWS resources. Being constrained from accessing the EMR cluster’s primary node directly via SSH meant that GIR initially had no visibility into the EMR primary node logs or the Flink web interface.
By default, Amazon EMR archives the log files stored on the primary node to Amazon S3 at 5-minute intervals. Because this pipeline serves as a central platform for processing many ad hoc persona-tagging requests at a time, it was crucial for GIR to build a proper continuous monitoring system that would allow them to promptly diagnose any issues with the cluster.
To accomplish this, GIR implemented two monitoring solutions:
- GIR installed an Amazon CloudWatch agent onto every node of their EMR cluster via bootstrap actions. The CloudWatch agent collects and publishes Flink metrics to CloudWatch under a custom metric namespace, where they can be viewed on the CloudWatch console. GIR configured the CloudWatch agent configuration file to capture relevant metrics, such as CPU utilization and total running EMR instances. The result is an EMR cluster where metrics are emitted to CloudWatch at a much faster rate than waiting for periodic S3 log flushes.
- They also enabled the Flink UI in read-only mode by fronting the cluster’s primary node with a network load balancer and establishing connectivity from the Goldman Sachs on-premises network. This change allowed GIR to gain direct visibility into the state of their running EMR cluster and in-progress jobs.
Observations, challenges faced, and lessons learned
The personalization effort marked the first-time adoption of Amazon EMR within GIR. To date, hundreds of personalization criteria have been created in GIR’s production environment. In terms of web visits and clickthrough rate, site engagement with GIR personalized content has gradually increased since the implementation of the persona-tagging system.
GIR faced a few noteworthy challenges during development, as follows:
Restrictive security group rules
By default, Amazon EMR creates its security groups with rules that are less restrictive, because Amazon EMR can’t anticipate the specific custom settings for ingress and egress rules required by individual use cases. However, proper management of the security group rules is critical to protect the pipeline and data on the cluster. GIR used custom-managed security groups for their EMR cluster nodes and included only the needed security group rules for connectivity, in order to fulfill this stricter security posture.
Custom AMI
There were challenges in ensuring that the required packages were available when using custom Amazon Linux AMIs for Amazon EMR. As part of Goldman Sachs development SDLC controls, any Amazon Elastic Compute Cloud (Amazon EC2) instances on Goldman Sachs-owned AWS accounts are required to use internal Goldman Sachs-created AMIs. When GIR began development, the only compliant AMI that was available under this control was a minimal AMI based on the publicly available Amazon Linux 2 minimal AMI (amzn2-ami-minimal*-x86_64-ebs). However, Amazon EMR recommends using the full default Amazon 2 Linux AMI because it has all the necessary packages pre-installed. This resulted in various start up errors with no clear indication of the missing libraries.
GIR worked with AWS support to identify and resolve the issue by comparing the minimal and full AMIs, and installing the 177 missing packages individually (see the appendix for the full list of packages). In addition, various AMI-related files had been set to read-only permissions by the Goldman Sachs internal AMI creation process. Restoring these permissions to full read/write access allowed GIR to successfully start up their cluster.
Stalled Flink jobs
During GIR’s initial production rollout, GIR experienced an issue where their EMR cluster failed silently and caused their Lambda functions to time out. On further debugging, GIR found this issue to be related to an Akka quarantine-after-silence timeout setting. By default, it was set to 48 hours, causing the clusters to refuse more jobs after that time. GIR found a workaround by setting the value of akka.jvm-exit-on-fatal-error to false in the Flink config file.
Conclusion
In this post, we discussed how the GIR team at Goldman Sachs set up a system using Apache Flink on Amazon EMR to carry out the tagging of users with various personas, in order to better curate content offerings for those users. We also covered some of the challenges that GIR faced with the setup of their EMR cluster. This represents an important first step in providing GIR’s users with complete personalized content curation based on their individual profiles and readership.
Acknowledgments
The authors would like to thank the following members of the AWS and GIR teams for their close collaboration and guidance on this post:
- Elizabeth Byrnes, Managing Director, GIR
- Moon Wang, Managing Director, GIR
- Ankur Gurha, Vice President, GIR
- Jeremiah O’Connor, Solutions Architect, AWS
- Ley Nezifort, Associate, GIR
- Shruthi Venkatraman, Analyst, GIR
About the Authors
 Balasubramanian Sakthivel is a Vice President at Goldman Sachs in New York. He has more than 16 years of technology leadership experience and worked on many firmwide entitlement, authentication and personalization projects. Bala drives the Global Investment Research division’s client access and data engineering strategy, including architecture, design and practices to enable the lines of business to make informed decisions and drive value. He is an innovator as well as an expert in developing and delivering large scale distributed software that solves real world problems, with demonstrated success envisioning and implementing a broad range of highly scalable platforms, products and architecture.
Balasubramanian Sakthivel is a Vice President at Goldman Sachs in New York. He has more than 16 years of technology leadership experience and worked on many firmwide entitlement, authentication and personalization projects. Bala drives the Global Investment Research division’s client access and data engineering strategy, including architecture, design and practices to enable the lines of business to make informed decisions and drive value. He is an innovator as well as an expert in developing and delivering large scale distributed software that solves real world problems, with demonstrated success envisioning and implementing a broad range of highly scalable platforms, products and architecture.
 Victor Gan is an Analyst at Goldman Sachs in New York. Victor joined the Global Investment Research division in 2020 after graduating from Cornell University, and has been responsible for developing and provisioning cloud infrastructure for GIR’s user entitlement systems. He is focused on learning new technologies and streamlining cloud systems deployments.
Victor Gan is an Analyst at Goldman Sachs in New York. Victor joined the Global Investment Research division in 2020 after graduating from Cornell University, and has been responsible for developing and provisioning cloud infrastructure for GIR’s user entitlement systems. He is focused on learning new technologies and streamlining cloud systems deployments.
 Manjula Nagineni is a Solutions Architect with AWS based in New York. She works with major Financial service institutions, architecting, and modernizing their large-scale applications while adopting AWS cloud services. She is passionate about designing big data workloads cloud-natively. She has over 20 years of IT experience in Software Development, Analytics and Architecture across multiple domains such as finance, manufacturing and telecom.
Manjula Nagineni is a Solutions Architect with AWS based in New York. She works with major Financial service institutions, architecting, and modernizing their large-scale applications while adopting AWS cloud services. She is passionate about designing big data workloads cloud-natively. She has over 20 years of IT experience in Software Development, Analytics and Architecture across multiple domains such as finance, manufacturing and telecom.
Appendix
GIR ran the following command to install the missing AMI packages: