AWS Big Data Blog
How ironSource built a multi-purpose data lake with Upsolver, Amazon S3, and Amazon Athena
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
This is a guest post co-written by Seva Feldman at ironSource Mobile and Eran Levy at Upsolver. ironSource, in their own words, is the leading in-app monetization and video advertising platform, making free-to-play and free-to-use possible for over 1.5B people around the world. ironSource helps app developers take their apps to the next level, including the industry’s largest in-app video network. Over 80,000 apps use ironSource technologies to grow their businesses.
The massive scale in which ironSource operates across its various monetization platforms—including apps, video, and mediation—leads to millions of end-devices generating massive amounts of streaming data. They need to collect, store, and prepare data to support multiple use cases while minimizing infrastructure and engineering overheads.
This post discusses the following:
- Why ironSource opted for a data lake architecture based on Amazon S3.
- How ironSource built the data lake using Upsolver.
- How to create outputs to analytic services such as Amazon Athena, Amazon OpenSearch Service, and Tableau.
- The benefits of this solution.
Advantages of a data lake architecture
After working for several years in a database-focused approach, the rapid growth in ironSource’s data made their previous system unviable from a cost and maintenance perspective. Instead, they adopted a data lake architecture, storing raw event data on object storage, and creating customized output streams that power multiple applications and analytic flows.
Why ironSource chose an AWS data lake
A data lake was the right solution for ironSource for the following reasons:
- Scale – ironSource processes 500K events per second and over 20 billion events daily. The ability to store near-infinite amounts of data in S3 without preprocessing the data is crucial.
- Flexibility – ironSource uses data to support multiple business processes. Because they need to feed the same data into multiple services to provide for different use cases, the company needed to bypass the rigidity and schema limitations entailed by a database approach. Instead, they store all the original data on S3 and create ad-hoc outputs and transformations as needed.
- Resilience – Because all historical data is on S3, recovery from failure is easier, and errors further down the pipeline are less likely to affect production environments.
Why ironSource chose Upsolver
Upsolver’s streaming data platform automates the coding-intensive processes associated with building and managing a cloud data lake. Upsolver enables ironSource to support a broad range of data consumers and minimize the time DevOps engineers spend on data plumbing by providing a GUI-based, self-service tool for ingesting data, preparing it for analysis, and outputting structured tables to various query services.
Key benefits include the following:
- Self-sufficiency for data consumers – As a self-service platform, Upsolver allows BI developers, Ops, and software teams to transform data streams into tabular data without writing code.
- Improved performance – Because Upsolver stores files in optimized Parquet storage on S3, ironSource benefits from high query performance without manual performance tuning.
- Elastic scaling – ironSource is in hyper-growth, so needs elastic scaling to handle increases in inbound data volume and peaks throughout the week, reprocessing of events from S3, and isolation between different groups that use the data.
- Data privacy – Because ironSource’s VPC deploys Upsolver with no access from outside, there is no risk to sensitive data.
This post shows how ironSource uses Upsolver to build, manage, and orchestrate its data lake with minimal coding and maintenance.
Solution Architecture
The following diagram shows the architecture ironSource uses:

Streaming data from Kafka to Upsolver and storing on S3
Apache Kafka streams data from ironSource’s mobile SDK at a rate of up to 500K events per second. Upsolver pulls data from Kafka and stores it in S3 within a data lake architecture. It also keeps a copy of the raw event data while making sure to write each event exactly one time, and stores the same data as Parquet files that are optimized for consumption.
Building the input stream in Upsolver:
Using the Upsolver GUI, ironSource connects directly to the relevant Kafka topics and writes them to S3 precisely one time. See the following screenshot.

After the data is stored in S3, ironSource can proceed to operationalize the data using a wide variety of databases and analytic tools. The next steps cover the most prominent tools.
Output to Athena
To understand production issues, developers and product teams need access to data. These teams can work with the data directly and answer their own questions by using Upsolver and Athena.
Upsolver simplifies and automates the process of preparing data for consumption in Athena, including compaction, compression, partitioning, and creating and managing tables in the AWS Glue Data Catalog. ironSource’s DevOps teams save hundreds of hours on pipeline engineering. Upsolver’s GUI creates each table one time, and from that point onwards, data consumers are entirely self-sufficient. To ensure queries in Athena run fast and at minimal cost, Upsolver also enforces performance-tuning best practices as data is ingested and stored on S3. For more information, see Top 10 Performance Tuning Tips for Amazon Athena.
Athena’s serverless architecture further compliments this independence, which means there’s no infrastructure to manage and analysts don’t need DevOps to use Amazon Redshift or query clusters for each new question. Instead, analysts can indicate the data they need and get answers.
Sending tables to Athena in Upsolver
In Upsolver, you can declare tables with associated schema using SQL or the built-in GUI. You can expose these tables to Athena through the AWS Glue Data Catalog. Upsolver stores Parquet files in S3 and creates the appropriate table and partition information in the AWS Glue Data Catalog by using Create and Alter DDL statements. You can also edit these tables with Upsolver Output to add, remove, or change columns. Upsolver automates the process of recreating table data on S3 and altering the metadata in the AWS Glue Data Catalog.
Creating the table

Sending the table to Amazon Athena
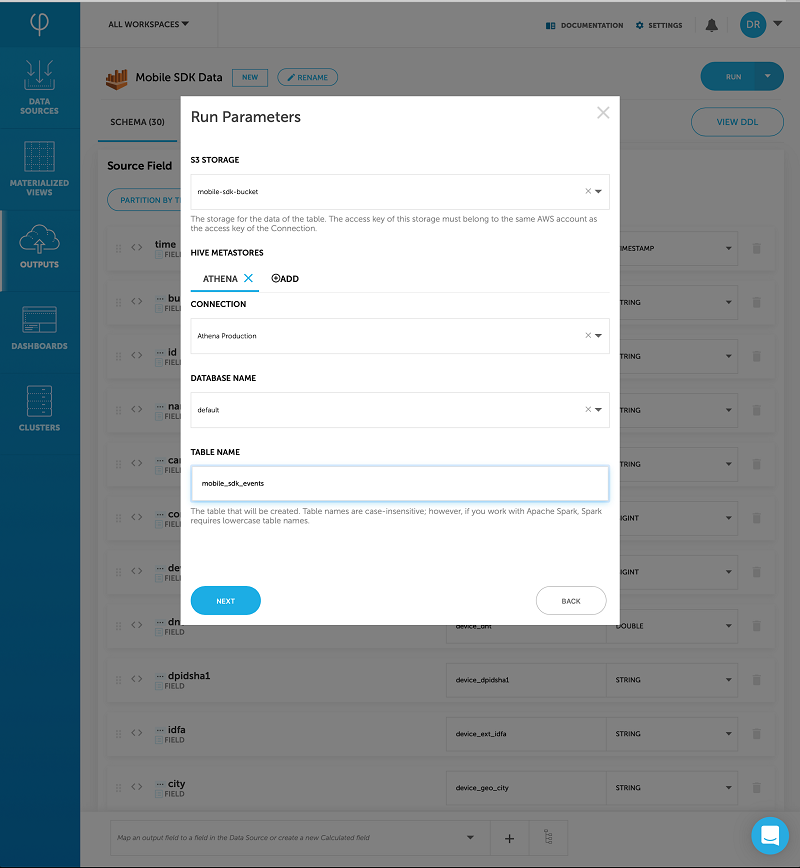
Editing the table option for Outputs

Modifying an existing table in the Upsolver Output

Output to BI platforms
IronSource’s BI analysts use Tableau to query and visualize data using SQL. However, performing this type of analysis on streaming data may require extensive ETL and data preparation, which can limit the scope of analysis and create reporting bottlenecks.
IronSource’s cloud data lake architecture enables BI teams to work with big data in Tableau. They use Upsolver to enrich and filter data and write it to Redshift to build reporting dashboards, or send tables to Athena for ad-hoc analytic queries. Tableau connects natively to both Redshift and Athena, so analysts can query the data using regular SQL and familiar tools, rather than relying on manual ETL processes.
Creating a reduced stream for Amazon OpenSearch Service
Engineering teams at IronSource use Amazon OpenSearch Service to monitor and analyze application logs. However, as with any database, storing raw data in Amazon OpenSearch Service is expensive and can lead to production issues.
Because a large part of these logs are duplicates, Upsolver deduplicates the data. This reduces Amazon OpenSearch Service costs and improves performance. Upsolver cuts down the size of the data stored in Amazon OpenSearch Service by 70% by aggregating identical records. This makes it viable and cost-effective despite generating a high volume of logs.
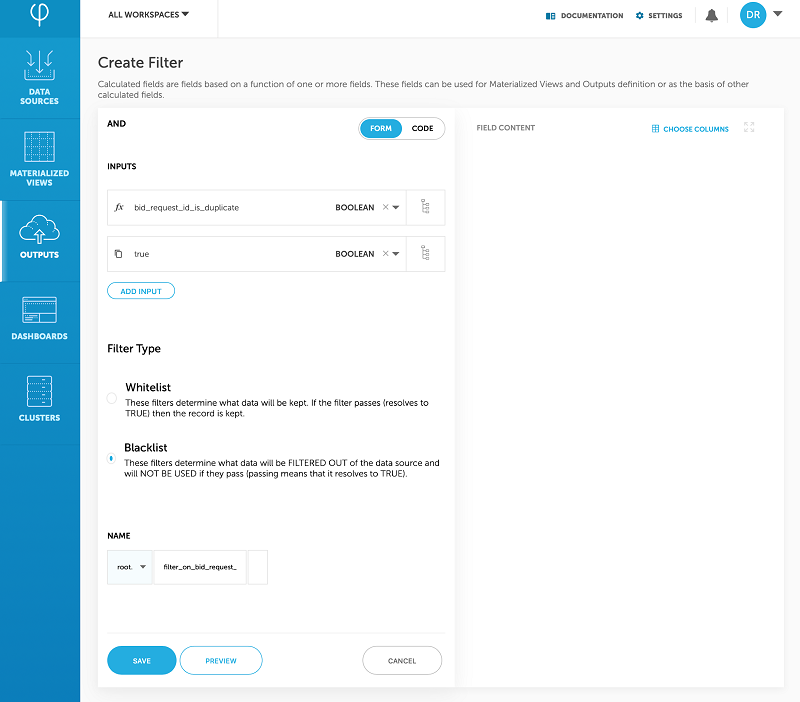
To do this, Upsolver adds a calculated field to the event stream, which indicates whether a particular log is a duplicate. If so, it filters the log out of the stream that it sends to Amazon OpenSearch Service.
Creating the calculated field

Filtering using the calculated field
Conclusion
Self-sufficiency is a big part of ironSource’s development ethos. In revamping its data infrastructure, the company sought to create a self-service environment for dev and BI teams to work with data, without becoming overly reliant on DevOps and data engineering. Data engineers can now focus on features rather than building and maintaining code-driven ETL flows.
ironSource successfully built an agile and versatile architecture with Upsolver and AWS data lake tools. This solution enables data consumers to work independently with data, while significantly improving data freshness, which helps power both the company’s internal decision-making and external reporting.
Some of the results in numbers include:
- Thousands of engineering hours saved – ironSource’s DevOps and data engineers save thousands of hours that they would otherwise spend on infrastructure by replacing manual, coding-intensive processes with self-service tools and managed infrastructure.
- Fees reduction – Factoring infrastructure, workforce, and licensing costs, Upsolver significantly reduces ironSource’s total infrastructure costs.
- 15-minute latency from Kafka to end-user – Data consumers can respond and take action with near real-time data.
- 9X increase in scale – Currently at 0.5M incoming events/sec and 3.5M outgoing events/sec.
“It’s important for every engineering project to generate tangible value for the business,” says Seva Feldman, Vice President of Research and Development at ironSource Mobile. “We want to minimize the time our engineering teams, including DevOps, spend on infrastructure and maximize the time spent developing features. Upsolver has saved thousands of engineering hours and significantly reduced total cost of ownership, which enables us to invest these resources in continuing our hypergrowth rather than data pipelines.”
The content and opinions in this post are those of the third-party author and AWS is not responsible for the content or accuracy of this post.
About the Authors
Seva Feldman is Vice President of R&D at ironSource Mobile. With over two decades of experience senior architecture, DevOps and engineering roles, Seva is an expert in turning operational challenges into opportunities for improvement.
 Eran Levy is the Director of Marketing at Upsolver.
Eran Levy is the Director of Marketing at Upsolver.
 Roy Hasson is the Global Business Development Lead of Analytics and Data Lakes at AWS.. He works with customers around the globe to design solutions to meet their data processing, analytics and business intelligence needs. Roy is big Manchester United fan, cheering his team on and hanging out with his family.
Roy Hasson is the Global Business Development Lead of Analytics and Data Lakes at AWS.. He works with customers around the globe to design solutions to meet their data processing, analytics and business intelligence needs. Roy is big Manchester United fan, cheering his team on and hanging out with his family.