AWS Big Data Blog
How Roche democratized access to data with Google Sheets and Amazon Redshift Data API
This post was co-written with Dr. Yannick Misteli, João Antunes, and Krzysztof Wisniewski from the Roche global Platform and ML engineering team as the lead authors.
Roche is a Swiss multinational healthcare company that operates worldwide. Roche is the largest pharmaceutical company in the world and the leading provider of cancer treatments globally.
In this post, Roche’s global Platform and machine learning (ML) engineering team discuss how they used Amazon Redshift data API to democratize access to the data in their Amazon Redshift data warehouse with Google Sheets (gSheets).
Business needs
Go-To-Market (GTM) is the domain that lets Roche understand customers and create and deliver valuable services that meet their needs. This lets them get a better understanding of the health ecosystem and provide better services for patients, doctors, and hospitals. It extends beyond health care professionals (HCPs) to a larger Healthcare ecosystem consisting of patients, communities, health authorities, payers, providers, academia, competitors, etc. Data and analytics are essential to supporting our internal and external stakeholders in their decision-making processes through actionable insights.
For this mission, Roche embraced the modern data stack and built a scalable solution in the cloud.
Driving true data democratization requires not only providing business leaders with polished dashboards or data scientists with SQL access, but also addressing the requirements of business users that need the data. For this purpose, most business users (such as Analysts) leverage Excel—or gSheet in the case of Roche—for data analysis.
Providing access to data in Amazon Redshift to these gSheets users is a non-trivial problem. Without a powerful and flexible tool that lets data consumers use self-service analytics, most organizations will not realize the promise of the modern data stack. To solve this problem, we want to empower every data analyst who doesn’t have an SQL skillset with a means by which they can easily access and manipulate data in the applications that they are most familiar with.
The Roche GTM organization uses the Redshift Data API to simplify the integration between gSheets and Amazon Redshift, and thus facilitate the data needs of their business users for analytical processing and querying. The Amazon Redshift Data API lets you painlessly access data from Amazon Redshift with all types of traditional, cloud-native, and containerized, serverless web service-based applications and event-driven applications. Data API simplifies data access, ingest, and egress from languages supported with AWS SDK, such as Python, Go, Java, Node.js, PHP, Ruby, and C++ so that you can focus on building applications as opposed to managing infrastructure. The process they developed using Amazon Redshift Data API has significantly lowered the barrier for entry for new users without needing any data warehousing experience.
Use-Case
In this post, you will learn how to integrate Amazon Redshift with gSheets to pull data sets directly back into gSheets. These mechanisms are facilitated through the use of the Amazon Redshift Data API and Google Apps Script. Google Apps Script is a programmatic way of manipulating and extending gSheets and the data that they contain.
Architecture
It is possible to include publicly available JS libraries such as JQuery-builder provided that Apps Script is natively a cloud-based Javascript platform.
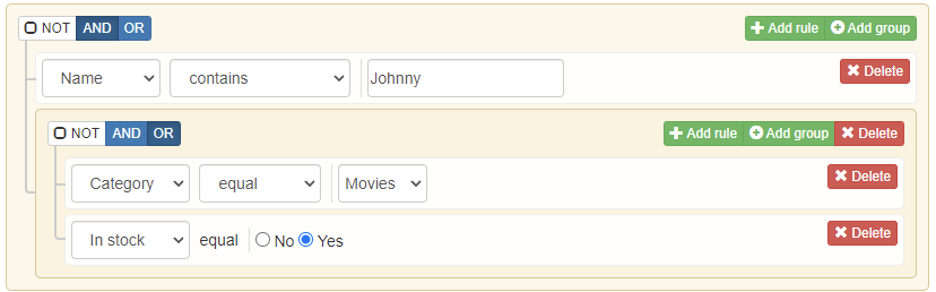

The JQuery builder library facilitates the creation of standard SQL queries via a simple-to-use graphical user interface. The Redshift Data API can be used to retrieve the data directly to gSheets with a query in place. The following diagram illustrates the overall process from a technical standpoint:
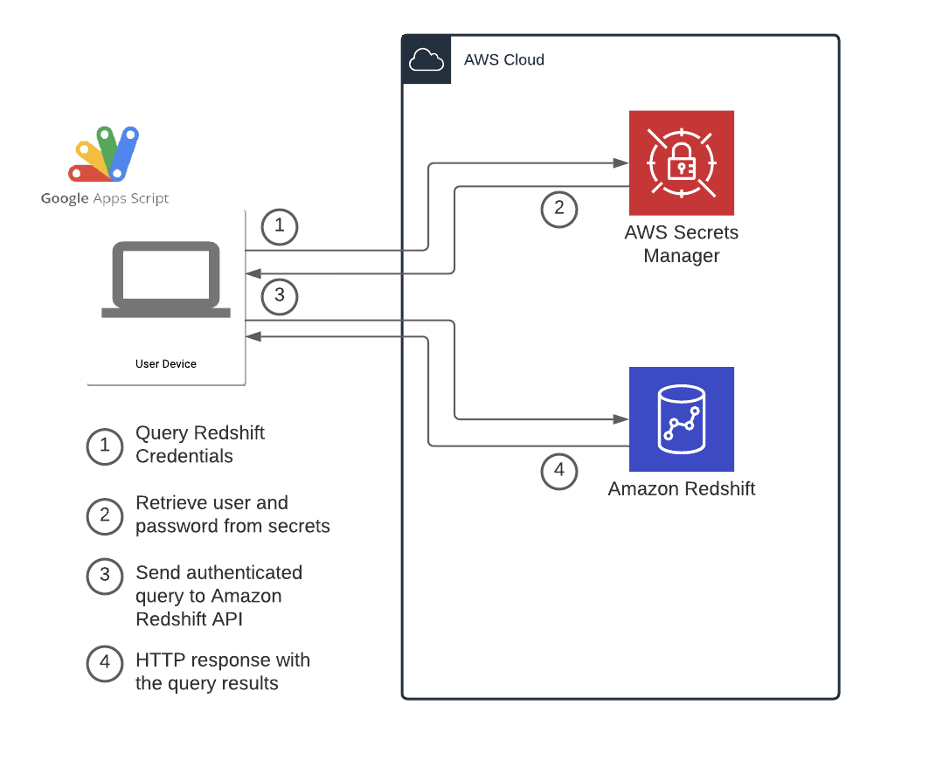
Even though AppsScript is, in fact, Javascript, the AWS-provided SDKs for the browser (NodeJS and React) cannot be used on the Google platform, as they require specific properties that are native to the underlying infrastructure. It is possible to authenticate and access AWS resources through the available API calls. Here is an example of how to achieve that.
You can use an access key ID and a secret access key to authenticate the requests to AWS by using the code in the link example above. We recommend following the least privilege principle when granting access to this programmatic user, or assuming a role with temporary credentials. Since each user will require a different set of permissions on the Redshift objects—database, schema, and table—each user will have their own user access credentials. These credentials are safely stored under the AWS Secrets Manager service. Therefore, the programmatic user needs a set of permissions that enable them to retrieve secrets from the AWS Secrets Manager and execute queries against the Redshift Data API.
Code example for AppScript to use Data API
In this section, you will learn how to pull existing data back into a new gSheets Document. This section will not cover how to parse the data from the JQuery-builder library, as it is not within the main scope of the article.
- In the AWS console, go to Secrets Manager and create a new secret to store the database credentials to access the Redshift Cluster: username and password. These will be used to grant Redshift access to the gSheets user.

- In the AWS console, create a new IAM user with programmatic access, and generate the corresponding Access Key credentials. The only set of policies required for this user is to be able to read the secret created in the previous step from the AWS Secrets Manager service and to query the Redshift Data API.

Below is the policy document: - Access the Google Apps Script console. Create an aws.gs file with the code available here. This will let you perform authenticated requests to the AWS services by providing an access key and a secret access key.

- Initiate the AWS variable providing the access key and secret access key created in step 3.
- Request the Redshift username and password from the AWS Secrets Manager:
- Query a table using the Amazon Redshift Data API:
- The result can then be displayed as a table in gSheets:
- Once finished, the Apps Script can be deployed as an Addon that enables end-users from an entire organization to leverage the capabilities of retrieving data from Amazon Redshift directly into their spreadsheets. Details on how Apps Script code can be deployed as an Addon can be found here.
How users access Google Sheets
- Open a gSheet, and go to manage addons -> Install addon:

- Once the Addon is successfully installed, select the Addon menu and select Redshift Synchronization. A dialog will appear prompting the user to select the combination of database, schema, and table from which to load the data.

- After choosing the intended table, a new panel will appear on the right side of the screen. Then, the user is prompted to select which columns to retrieve from the table, apply any filtering operation, and/or apply any aggregations to the data.

- Upon submitting the query, app scripts will translate the user selection into a query that is sent to the Amazon Redshift Data API. Then, the returned data is transformed and displayed as a regular gSheet table:

Security and Access Management
In the scripts above, there is a direct integration between AWS Secrets Manager and Google Apps Script. The scripts above can extract the currently-authenticated user’s Google email address. Using this value and a set of annotated tags, the script can appropriately pull the user’s credentials securely to authenticate the requests made to the Amazon Redshift cluster. Follow these steps to set up a new user in an existing Amazon Redshift cluster. Once the user has been created, follow these steps for creating a new AWS Secrets Manager secret for your cluster. Make sure that the appropriate tag is applied with the key of “email” along with the corresponding user’s Google email address. Here is a sample configuration that is used for creating Redshift groups, users, and data shares via the Redshift Data API:
Operational Metrics and Improvement
Providing access to live data that is hosted in Redshift directly to the business users and enabling true self-service decrease the burden on platform teams to provide data extracts or other mechanisms to deliver up-to-date information. Additionally, by not having different files and versions of data circulating, the business risk of reporting different key figures or KPI can be reduced, and an overall process efficiency can be achieved.
The initial success of this add-on in GTM led to the extension of this to a broader audience, where we are hoping to serve hundreds of users with all of the internal and public data in the future.
Conclusion
In this post, you learned how to create new Amazon Redshift tables and pull existing Redshift tables into a Google Sheet for business users to easily integrate with and manipulate data. This integration was seamless and demonstrated how easy the Amazon Redshift Data API makes integration with external applications, such as Google Sheets with Amazon Redshift. The outlined use-cases above are just a few examples of how the Amazon Redshift Data API can be applied and used to simplify interactions between users and Amazon Redshift clusters.
About the Authors
 Dr. Yannick Misteli is leading cloud platform and ML engineering teams in global product strategy (GPS) at Roche. He is passionate about infrastructure and operationalizing data-driven solutions, and he has broad experience in driving business value creation through data analytics.
Dr. Yannick Misteli is leading cloud platform and ML engineering teams in global product strategy (GPS) at Roche. He is passionate about infrastructure and operationalizing data-driven solutions, and he has broad experience in driving business value creation through data analytics.
 João Antunes is a Data Engineer in the Global Product Strategy (GPS) team at Roche. He has a track record of deploying Big Data batch and streaming solutions for the telco, finance, and pharma industries.
João Antunes is a Data Engineer in the Global Product Strategy (GPS) team at Roche. He has a track record of deploying Big Data batch and streaming solutions for the telco, finance, and pharma industries.
Krzysztof Wisniewski is a back-end JavaScript developer in the Global Product Strategy (GPS) team at Roche. He is passionate about full-stack development from the front-end through the back-end to databases.
 Matt Noyce is a Senior Cloud Application Architect at AWS. He works together primarily with Life Sciences and Healthcare customers to architect and build solutions on AWS for their business needs.
Matt Noyce is a Senior Cloud Application Architect at AWS. He works together primarily with Life Sciences and Healthcare customers to architect and build solutions on AWS for their business needs.
 Debu Panda, a Principal Product Manager at AWS, is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world. Debu has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences such as re:Invent, Oracle Open World, and Java One. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt).
Debu Panda, a Principal Product Manager at AWS, is an industry leader in analytics, application platform, and database technologies, and has more than 25 years of experience in the IT world. Debu has published numerous articles on analytics, enterprise Java, and databases and has presented at multiple conferences such as re:Invent, Oracle Open World, and Java One. He is lead author of the EJB 3 in Action (Manning Publications 2007, 2014) and Middleware Management (Packt).