AWS Big Data Blog
Manage your workloads better using Amazon Redshift Workload Management
With Amazon Redshift, you can run a complex mix of workloads on your data warehouse, such as frequent data loads running alongside business-critical dashboard queries and complex transformation jobs. We also see more and more data science and machine learning (ML) workloads. Each workload type has different resource needs and different service-level agreements (SLAs).
Amazon Redshift workload management (WLM) helps you maximize query throughput and get consistent performance for the most demanding analytics workloads by optimally using the resources of your existing data warehouse.
In Amazon Redshift, you implement WLM to define the number of query queues that are available and how queries are routed to those queues for processing. WLM queues are configured based on Redshift user groups, user roles, or query groups. When users belonging to a user group or role run queries in the database, their queries are routed to a queue as depicted in the following flowchart.
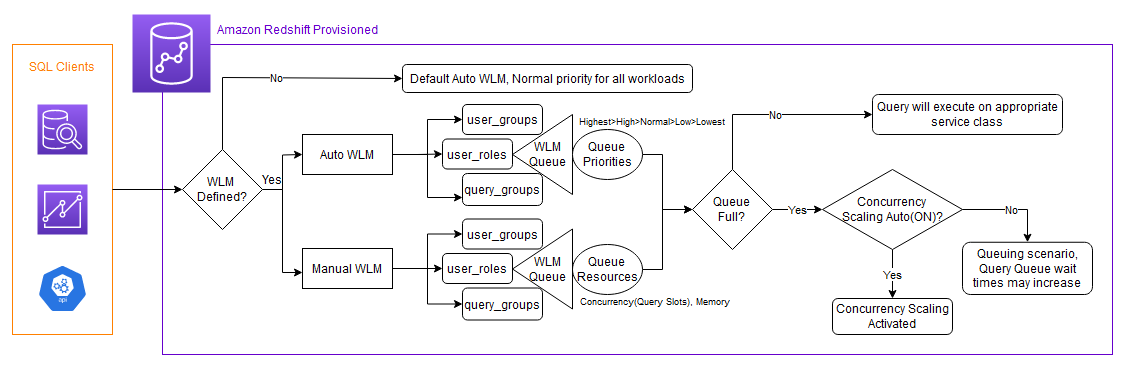
Role-based access control (RBAC) is a new enhancement that helps you simplify the management of security privileges in Amazon Redshift. You can use RBAC to control end-user access to data at a broad or granular level based on their job role. We have introduced support for Redshift roles in WLM queues, you will now find User roles along with User groups and Query groups as query routing mechanism.
This post provides examples of analytics workloads for an enterprise, and shares common challenges and ways to mitigate those challenges using WLM. We guide you through common WLM patterns and how they can be associated with your data warehouse configurations. We also show how to assign user roles to WLM queues and how to use WLM query insights to optimize configuration.
Use case overview
ExampleCorp is an enterprise using Amazon Redshift to modernize its data platform and analytics. They have variety of workloads with users from various departments and personas. The service-level performance requirements vary by the nature of the workload and user personas accessing the datasets. ExampleCorp would like to manage resources and priorities on Amazon Redshift using WLM queues. For this multitenant architecture by department, ExampleCorp can achieve read/write isolation using the Amazon Redshift data sharing feature and meet its unpredictable compute scaling requirements using concurrency scaling.
The following figure illustrates the user personas and access in ExampleCorp.
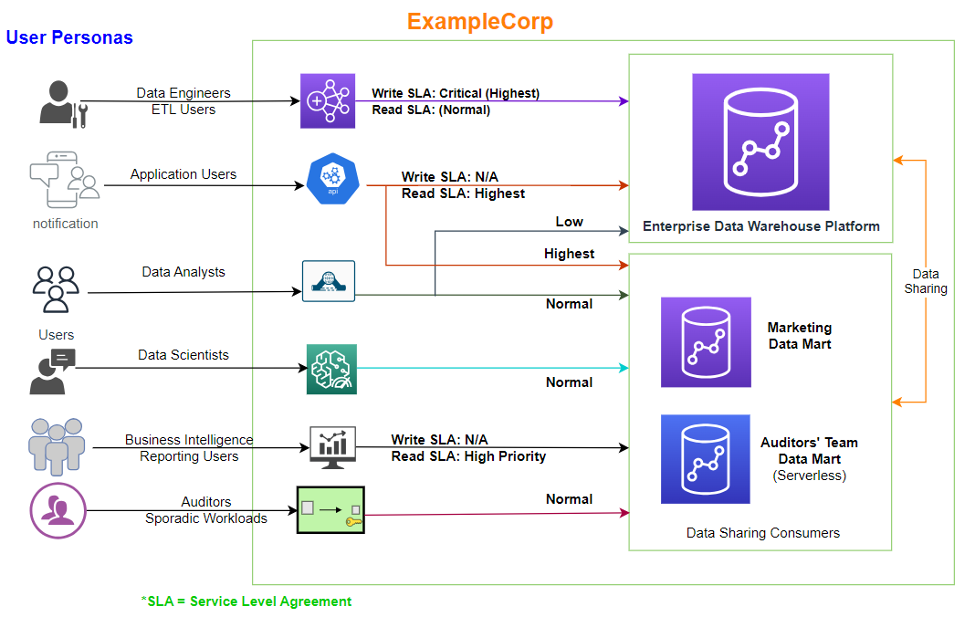
ExampleCorp has multiple Redshift clusters. For this post, we focus on the following:
- Enterprise data warehouse (EDW) platform – This has all write workloads, along with some of the applications running reads via the Redshift Data API. The enterprise standardized data from the EDW cluster is accessed by multiple consumer clusters using the Redshift data sharing feature to run downstream reports, dashboards, and other analytics workloads.
- Marketing data mart – This has predictable extract, transform, and load (ETL) and business intelligence (BI) workloads at specific times of day. The cluster admin understands the exact resource requirements by workload type.
- Auditor data mart – This is only used for a few hours a day to run scheduled reports.
ExampleCorp would like to better manage their workloads using WLM.
Solution overview
As we discussed in the previous section, ExampleCorp has multiple Redshift data warehouses: one enterprise data warehouse and two downstream Redshift data warehouses. Each data warehouse has different workloads, SLAs, and concurrency requirements.
A database administrator (DBA) will implement appropriate WLM strategies on each Redshift data warehouse based on their use case. For this post, we use the following examples:
- The enterprise data warehouse demonstrates Auto WLM with query priorities
- The marketing data mart cluster demonstrates manual WLM
- The auditors team uses their data mart infrequently for sporadic workloads; they use Amazon Redshift Serverless, which doesn’t require workload management
The following diagram illustrates the solution architecture.

Prerequisites
Before beginning this solution, you need the following:
- An AWS account
- Administrative access to Amazon Redshift
Let’s start by understanding some foundational concepts before solving the problem statement for ExampleCorp. First, how to choose between auto vs. manual WLM.
Auto vs. manual WLM
Amazon Redshift WLM enables you to flexibly manage priorities within workloads to meet your SLAs. Amazon Redshift supports Auto WLM or manual WLM for your provisioned Redshift data warehouse. The following diagram illustrates queues for each option.
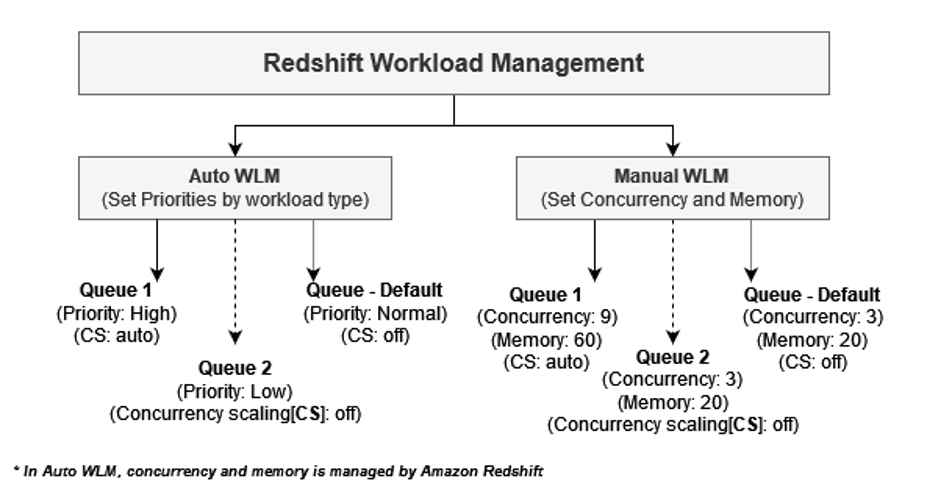
Auto WLM determines the amount of resources that queries need and adjusts the concurrency based on the workload. When queries requiring large amounts of resources are in the system (for example, hash joins between large tables), the concurrency is lower. For additional information, refer to Implementing automatic WLM. You should use Auto WLM when your workload is highly unpredictable.
With manual WLM, you manage query concurrency and memory allocation, as opposed to auto WLM, where it’s managed by Amazon Redshift automatically. You configure separate WLM queues for different workloads like ETL, BI, and ad hoc and customize resource allocation. For additional information, refer to Tutorial: Configuring manual workload management (WLM) queues.
Use manual when When your workload pattern is predictable or if you need to throttle certain types of queries depending on the time of day, such as throttle down ingestion during business hours. If you need to guarantee multiple workloads are able to run at the same time, you can define slots for each workload.
Now that you have chosen automatic or manual WLM, let’s explore WLM parameters and properties.
Static vs. dynamic properties
The WLM configuration for a Redshift data warehouse is set using a parameter group under the database configuration properties.
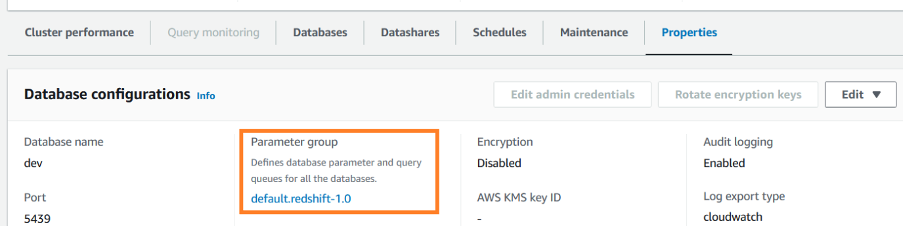
The parameter group WLM settings are either dynamic or static. You can apply dynamic properties to the database without a cluster reboot, but static properties require a cluster reboot for changes to take effect. The following table summarizes the static vs. dynamic requirements for different WLM properties.
| WLM Property | Automatic WLM | Manual WLM |
| Query groups | Dynamic | Static |
| Query group wildcard | Dynamic | Static |
| User groups | Dynamic | Static |
| User group wildcard | Dynamic | Static |
| User roles | Dynamic | Static |
| User role wildcard | Dynamic | Static |
| Concurrency on main | Not applicable | Dynamic |
| Concurrency Scaling mode | Dynamic | Dynamic |
| Enable short query acceleration | Not applicable | Dynamic |
| Maximum runtime for short queries | Dynamic | Dynamic |
| Percent of memory to use | Not applicable | Dynamic |
| Timeout | Not applicable | Dynamic |
| Priority | Dynamic | Not applicable |
| Adding or removing queues | Dynamic | Static |
Note the following:
- The parameter group parameters and WLM switch from manual to auto or vice versa are static properties, and therefore require a cluster reboot.
- For the WLM properties Concurrency on main, Percentage of memory to use, and Timeout, which are dynamic for manual WLM, the change only applies to new queries submitted after the value has changed and not for currently running queries.
- The query monitoring rules, which we discuss later in this post, are dynamic and don’t require a cluster reboot.
In the next section, we discuss the concept of service class, meaning which queue does the query get submitted to and why.
Service class
Whether you use Auto or manual WLM, the user queries submitted go to the intended WLM queue via one of the following mechanisms:
- User_Groups – The WLM queue directly maps to Redshift groups that would appear in the pg_group table.
- Query_Groups – Queue assignment is based on the query_group label. For example, a dashboard submitted from the same reporting user can have separate priorities by designation or department.
- User_Roles (latest addition) – The queue is assigned based on the Redshift roles.
WLM queues from a metadata perspective are defined as service class configuration. The following table lists common service class identifiers for your reference.
| ID | Service class |
| 1–4 | Reserved for system use. |
| 5 | Used by the superuser queue. |
| 6–13 | Used by manual WLM queues that are defined in the WLM configuration. |
| 14 | Used by short query acceleration. |
| 15 | Reserved for maintenance activities run by Amazon Redshift. |
| 100–107 | Used by automatic WLM queue when auto_wlm is true. |
The WLM queues you define based on user_groups, query_groups, or user_roles fall in service class ID 6–13 for manual WLM and service class id 100–107 for automatic WLM.
Using Query_group, you can force a query to go to service class 5 and run in the superuser queue (provided you are an authorized superuser) as shown in the following code:
For more details on how to assign a query to a particular service class, refer to Assigning queries to queues.
The short query acceleration (SQA) queue (service class 14) prioritizes short-running queries ahead of longer-running queries. If you enable SQA, you can reduce WLM queues that are dedicated to running short queries. In addition, long-running queries don’t need to contend with short queries for slots in a queue, so you can configure your WLM queues to use fewer query slots (a term used for available concurrency). Amazon Redshift uses an ML algorithm to analyze each eligible query and predict the query’s runtime. Auto WLM dynamically assigns a value for the SQA maximum runtime based on analysis of your cluster’s workload. Alternatively, you can specify a fixed value of 1–20 seconds when using manual WLM.
SQA is enabled by default in the default parameter group and for all new parameter groups. SQA can have a maximum concurrency of six queries.
Now that you understand how queries get submitted to a service class, it’s important to understand ways to avoid runaway queries and initiate an action for an unintended event.
Query monitoring rules
You can use Amazon Redshift query monitoring rules (QMRs) to set metrics-based performance boundaries for WLM queues and specify what action to take when a query goes beyond those boundaries.
The Redshift cluster automatically collects query monitoring metrics. You can query the system view SVL_QUERY_METRICS_SUMMARY as an aid to determine threshold values for defining the QMR. Then create the QMR based on following attributes:
- Query runtime, in seconds
- Query return row count
- The CPU time for a SQL statement
For a complete list of QMRs, refer to WLM query monitoring rules.

Create sample parameter groups
For our ExampleCorp use case, we demonstrate automatic and manual WLM for a provisioned Redshift data warehouse and share a serverless perspective of WLM.
The following AWS CloudFormation template provides an automated way to create sample parameter groups that you can attach to your Redshift data warehouse for workload management.
![]()
Enterprise data warehouse Redshift cluster using automatic WLM
For the EDW cluster, we use Auto WLM. To configure the service class, we look at all three options: user_roles, user_groups, and query_groups.
Here’s a glimpse of how this can be set up in WLM queues and then used in your queries.
On the Amazon Redshift console, under Configurations in the navigation pane, choose Workload Management. You can create a new parameter group or modify an existing one created by you. Select the parameter group to edit its queues. There’s always a default queue (the last one in case of multiple queues defined), which is a catch-all for queries that don’t get routed to any specific queue.
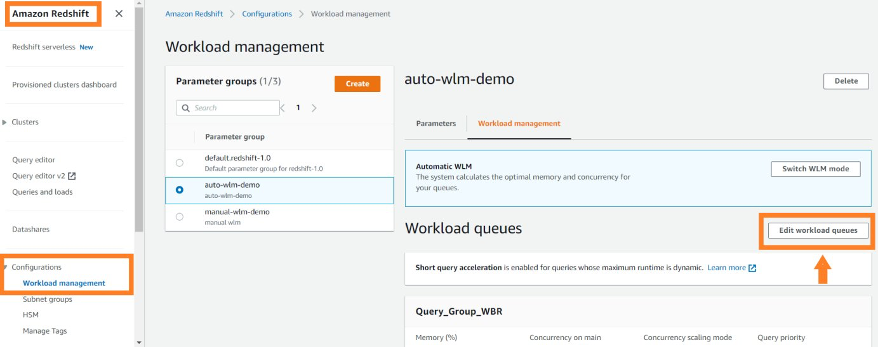
User roles in WLM
With the introduction of user roles in WLM queues, now you can manage your workload by adding different roles to different queues. This can help you prioritize the queries based on the roles a user has. When a user runs a query, WLM will check if this user’s roles were added in any workload queues and assign the query to the first matching queue. To add roles into the WLM queue, you can go to the WLM page, create or modify an existing workload queue, add a user’s roles in the queue, and select Matching wildcards to add roles that get matched as wildcards.
For more information about how to convert from groups to roles, refer to Amazon Redshift Roles (RBAC), which walks you through a stored procedure to convert groups to roles.
In the following example, we have created the WLM queue EDW_Admins, which uses edw_admin_role created in Amazon Redshift to submit the workloads in this queue. The EDW_Admins queue is created with a high priority and automatic concurrency scaling mode.
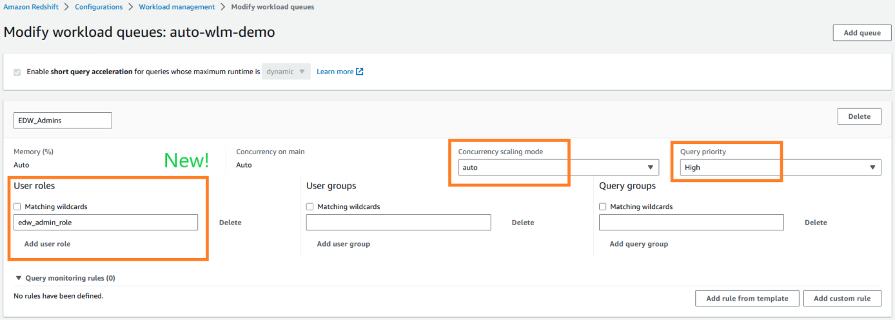
User groups
Groups are collections of users who are all granted permissions associated with the group. You can use groups to simplify permission management by granting privileges just one time. If the members of a group get added or removed, you don’t need to manage them at a user level. For example, you can create different groups for sales, administration, and support and give the users in each group the appropriate access to the data they need for their work.
You can grant or revoke permissions at the user group level, and those changes will apply to all members of the group.
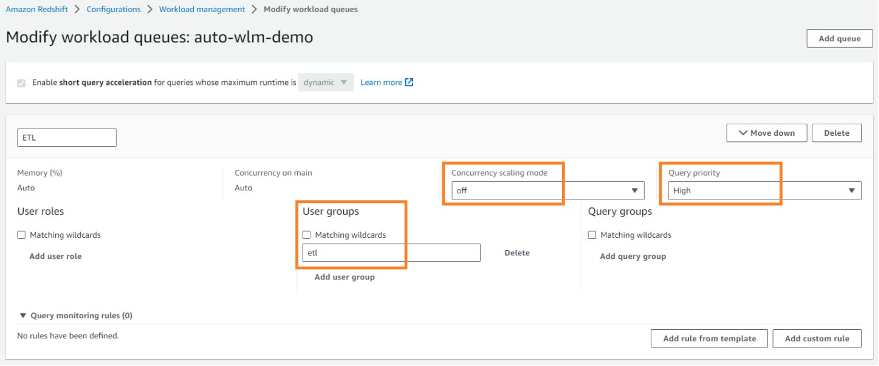
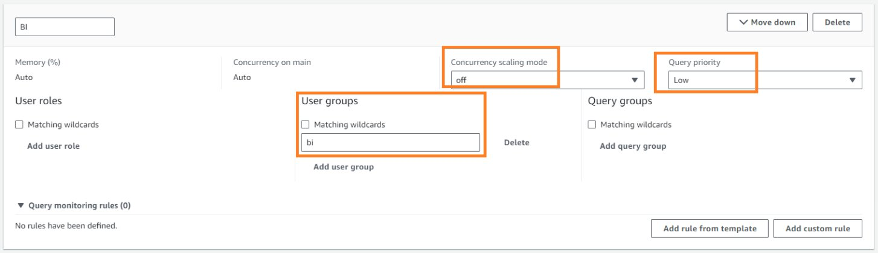
ETL, data analysts, or BI or decision support systems can use user groups to better manage and isolate their workloads. For our example, ETL WLM queue queries will be run with the user group etl. The data analyst group (BI) WLM queue queries will run using the bi user group.
Choose Add queue to add a new queue that you will use for user_groups, in this case ETL. If you would like these to be matched as wildcards (strings containing those keywords), select Matching wildcards. You can customize other options like query priority and concurrency scaling, explained earlier in this post. Choose Save to complete this queue setup.
In the following example, we have created two different WLM queues for ETL and BI. The ETL queue has a high priority and concurrency scaling mode is off, whereas the BI queue has a low priority and concurrency scaling mode is off.
Use the following code to create a group with multiple users:
Query groups
Query_Groups are labels used for queries that are run within the same session. Think of these as tags that you may want to use to identify queries for a uniquely identifiable use case. In our example use case, the data analysts or BI or decision support systems can use query_groups to better manage and isolate their workloads. For our example, weekly business reports can run with the query_group label wbr. Queries from the marketing department can be run with a query_group of marketing.
The benefit of using query_groups is that you can use it to constrain results from the STL_QUERY and STV_INFLIGHT tables and the SVL_QLOG view. You can apply a separate label to every query that you run to uniquely identify queries without having to look up their IDs.
Choose Add queue to add a new queue that you will use for query_groups, in this case wbr or weekly_business_report. If you would like these to be matched as wildcards (strings containing those keywords), select Matching wildcards. You can customize other options like query priority and concurrency scaling options as explained earlier in this post. Choose Save to save this queue setup.
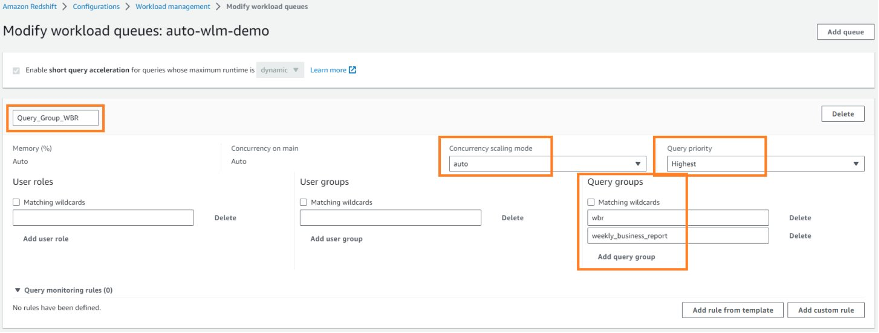
Now let’s see how you can force a query to use the query_groups queue just created.
You can assign a query to a queue at runtime by assigning your query to the appropriate query group. Use the SET command to begin a query group:
Queries following the SET command would go to the WLM queue Query_Group_WBR until you either reset the query group or end your current login session. For information about setting and resetting server configuration parameter, see SET and RESET, respectively.
The query group labels that you specify must be included in the current WLM configuration; otherwise, the SET query_group command has no effect on query queues.
For more query_groups examples, refer to WLM queue assignment rules.
Marketing Redshift cluster using manual WLM
Expanding on the marketing Redshift cluster use case of ExampleCorp, this cluster serves two types of workloads:
- Running ETL for a period of 2 hours between 7:00 AM to 9:00 AM
- Running BI reports and dashboards for the remaining time during the day
When you have such a clarity in the workloads, and your scope of usage is customizable by design, you may want to consider using manual WLM, where you can control the memory and concurrency resource allocation. Auto WLM will still be applicable, but manual WLM can also be a choice.
Let’s set up manual WLM in this case, with two WLM queues: ETL and BI.
To best utilize the resources, we use an AWS Command Line Interface (AWS CLI) command at the start of our ETL, which will make our WLM queues ETL-friendly, providing higher concurrency to the ETL queue. At the end of our ETL, we use an AWS CLI command to change the WLM queue to have BI-friendly resource settings. Modifying the WLM queues doesn’t require a reboot of your cluster; however, modifying the parameters or parameter group does.
If you were to use Auto WLM, this could have been achieved by dynamically changing the query priority of the ETL and BI queues.
By default, when you choose Create, the WLM created will be Auto WLM. You can switch to manual WLM by choosing Switch WLM mode. After switching WLM mode, choose Edit workload queues.
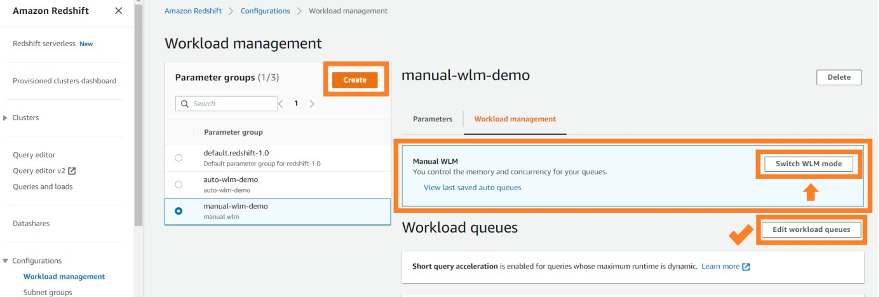
This will open the Modify workload queues page, where you can create your ETL and BI WLM queues.
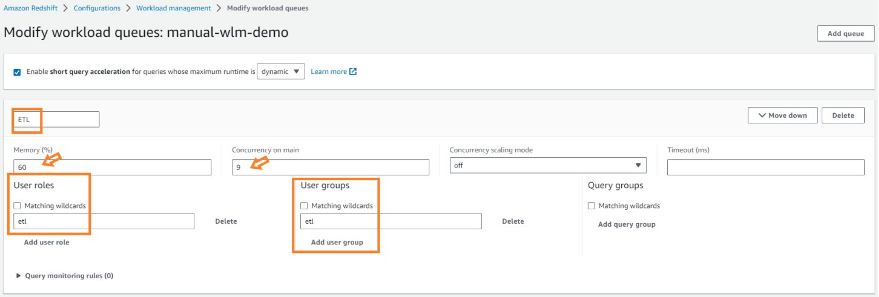
After you add your ETL and BI queues, choose Save. You should have configured the following:
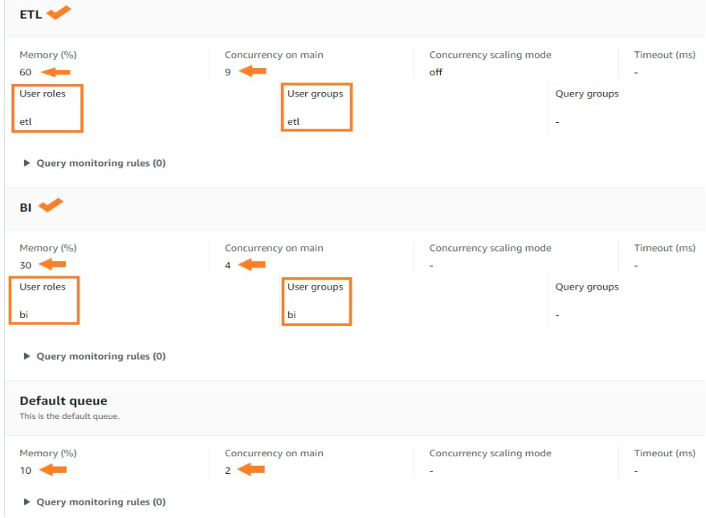
- An ETL queue with 60% memory allocation and query concurrency of 9
- A BI queue with 30% memory allocation and query concurrency of 4
- A default queue with 10% memory allocation and query concurrency of 2
Your WLM queues should appear with settings as shown in the following screenshot.
Enterprises may prefer to complete these steps in an automated way. For the marketing data mart use case, the ETL starts at 7:00 AM. An ideal start to the ETL flow would be to have a job that makes your WLM settings ETL queue friendly. Here’s how you would modify concurrency and memory (both dynamic properties in manual WLM queues) to an ETL-friendly configuration:

The preceding AWS CLI command programmatically sets the configuration of your WLM queues without requiring a reboot of the cluster because the queue settings changed were all dynamic settings.
For the marketing data mart use case, at 9:00 AM or when the ETL is finished, you can have a job run an AWS CLI command to modify the WLM queue resource settings to a BI-friendly configuration as shown in the following code:

Note that in regards to a manual WLM configuration, the maximum slots you can allocate to a queue is 50. However, this doesn’t mean that in an automatic WLM configuration, a Redshift cluster always runs 50 queries concurrently. This can change based on the memory needs or other types of resource allocation on the cluster. We recommend configuring your manual WLM query queues with a total of 15 or fewer query slots. For more information, see Concurrency level.
In case of WLM timeout or a QMR hop action within manual WLM, a query can attempt to hop to the next matching queue based on WLM queue assignment rules. This action in manual WLM is called query queue hopping.
Auditor Redshift data warehouse using WLM in Redshift Serverless
The auditor data warehouse workload runs on the month, and quarter end. For this periodic workload, Redshift Serverless is well suited, both from a cost and ease of administration perspective. Redshift Serverless uses ML to learn from your workload to automatically manage workload and auto scaling of compute needed for your workload.
In Redshift Serverless, you can set up usage and query limits. The query limits let you set up the QMR. You can choose Manage query limits to automatically trigger the default abort action when queries go beyond performance boundaries. For more information, refer to Query monitoring metrics for Amazon Redshift Serverless.
![]()

For other detailed limits in Redshift Serverless, refer to Configure monitoring, limits, and alarms in Amazon Redshift Serverless to keep costs predictable.
Monitor using system views for operational metrics
The system views in Amazon Redshift are used to monitor the workload performance. You can view the status of queries, queues, and service classes by using WLM-specific system tables. You can query system tables to explore the following details:
- View which queries are being tracked and what resources are allocated by the workload manager
- See which queue a query has been assigned to
- View the status of a query that is currently being tracked by the workload manager
You can download the sample SQL notebook system queries. You can import this in Query Editor V2.0. The queries in the sample notebook can help you explore your workloads being managed by WLM queues.
Conclusion
In this post, we covered real-world examples for Auto WLM and manual WLM patterns. We introduced user roles assignment to WLM queues, and shared queries on system views and tables to gather operational insights on your WLM configuration. We encourage you to explore using Redshift user roles with workload management. Use the script provided on AWS re:Post to convert groups to roles, and start using user roles for your WLM queues.
About the Authors
 Rohit Vashishtha is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has over 17 years of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance.
Rohit Vashishtha is a Senior Analytics Specialist Solutions Architect at AWS based in Dallas, Texas. He has over 17 years of experience architecting, building, leading, and maintaining big data platforms. Rohit helps customers modernize their analytic workloads using the breadth of AWS services and ensures that customers get the best price/performance with utmost security and data governance.
 Harshida Patel is a Principal specialist SA with AWS.
Harshida Patel is a Principal specialist SA with AWS.
 Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
Nita Shah is an Analytics Specialist Solutions Architect at AWS based out of New York. She has been building data warehouse solutions for over 20 years and specializes in Amazon Redshift. She is focused on helping customers design and build enterprise-scale well-architected analytics and decision support platforms.
 Yanzhu Ji is a Product Manager in the Amazon Redshift team. She has experience in product vision and strategy in industry-leading data products and platforms. She has outstanding skill in building substantial software products using web development, system design, database, and distributed programming techniques. In her personal life, Yanzhu likes painting, photography, and playing tennis.
Yanzhu Ji is a Product Manager in the Amazon Redshift team. She has experience in product vision and strategy in industry-leading data products and platforms. She has outstanding skill in building substantial software products using web development, system design, database, and distributed programming techniques. In her personal life, Yanzhu likes painting, photography, and playing tennis.