AWS Big Data Blog
Query your data created on-premises using Amazon Athena and AWS Storage Gateway
Enterprise customers have to maintain, protect, and provide access to the petabytes of data they produce in their data centers every day.
Traditionally, this involves a set of complex, interrelated systems to store the raw data:
- Network attached storage (NAS)
- Storage area networks (SAN)
- Direct attached storage (DAS)
Additional architecture can transform this raw data and load it into relational databases to support querying and analysis activities. This is a process commonly known as extract, transform, and load (ETL). A business must maintain each system separately, often requiring separate teams: DBAs for the databases, systems engineers for the underlying physical infrastructure, and others.
AWS continually looks at ways to invent and simplify on behalf of customers. This post looks at a combination of AWS technologies that you can deploy to simplify the process of querying relevant data generated on-premises without the need for a full database.
Solution overview
If you rely on popular enterprise analysis tools—such as Tableau, you need open database connectivity (ODBC) or Java database connectivity (JDBC) to connect to and run queries against your data. Conversely, file systems use protocols like SMB or NFS to read and write files. Until now, you had to translate data from its raw format (often text files) into a relational database to allow analysis.
Enter Storage Gateway and Athena. The following diagram shows some of the services involved in this solution for querying on-premises data.
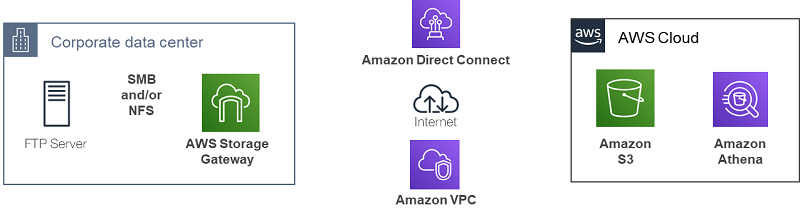
Storage Gateway is a hybrid storage service that enables your on-premises applications to use AWS Cloud storage. The file gateway configuration of Storage Gateway offers a seamless way to connect to the cloud to store application data files and backup images on Amazon S3 cloud storage. File gateway offers SMB or NFS-based access to data in S3 with local caching, storing, and billing files as S3 objects.
Athena is an interactive query service that makes it easy to analyze data in S3 using standard SQL. Athena is serverless, with no infrastructure to manage. You pay only for the queries that you run.
In this post, I use the preceding architecture to demonstrate the combined capabilities of Storage Gateway and Athena.
Prerequisites
To follow along with the process in this post, you need the following resources:
- An AWS account
Implementing the gateway
For this example, I walk you through the process of setting up searchable data with ACME Corp. This is a fictitious company that wants to store, protect, and analyze the data that it receives from millions of IoT sensors around the world.
The following diagram shows how data flows between each step in ACME’s workflow in the proposed solution. After you configure this solution, data automatically flows to ACME’s analysts with no manual intervention required.

ACME receives a daily file from each sensor through FTP in text (comma-separated) format. These files share a common set of columns, and ACME stores the files on a NAS device behind their FTP server. They then replicate the NAS to a secondary facility for disaster recovery. At the end of each day, they run an ETL process, which reads each text file and loads it to a relational database table with a similar column structure.
ACME analysts receive an email when the load process completes, letting them begin their analysis of the previous day’s activities—provided that the load didn’t encounter any problems.
- Load issue—The system pages operations staff, which delays the start of the analysts’ day.
- NAS failure—Operations staff must replay the previous day’s data into the FTP server, a costly and time-consuming process.
ACME’s hypothetical recovery time objective for the analysis activities is four hours in the event of a database failure, and up to one day for the data. Operations personnel must maintain FTP servers, the NAS environment, and database servers.
Without changing ACME’s FTP process—assume that they want to keep it as is, first deploy a file gateway on their VMware infrastructure to replace ACME’s existing NAS. You can set up a file gateway for testing purposes in your own Amazon EC2 environment.
- In the Storage Gateway console, choose Gateways, Create gateway.
- Under Select File type, select File gateway and choose Next.
- Under Select host platform, select Amazon EC2 and follow the on-screen instructions to launch a gateway instance.
Configure and test your new gateway. The wizard automatically mounts your new gateway to the FTP server in place of the existing NAS. Here’s ACME’s S3 bucket, with data from the IoT sensors now appearing.
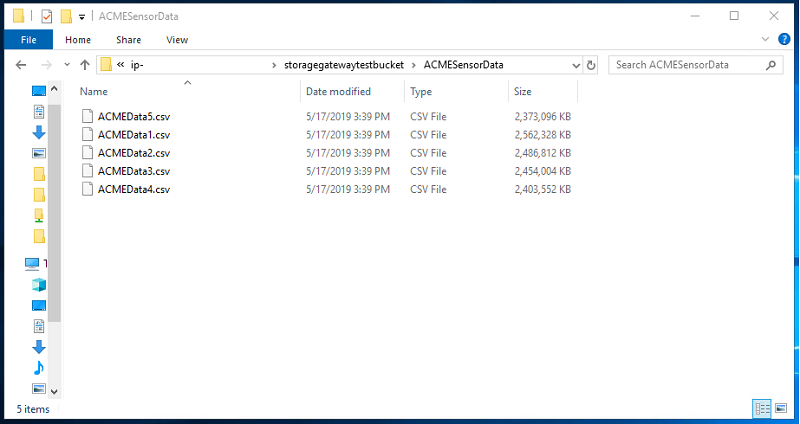
S3 presents the object keys as files to the Windows machine, allowing Windows Explorer to access them.
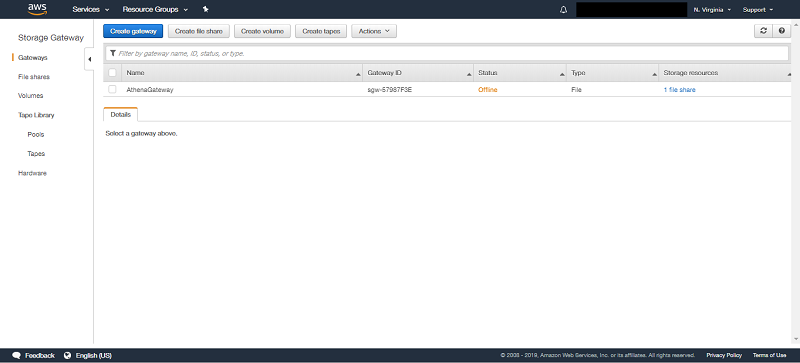
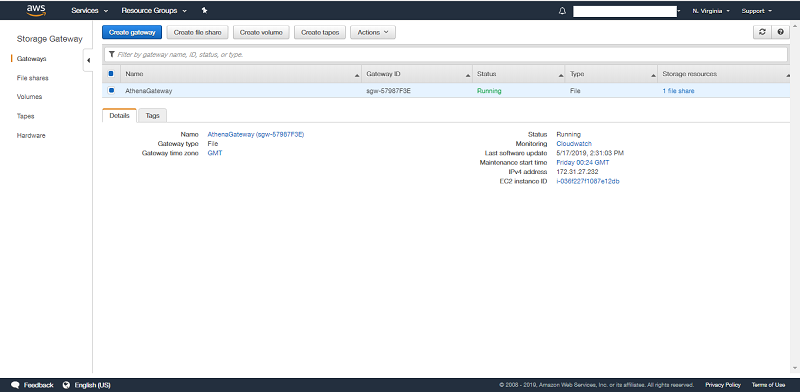
Here’s what the file gateway configuration looks like in an example ACME account. You can see that the gateway, AthenaGateway, is running, up-to-date, and mapped to the file share storage resource.
After configuring and testing the gateway, it is mounted to the FTP server in place of the existing NAS. Here’s ACME’s S3 bucket, where ACME can see the data from the IoT sensors is now appearing in Amazon S3:
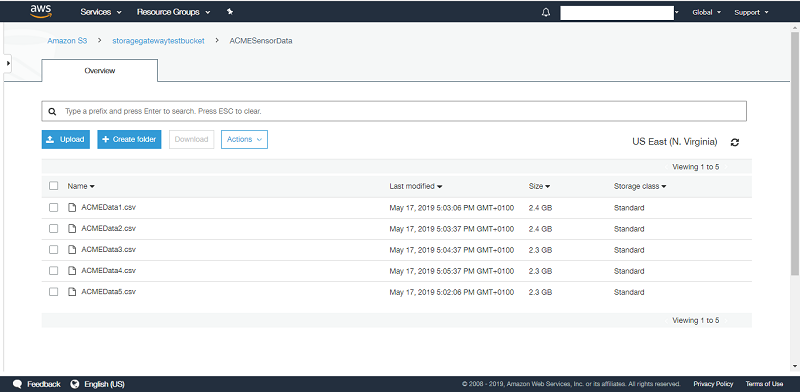
Here we can see the contents of the configured S3 bucket with the object keys presented as files to the Windows machine, and hence accessible in Windows Explorer:
Here’s what the File Gateway configuration looks like in ACME’s account. We can see that the gateway we created, AthenaGateway, is up and running, up to date, and mapped to the file share storage resource:
For more information, see Creating a File Gateway.
Adding Athena
Using the console, create a new Athena database and table pointing to ACME’s S3 bucket, with a table definition representing the columns in the data.
ACME’s policies call for encrypting any data at rest, and Storage Gateway supports encryption using AWS KMS when writing data to the S3 bucket. Athena supports the range of S3 encryption options, both for encrypted datasets in S3 and for encrypted query results. These options encrypt data at rest in S3. Whether you use these options or not, Transport Layer Security (TLS) encrypts objects in transit between Athena resources and between Athena and S3. TLS even encrypts the plaintext query results streamed to JDBC clients.
To be sure that your encryption services work, run a test query in the Athena console and verify that it returns data correctly. As the file gateway receives new data, it automatically adds it to S3, and automatically includes that data in Athena’s query scope.
Letting Athena query your data
Now create an Athena database using AWS Glue. This step makes ACME’s S3 data accessible, allowing Athena to query it. AWS Glue consists of the following components:
- A central metadata repository called the AWS Glue Data Catalog.
- An ETL engine that automatically generates Python or Scala code.
- A flexible scheduler that handles dependency resolution, job monitoring, and retries.
AWS Glue is serverless, with no infrastructure to set up or manage.
First, in the AWS Glue console, choose Databases, Tables. For Add tables, choose Add tables using a crawler. Follow the standard setup prompts, referencing your S3 bucket and prefix when asked. For more information, see Defining Crawlers.
After you configure the crawler, run it. It crawls your data in S3 and flags it upon completing the task.
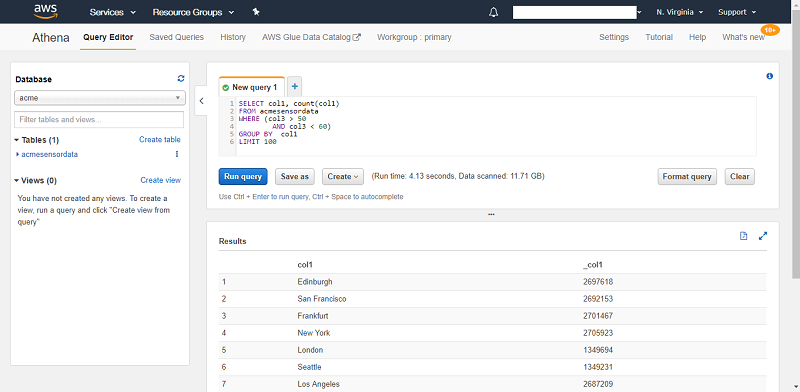
Next, open the Athena console. The Athena dashboard lists the database and tables created by AWS Glue. In the Query Editor, select your new database. Enter the following test query in the New query field:
This sample query scans all ACME data to count the top 100 cities with sensors that emitted values in the range between 50 and 60. It then reports how many 50–60 range data points the sensors emitted in total.
Redirecting your final workflow
The final step is to redirect ACME’s Tableau environment to point to an Athena ODBC endpoint. ACME centrally manages its Tableau ODBC configuration. To redirect the workflow, swap the necessary details to point to Athena instead of the existing on-premises relational database.
When you start Tableau, under Connect, the program lists the file and database types supported by Tableau Desktop. To see the complete list, choose More.
Tableau considers ODBC a standard way to connect to a database. You can connect Tableau to your data using the ODBC driver for Athena and the Tableau Other Database connection. For additional guidance, see Other Databases (ODBC) in the Tableau documentation.
Simplifying the architecture
Because the relational database in this scenario only supports ad hoc SQL queries, the system no longer needs it. If there are no other dependencies, ACME can now decommission the on-premises ETL, relational database, and NAS infrastructure that formerly supported this scenario. Aside from the FTP servers and the Storage Gateway virtual machine hosts, ACME now manages no servers to support their data collection.
End-user analysts working with this data no longer have to wait until the start of their day to begin analysis. New sensor data arrives in the Athena S3 folder shortly after FTP delivery from the sensors and is immediately available for querying. The removal of the ETL and relational database infrastructure reduces potential points of failure. In the event of a disaster, an Athena endpoint in a second AWS Region makes the data available to Tableau as soon as replication completes.
Because S3 can trigger events when new data arrives, analysts can set alerts to notify them as soon as data from particular sensor groups becomes available. The local gateway keeps the data cached, allowing for rapid access by other on-premises computing, big data, or other applications.
ACME can now rapidly launch a second Storage Gateway instance on their existing VMware infrastructure, should the primary fail. The modular nature of AWS tools means that this scenario is ripe for refinement. You could use the NotifyWhenUploaded functionality in Storage Gateway to notify Amazon CloudWatch Events when data groups upload, enabling batch processing.
Conclusion
Over the course of this post, to meet the fictional ACME company’s data needs, you replaced ACME’s on-premises NAS with AWS Storage Gateway backed by an S3 bucket. You then configured their FTP server to use the file gateway’s file share in place of their existing one. You had to configure Storage Gateway as a file gateway to provide access to the customer S3 bucket as a NAS. And you configured a serverless Athena database to mimic the previous relational database and expose an ODBC endpoint to this database to which ACME’s Tableau environment can write.
Enterprise customers like ACME deal with complex architectures for hybrid cloud scenarios. The combination of AWS Storage Gateway and Amazon Athena helps them simplify and lower costs. They can enable on-premises, cloud-native, and hybrid scenarios across their application portfolios.
Hopefully, you have found this post informative and the proposed solution intriguing. As always, AWS welcomes all feedback and comments.
About the Author
 James Forrester is Head of Technology for AWS Global Accounts. He works with customers around the world to provide thought leadership on the transformative value, applicability and usage of the full breadth of AWS services.
James Forrester is Head of Technology for AWS Global Accounts. He works with customers around the world to provide thought leadership on the transformative value, applicability and usage of the full breadth of AWS services.