AWS Big Data Blog
Top 9 performance tuning tips for PrestoDB on Amazon EMR
Presto is a popular distributed SQL query engine for interactive data analytics. With its massively parallel processing (MPP) architecture, it’s capable of directly querying large datasets without the need of time-consuming and costly ETL processes. With a properly tuned Presto cluster you can run fast queries against big data with response times ranging from subsecond to minutes.
This post shows a common architecture pattern to use Presto on an Amazon EMR cluster as a big data query engine and provides practical performance tuning tips for common performance challenges faced by large enterprise customers.
Architecture overview
Because Presto is a query-only engine, it separates compute and storage and relies on different connectors to connect to various data sources. This architecture makes Presto a natural fit for deployment on an EMR cluster, which can be launched on-demand then destroyed or scaled in to save costs when not in use. A preconfigured EMR cluster running Presto can be launched in minutes without needing to worry about node provisioning, cluster setup, configuration, or cluster tuning.
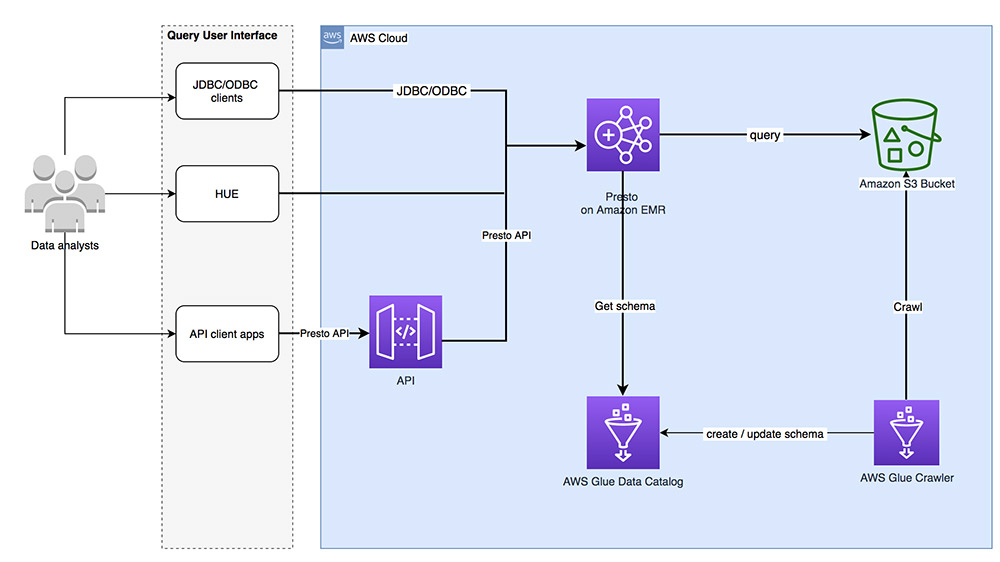
The following diagram shows a common pattern to use Presto on an EMR cluster as a big data query engine. The data to be queried is stored in Amazon Simple Storage Service (Amazon S3) buckets in hierarchical format organized by prefixes. Presto uses Apache Hive metadata catalog for metadata (tables, columns, datatypes) about the data being queried. In our example, we use AWS Glue Data Catalog as the metadata catalog. The metadata is inferred and populated using AWS Glue crawlers. Queries in standard SQL can be submitted to Presto on an EMR cluster using JDBC/ODBC clients, Apache Hue, or through custom APIs.
The following diagram illustrates a common architecture to use Presto on Amazon EMR with the Glue Data Catalog as a big data query engine to query data in Amazon S3 using standard SQL.
Common performance challenges faced by large enterprise customers
Amazon EMR makes it easy to run Presto in the cloud because you get a pre-configured cluster, the latest version of Presto integrated with AWS platform services, a performance optimized EMR runtime for Presto, and the ability easily scale up and scale down your clusters. Although the default configuration for Presto on Amazon EMR works well for most common use cases, many large enterprises do face significant performance challenges with high concurrent query loads and large datasets.
The following performance tuning techniques can help you optimize your EMR Presto setup for your unique application requirements.
Best practice: Provisioning the EMR cluster with configurations that work best with Presto
In this section, we discuss tips when provisioning your EMR cluster.
Tip 1: Selecting appropriate EMR node types
A Presto cluster consists of two types of nodes: coordinator and worker. The coordinator node runs on the EMR leader node, and worker nodes run on EMR core nodes and optionally EMR task nodes (the rest of the nodes in the EMR cluster). Keep in mind the following details about each node type:
- Leader node – One leader node is needed for the Presto cluster. This node is responsible for managing the scheduling and running of queries. With Amazon EMR 5.23.0 and later, you can launch a cluster with three leader nodes to support high availability.
- Core nodes – Core nodes run HDFS, which means that they’re slow to scale and shouldn’t be aggressively scaled. Unless HDFS storage is needed for large intermediate datasets, using task nodes is a better option. When data is located on Amazon S3, limited or no HDFS is needed, so only a minimum number of core nodes is required. One core node is the minimum requirement for an EMR cluster; running two or more core nodes is recommended for HA and failover purposes.
- Task nodes – Task nodes act as compute workers and don’t run HDFS, which makes them perfect for aggressively autoscaling with dynamic load requirements. Because task nodes don’t provide HDFS storage, they can be quickly added and removed from the cluster during a resize. Presto doesn’t utilize HDFS, but adding core nodes to a cluster and registering them still has greater overhead than adding task nodes.
The optimal EMR cluster configuration for Presto when data to be queried is located on S3 is one leader node (three leader nodes with EMR 5.23.0 and later for high availability), three to five core nodes, and a fleet of task nodes based on workload.
Tip 2: Selecting appropriate EC2 instance types
When selecting your Amazon Elastic Compute Cloud (Amazon EC2) instance type, keep in mind the following tips regarding nodes:
- Leader node – If the use case requires a high number of concurrent small queries (data scanned less than a hundred Megabytes), Presto needs lots of CPU time. Therefore, a CPU-optimized EC2 instance type such as C5 is If the use case calls for a combination of large queries (data scanned greater than a Terabyte) and medium queries (data scanned between a hundred Megabytes and less than a Terabyte), a memory-optimized EC2 instance such as R4 or R5 works better.
- Core nodes and task nodes – Worker nodes process multiple queries in parallel, and run in-memory query processing. Hence memory-optimized instance types such as R4 or R5 may be preferable.
However testing with real data and queries is the best way to find the most efficient instance type. System monitoring tools, such as Ganglia, can be used to monitor load, memory usage, CPU utilization, and network traffic of the cluster. For example, if the bottleneck is not memory, C5 or M5 may be a cost-effective choice. You can also use Presto’s spill to disk feature to support large outlier queries without changing to more expensive memory-optimized instance types.
Tip 3: Using Spot Instances where possible
One mechanism of controlling costs while also utilizing extra compute capacity is EC2 Spot Instances. Spot Instances make use of unused Amazon EC2 capacity at a reduced cost, with the trade-off being you may lose the EC2 instance. Spot Instances are especially suited for short-lived and transient EMR clusters and when utilizing manual scaling (covered in a later section). If your Presto query workloads mainly consist of small queries, using a blend of On-Demand and Spot Instances in your EMR cluster can significantly increase compute capacity while ensuring cluster stability should you lose some of the Spot Instances. Spot instances may not be appropriate for all types of workloads. For example, workloads with critical SLAs requirements cannot use spot instances. In the event spot instances were taken away, running queries in the terminating spot instances will fail.
Spot Instances don’t work well for large queries, because Presto queries can’t survive a loss of spot instances and the full query run must be restarted from scratch.
You shouldn’t use Spot Instances for the leader and core nodes, because the loss of these nodes causes the loss of the EMR cluster. The blend of On-Demand and Spot Instances likely depends on the strictness of your SLAs. If your SLAs aren’t strict, you can use a higher Spot-to-core ratio. An instance fleet configuration offers the widest variety of provisioning options for EC2 instances. It allows the mix of On-Demand and Spot to be specified for each node type by assigning target capacity for On-Demand and Spot Instances. Amazon EMR moves to On-Demand if Spot Instances aren’t available.
Best practice: Adjust the default Presto server properties
The following tips are in regards to adjusting the default Presto server properties.
Tip 4: Adjusting JVM properties
The location of the JVM properties configuration file is /etc/presto/conf/jvm.config. The following table summarizes our property recommendations.
| Property Name | Recommendations |
| -Xmx |
80% of the node’s memory. Amazon EMR should adjust this value automatically. You just need to double-check to confirm. |
Tip 5: Adjusting Presto server configuration properties
The location of the Presto server configuration file is /etc/presto/conf/config.properties. The following table summarizes the properties, their suggested values, and additional information.
| Property Name | Suggested Value | Comments |
| query.max-queued-queries | 5000 | The maximum number of queries in the query queue. |
| query.max-memory |
Number of nodes * query.max-total-memory-per-node
|
The maximum amount of distributed memory that a query may use.
|
| query.max-memory-per-node |
JVM max memory * 0.2
|
The maximum amount of memory that an individual query may use on any one node. This property can’t be larger than Increasing this value may reduce the available memory for other queries if there is contention due to a large number of queries.
|
| query.max-total-memory-per- node | JVM max memory * 0.4 | The maximum amount of user and system memory that a query may use on any one machine. Increasing this number can improve the performance of large queries. |
| query.max-history | Increase this setting to meet specific query history requirements. |
The size of query history queue.
|
| task.concurrency | Number of vCPU per node. | Number of vCPU per node can be increased if needed |
| query.max-concurrent-queries | 100–1000 | Max number of concurrent running queries; the rest are kept in queue. Lowering this number can reduce the load on the worker nodes and reduce query error rate. |
| task.max-worker-threads | Node CPUs * 4 | Number of worker threads to process splits. |
| node-scheduler.max-splits-per- node | Increase this number by 50% if there are large number of small queries. | Max number of splits each worker node can have. Increasing this property can allow the cluster to handle large batches of small queries more efficiently. |
| task.http-response-threads | 5000 | Max number of threads that may be created to handle HTTP responses. On a system with a large number of requests, increasing this number can help reduce the average query response time. |
| resources.reserved-system- memory | JVM max memory * 0.4 | |
| query.execution-policy | phased | phased or all-at-once. Setting to phased increases the robustness of the query runs and reduces the query errors with high concurrent loads. |
Tip 6: Adjusting EMRFS properties
The EMR File System (EMRFS) is an implementation of HDFS that all EMR clusters use for reading and writing regular files from Amazon EMR directly to Amazon S3. EMRFS provides the convenience of storing persistent data in Amazon S3 for use with Hadoop while also providing features like data encryption.
As of this writing, EMRFS is the preferred protocol to access data on Amazon S3 from Amazon EMR. EMRFS can improve performance and maintain data security. Therefore, we switched from the legacy PrestoFS to EMRFS.
The following table summarizes the properties regarding EMRFS that you can tune.
| Property Name | Configuration File Location | Default Value | Recommendations |
| fs.s3.maxConnections | /usr/share/aws/emr/emrfs /conf/emrfs-site.xml | 500 |
Set to > 10000. This property sets the Amazon S3 connection pool size. (ulimit value may also need to be increased based on value selected.) The error “Timeout waiting for connection from pool” occurs when this value isn’t big enough for the query load.
|
| hive.s3-file-system-type | /etc/presto/conf/catalog/hive.properties | EMRFS |
In Amazon EMR release version 5.12.0 and later, this value should be set to EMRFS by default. Double-check the value to confirm.
|
It’s recommended to not directly modify the configuration property files on a running EMR cluster, such as hive-site.xml. These updates aren’t persisted after the clusters are stopped. The best method to modify the preceding configuration properties in Amazon EMR is using a configuration classification. You can override the default configurations for applications by supplying a configuration object for applications when you create a cluster. The configuration object is referenced as a JSON file. Configuration objects consist of a classification, properties, and optional nested configurations. Properties are the settings you want to change in that file.
Setting custom properties using a configuration classification is the easiest way to guarantee the custom values are set in all node members in the EMR cluster. The custom property values are pushed to all nodes in the cluster, including the leader, core, and task nodes. These values are also applied to new nodes added manually or added by autoscaling policies.
The following code is an example configuration classification for setting custom properties.
Best practice: Scaling EMR to optimize cost and performance
We can do two types of scaling with EMR clusters: manual and automatic. Manual scaling involves using Amazon EMR APIs to change the size of the EMR cluster. Automatic scaling relies on Amazon EMR to scale the cluster on your behalf. Automatic scaling can be done with Auto Scaling released in 2016 or EMR Managed Scaling released in 2020. Unfortunately, both methods of automatic scaling rely on metrics generated by Hadoop YARN applications. Presto doesn’t run as a YARN application, so doesn’t generate these metrics. Presto doesn’t effectively respond to CPU or memory based autoscaling either. As such, automatic scaling doesn’t apply.
Tip 7: Schedule-based manual scaling
You may have predictable, periodic fluctuations in query load. For example, periods of high use during the day with low use at night, or high use at the start of each week. To meet these fluctuations in demand while controlling cost, you can resize EMR clusters, scaling up when query load is high, and scaling down when query load is low. You can perform scaling by resizing an existing instance fleet or instance group. Combined with the use of Spot Instances, it’s possible to scale up to meet very high demand while also tightly controlling costs.
Scaling automatically on a schedule can be achieved with a combination of AWS CloudWatch Events and AWS Lambda. A CloudWatch event can be triggered on a cron schedule. When the event occurs, it can call a Lambda function that uses one the AWS SDKs (such as Python boto3) to resize the EMR cluster. Existing long-running queries on the cluster might fail when the cluster is scaling-in. With EMR version 5.30.0 and later, you can configure the Presto cluster with Graceful Decommission to set a grace period for certain scaling options. The grace period allows Presto tasks to keep running before the node terminates because of a scale-in resize action.
Tip 8: Advanced scaling using automatic scaling based on custom Presto metrics
To get better query performance and minimize cost, automatic scaling based on Presto metrics is highly recommended. Because CloudWatch doesn’t collect Presto-specific metrics, custom code and configuration are required to push these Presto-specific metrics to CloudWatch.
Presto exposes many metrics on JVM, cluster, nodes, tasks, and connectors through Java Management Extension (JMX). Presto also provides a REST API to access these JMX properties. You can use many of these metrics to scale the Presto cluster on your query workloads. See the following examples:
Active queries currently running or queued:
Queries started:
Failed queries from the last 5 minutes (all):
Failed queries from the last 5 minutes (internal):
Failed queries from the last 5 minutes (external):
Failed queries (user):
Execution latency (P50):
Input data rate (P90):
Free memory (general pool):
Cumulative count (since Presto started) of queries that ran out of memory and were stopped:
You can collect the preceding Presto metrics by using Presto’s JMX connector, Presto Rest API, or some open-source libraries, such as presto-metrics. The following diagram shows the high-level architecture for advanced scaling Presto clusters using custom Presto metrics.
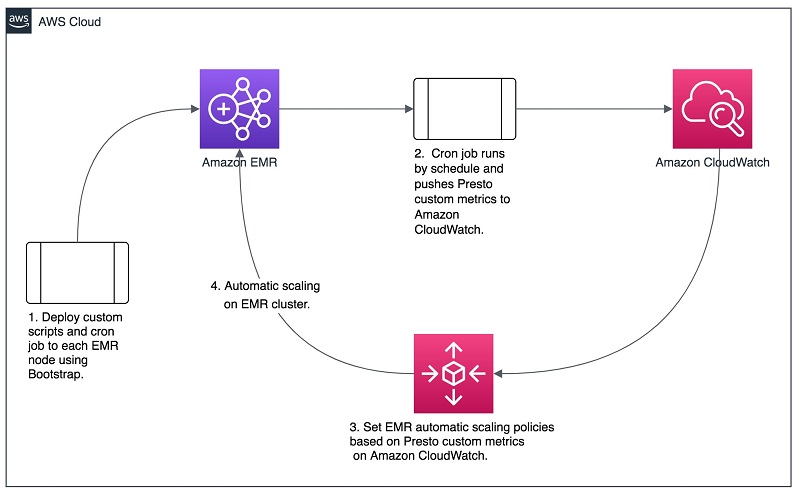
Automatically scaling an EMR cluster using custom CloudWatch metrics
Defining custom scaling policies allows you to scale in and scale out core nodes and task nodes based on custom CloudWatch metrics. Automatic scaling with a custom policy is only available with the instance groups configuration and isn’t available when you use instance fleets or Amazon EMR managed scaling.
To create Amazon EMR custom scaling policies based on custom CloudWatch metrics, first define the EMR instance groups with the custom scaling policy in instancegroupconfig.json.
This JSON file defines a custom scaling policy with a rule called Presto-Scale-out. The rule is triggered when the PrestoFailedQueries5Min custom CloudWatch metric is larger or equal to the threshold of 5 within the evaluation period. See the following code:
Next, create an EMR cluster using the AWS Command Line Interface (AWS CLI).
The following command creates an EMR cluster with a custom automatic scaling policy attached to its core instance group:
In our use case, the custom CloudWatch metric for Presto, PrestoFailedQueries5Min, reached 10 while the scaling rule threshold was greater or equal to 5. The following screenshot shows the metric on the CloudWatch console.
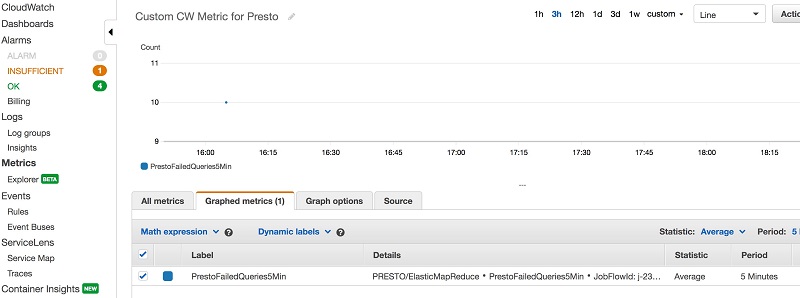
When the PrestoFailedQueries5Min custom CloudWatch Metric is larger or equal to the threshold of 5 within the evaluation period, the Presto-Scale-out rule attached to the core instance group is triggered and the instance group scales out by one node. The following screenshot shows the results of the scaling policy on the Amazon EMR console.

You can also add custom automatic scaling policies to an existing instance group, a new instance group, or an existing EMR cluster. For more information about creating and managing custom automatic scaling policies for Amazon EMR, see Using Automatic Scaling with a Custom Policy for Instance Group.
Best practice: Selecting multiple smaller clusters vs. a single large cluster
In this section we discuss the number of clusters to use and their relative size.
Tip 9: Selecting the amount and size of clusters based on your workloads
For increasing throughput, adding more nodes to a single EMR cluster is almost always a better option. It can utilize more worker nodes to process large queries and generally results in better resource utilization. Some of the largest Presto clusters on Amazon EMR have hundreds to thousands of worker nodes. You can use automatic scaling policies to quickly scale out and in to response to the load. If the use case requires many small queries, the leader node may need more CPU power to better schedule and plan these large number of small queries. Generally, having multiple Presto clusters is used to satisfy HA requirements, such as software upgrades or redundancy.
Conclusion
Presto is a powerful SQL query engine for big data analytics. This post shows a common architecture pattern to use Presto on an EMR cluster as a big data query engine, and shares top performance tuning tips for common performance challenges.
About the Authors
 Richard Mei is a senior data and cloud application architect at AWS. He is dedicated to drive business and IT transformation by leveraging cloud, big data and AI/ML.
Richard Mei is a senior data and cloud application architect at AWS. He is dedicated to drive business and IT transformation by leveraging cloud, big data and AI/ML.
 Chauncy McCaughey is a senior data architect at AWS. His current side project is using statistical analysis of driving habits and traffic patterns to understand how he always ends up in the slow lane.
Chauncy McCaughey is a senior data architect at AWS. His current side project is using statistical analysis of driving habits and traffic patterns to understand how he always ends up in the slow lane.