AWS Compute Blog
Breaking down monolith workflows: Modularizing AWS Step Functions workflows
You can use AWS Step Functions to orchestrate complex business problems. However, as workflows grow and evolve, you can find yourself grappling with monolithic state machines that become increasingly difficult to maintain and update. In this post, we show you strategies for decomposing large Step Functions workflows into modular, maintainable components. We dive deep into architectural patterns like parent-child workflows, domain-based separation, and shared utilities that can help you break down complexity while maintaining business functionality. By implementing these decoupling techniques, you can achieve faster deployments, better error isolation, and reduced operational overhead – all while keeping your workflows scalable and efficient. Whether you’re dealing with payment processing, data transformation, or complex business logic, these patterns will help you build more resilient and manageable Step Functions applications.
The Complexity of Single-State Machine Architectures
While monolithic workflows can be suitable for simple, linear processes with limited states and clear dependencies, they become problematic when handling complex business logic across multiple domains. If your workflow involves more than 15-20 states, crosses multiple business domains, or requires frequent updates from different teams, it’s a strong indicator that you should consider a decomposed approach instead of a monolithic one. However, monolithic workflows remain a valid choice for scenarios with straightforward business logic, single-team ownership, infrequent changes, and workflows with less than 15 states – especially when rapid development and simplified debugging are priorities.
Let’s examine a real-world example of such a monolithic workflow and understand the challenges it presents for development teams, operational efficiency, and business agility. Below is an example of a state machine that is a mix of payment processes, inventory management, and notification mechanisms for an e-commerce implementation:
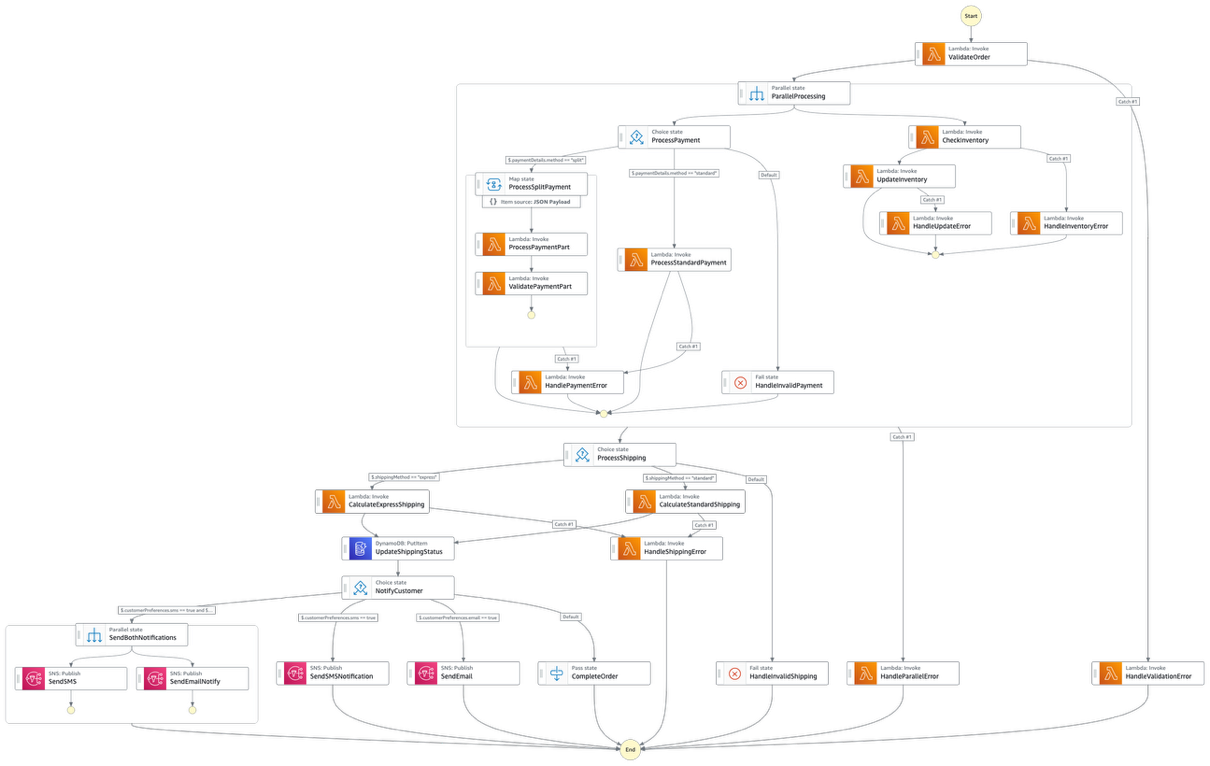
Figure 1: A state machine that is a mix of payment processes, inventory management, and notification mechanisms for an e-commerce implementation
State Explosion
Modifying a single state in a monolithic workflow triggers a cascade of changes across multiple interconnected states due to their tight coupling and dependencies. For example, adding a new payment method would require modifications across various states including validation, processing, and error handling, creating a ripple effect throughout the workflow. This inter dependency makes even simple changes complex and risky, as altering one component can have unintended consequences on other parts of the workflow.
Looking at the provided architecture, we can see a clear example of state explosion where a single workflow handles multiple business processes including order validation, payment processing, inventory management, shipping calculations, and customer notifications. This creates a complex web of dependent states that becomes increasingly difficult to manage. The result is a “spider web” of states that becomes progressively harder to understand, debug, and maintain.
Version Management
Version management in monolithic workflows requires deploying the entire workflow even for minor changes to individual components, making it difficult to isolate and update specific business logic. The provided architecture demonstrates the version management challenge clearly. For instance, if the shipping calculation logic needs an urgent fix, the entire workflow must be redeployed, requiring comprehensive testing of all components, including unmodified ones, to ensure nothing breaks in the process.
Resource Limitations
While not immediately visible in the architecture diagram, Monolithic workflows face operational constraints as they grow in complexity, particularly with state transitions, maximum event payload size, and execution history size. Refer to the Service quotas documentation to understand such limits. These constraints become critical bottlenecks as workflows grow in complexity and handle increased transaction volumes. In the monolithic state machine, long-running operations like payment processing and shipping calculations, combined with multiple state transitions, could approach these limits, especially for high-volume scenarios.
Additionally, we also come across generic design challenges such as error handling. In monolithic approach, workflows leads to redundant try-catch blocks and retry configurations across different operations. This creates challenges in implementing distinct error strategies for different business scenarios and makes it difficult to maintain proper rollback mechanisms when failures occur in middle states.
These challenges collectively highlight the need for a more modular approach to Step Functions workflow design.
Transforming Complex Workflows Through Decomposition
When transforming complex monolithic workflows into more manageable components, you can employ several decomposition strategies to achieve better modularity and maintainability. These strategies include the parent-child pattern, which creates a hierarchical structure of workflows, domain separation that breaks down workflows based on business capabilities, shared utilities that serve as reusable components for common operations, and specialized error workflows for centralized error handling. Each of these strategies can be implemented either individually or in combination, depending on the specific requirements and complexity of the application, allowing organizations to create more efficient, scalable, and maintainable Step Functions workflows while ensuring proper separation of concerns and reduced operational overhead.
Parent-Child Pattern
The parent-child pattern represents a hierarchical approach to workflow organization where a main (parent) workflow orchestrates multiple sub-workflows (children). Parent workflows manage the overall business process and coordination, while child workflows handles specific, short-lived operations. This pattern is particularly effective when you need to balance between orchestration complexity and execution speed.
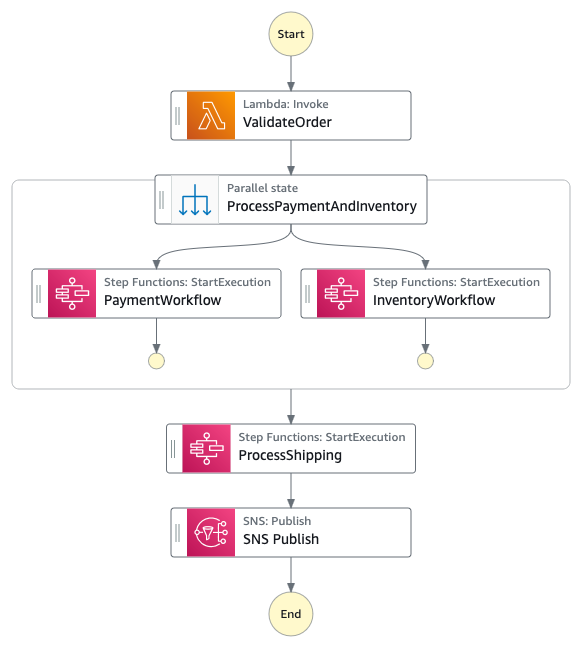
Figure 2 : Decoupled parent state machine
Kindly note that during an architecture re-vamp, Express workflows are different when compared to Standard Workflows. For example, you cannot have an Express parent workflow invoke a Standard child workflow. Also, an Express workflow does not support Job-run (.sync) or Callback (.waitForTaskToken) service integration patterns. You can refer to the differences between Standard and Express workflows documentation to choose the right architecture pattern.
For instance, the payment processing section could be transformed into a child Express workflow that handles all payment-related states (ProcessPayment, ProcessStandardPayment, ValidatePaymentPart) as a single unit. An express workflow is more suitable for sections like payment processing as their executions complete within 5 minutes. Hence this would also reduce the over-all cost of the workflow. Similarly, the shipping calculation logic involving CalculateExpressShipping and CalculateStandardShipping could be consolidated into another Express child workflow, leading to reduced costs and easier updates to shipping logic.
Domain Separation
Domain separation involves breaking down workflows based on distinct business capabilities or functional areas. Each domain-specific workflow becomes responsible for a complete business function, operating independently while communicating through well-defined interfaces. This approach aligns closely with micro-service architecture principles and domain-driven design. The architecture shows clear boundaries between different business domains that can be separated into independent workflows. Three primary domains emerge:
- Payment Domain: Encompassing ValidateOrder, ProcessPayment, ValidatePaymentPart, and related error handlers
- Inventory Domain: Including CheckInventory, UpdateInventory, and associated states
- Shipping Domain: Containing ProcessShipping, shipping calculations, and shipping status updates
Each domain would become its own workflow, with clear input/output contracts. This separation would allow specialized teams to maintain and deploy updates to their domain workflows independently ensuring implementation of domain-specific retry policies, error handling, and business rules without affecting other domains. For example, the payment team could enhance payment processing logic without impacting shipping or inventory operations.
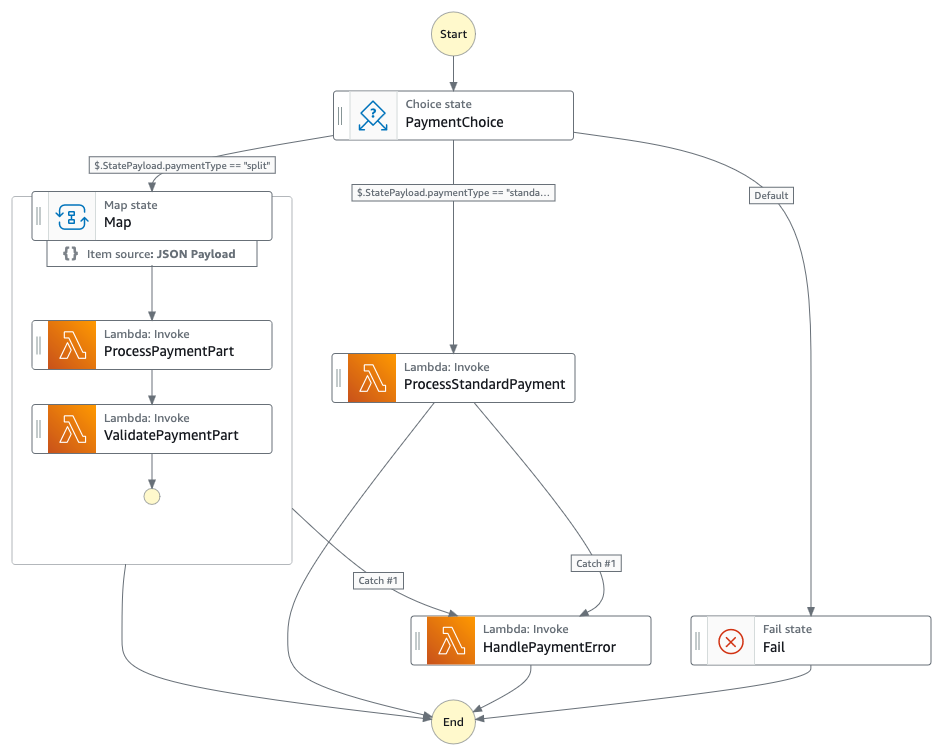
Figure 3 : Child state machine that handles payment workflow
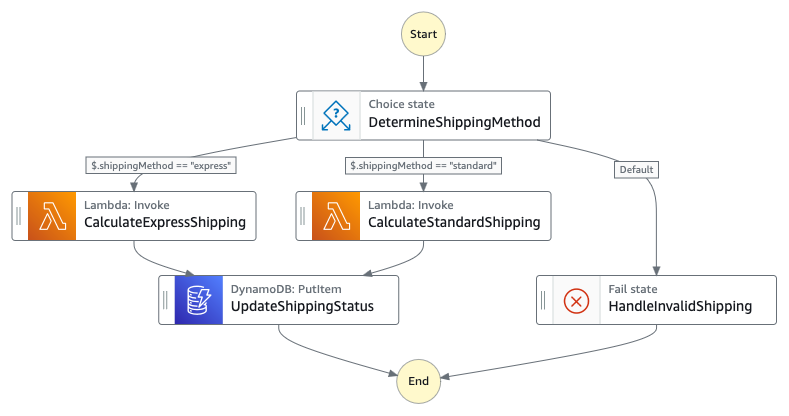
Figure 4 : Child state machine that handles shipping workflow
Shared utility workflows serve as reusable components for common operations that appear across multiple business processes. These workflows encapsulate standard functionality like notification handling, data validation, logging, or audit trail creation. By centralizing these common operations, organizations can ensure consistency and reduce duplication across their Step Functions applications.
The current architecture repeats several common patterns that could be extracted into shared utility workflows. Most notably, the notification handling logic (SendEmail, SendSMSNotification, SendPushNotification) appears as a cluster of states at the end of the workflow. This could be consolidated into a single “NotificationManager” utility workflow that handles all types of notifications. These utility workflows could then be called from any other workflow in the system, ensuring consistent behavior and reducing code duplication.
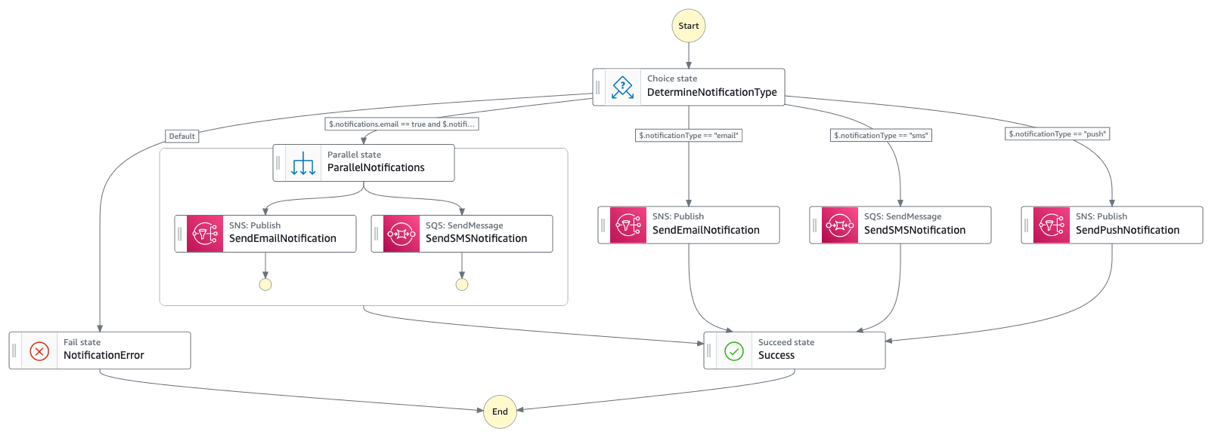
Figure 5 : Re-usable notification workflow
Error Workflows
Error workflows represent a specialized form of decomposition focused on centralizing error handling and recovery logic. Instead of embedding complex error handling in each business workflow, organizations can create dedicated workflows that manage different types of failures, retries, and compensation actions. This approach provides a consistent and maintainable way to handle errors across the application.
Each of these decomposition strategies can be used individually or in combination, depending on the specific needs of your application. For instance, utilization of Domain Separation pattern has resulted in streamlined error workflows. The key is to choose the appropriate combination that provides the right balance of maintainability, scalability, and operational efficiency for your use case. However, implementing all four strategies in a phased approach would provide the most comprehensive solution for long-term maintainability and scalability.
Results:
The comparison between monolithic and decoupled approaches reveals notable differences in performance and operational metrics. In order to emulate similar test environments across monolithic and decomposed state machines, we tested them in us-east-1 AWS region. We made use of the aforementioned workflows, both monolithic and decomposed to achieve a similar end goal. Pricing comparison is based on a monolithic workflow processing 11 state transitions per workflow across 30,000 monthly requests. For the decomposed approach, calculations assume Express child workflows configured with 64MB memory and 100ms execution duration, while the parent workflow handles 8 state transitions per workflow for the same volume of 30,000 monthly requests. AWS Lambda task states in both approaches complete within 2 seconds of execution time.
When decoupled, the workflows can be re-designed to use either Express or Standard mechanisms depending on their execution time and integration pattern requirements. In this use-case, we identified multiple workflows like PaymentProcessing, CalculateExpressShipping that are revamped to use Express workflows as per their requirement. While the monolithic approach shows a slightly faster execution duration of 11.5 seconds compared to 13 seconds in the decomposed approach, the monthly pricing significantly favors the decoupled architecture at $6.37 USD versus $11.90 USD for the monolithic approach. The decoupled approach demonstrates superior debugging capabilities with better error isolation and domain-specific debugging, contrasting with the monolithic approach’s complex debugging challenges due to heavy payloads and middle-state failure tracking. Additionally, the decoupled architecture benefits from smaller payload sizes through distributed data handling, whereas the monolithic workflow carries larger payloads across its 18 state transitions.
| Monolithic Approach | Decoupled Approach | |
| Execution Duration | 11.5 seconds for complete workflow execution | 13 seconds with distributed processing across parent-child workflows |
| Monthly Pricing | $11.90 USD (476,000 billable state transitions) | $6.37 USD (Combined cost of Standard parent workflow and Express child workflows) |
| Debug Effort | High – Complex debugging due to heavy payloads and difficulty in tracking failures in middle states. Cannot effectively use ResultSelector when final notification state needs all details. | Lower – Easier to debug with isolated domains and smaller payloads. Better error isolation and domain-specific debugging. |
| Payload Size | Larger payload size throughout workflow execution as all data needs to be carried across 18 state transitions | Smaller payload size due to domain separation and distributed data handling across parent-child workflows |
Conclusion
The need for decomposing Step Functions workflows becomes evident when you face challenges with monolithic workflows such as state explosion, version management complexities, and resource limitations. These challenges result in reduced operational efficiency, increased debugging complexity, and higher maintenance overhead as demonstrated by the comparison results showing differences in execution duration, pricing, debugging effort, and payload management. Organizations should evaluate workflow decomposition when they observe workflows exceeding 15-20 states, multiple team involvement in workflow maintenance, frequent independent updates across different business domains, complex error handling requirements, and the need for reusable components across workflows. The implementation of decomposition strategies through parent-child pattern for hierarchical workflow organization, domain separation for business capability isolation, shared utilities for common operations, and dedicated error workflows for centralized error handling has shown tangible benefits in terms of reduced costs, better error isolation, and more efficient payload management.
While implementing decomposition strategies, organizations must be cautious to avoid over-decomposition of workflows, maintaining tight coupling between workflows, and ignoring core design principles of loose coupling and single responsibility. This strategic approach to workflow decomposition ultimately leads to more maintainable, scalable, and cost-effective Step Functions applications that better serve business needs while reducing operational overhead. The transformation from monolithic to decomposed workflows represents a significant architectural improvement that enables organizations to better manage complex business processes while maintaining operational efficiency and system reliability.