AWS Compute Blog
Category: Amazon Textract

Orchestrating large-scale document processing with AWS Step Functions and Amazon Bedrock batch inference
Organizations often have large volumes of documents containing valuable information that remains locked away and unsearchable. This solution addresses the need for a scalable, automated text extraction and knowledge base pipeline that transforms static document collections into intelligent, searchable repositories for generative AI applications.
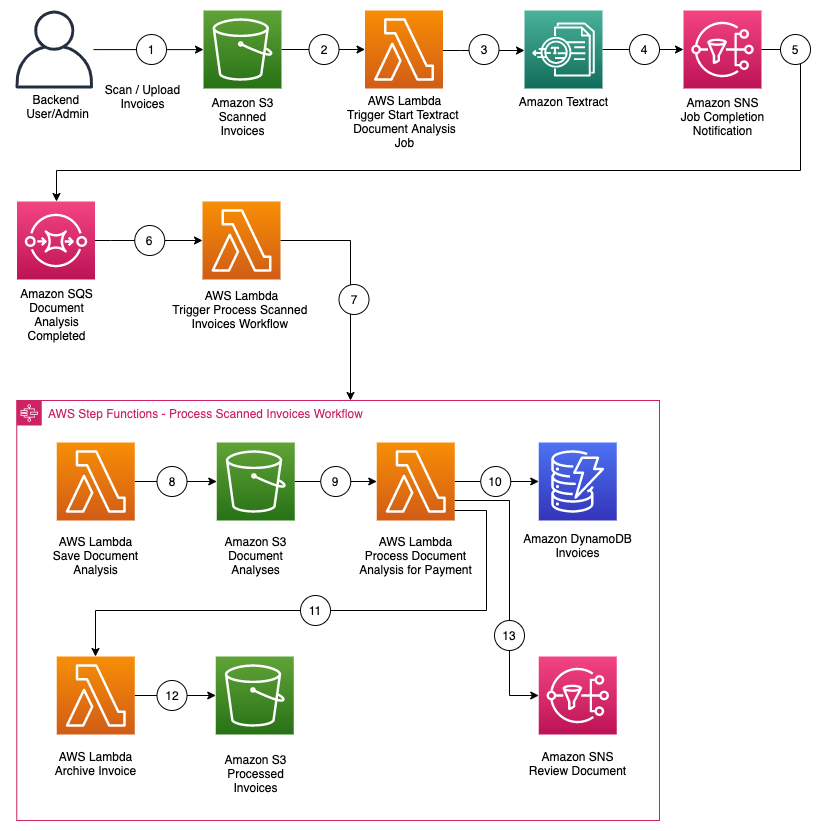
Getting started with RPA using AWS Step Functions and Amazon Textract
This post is courtesy of Joe Tringali, Solutions Architect. Many organizations are using robotic process automation (RPA) to automate workflow, back-office processes that are labor-intensive. RPA, as software bots, can often handle many of these activities. Often RPA workflows contain repetitive manual tasks that must be done by humans, such as viewing invoices to find […]

Building a serverless document scanner using Amazon Textract and AWS Amplify
This guide demonstrates creating and deploying a production ready document scanning application. It allows users to manage projects, upload images, and generate a PDF from detected text. The sample can be used as a template for building expense tracking applications, handling forms and legal documents, or for digitizing books and notes. The frontend application is […]