AWS Compute Blog
Introducing Native Support for Predictive Scaling with Amazon EC2 Auto Scaling
This post is written by Scott Horsfield, Principal Solutions Architect, EC2 Scalability and Ankur Sethi, Sr. Product Manager, EC2
Amazon EC2 Auto Scaling allows customers to realize the elasticity benefits of AWS by automatically launching and shutting down instances to match application demand. Today, we are excited to tell you about predictive scaling. It is a new EC2 Auto Scaling policy that predicts demand surges, and proactively increases capacity ahead of time, resulting in higher availability. With predictive scaling, you can avoid the need to overprovision capacity, resulting in lower Amazon EC2 costs. Predictive scaling has been available through AWS Auto Scaling plans since 2018 but you can now use it directly as an EC2 Auto Scaling group configuration alongside your other scaling policies. In this blog post, we give you an overview of predictive scaling and illustrate a scenario that this feature helps you with. We also walk you through the steps to configure a predictive scaling policy for an EC2 Auto Scaling group.
Product Overview
EC2 Auto Scaling offers a suite of dynamic scaling policies including target tracking, simple scaling and step scaling. Scaling policies are customer-defined guidelines for when to add or remove instances in an Auto Scaling group based on the value of a certain Amazon CloudWatch metric that represents an application’s load. EC2 Auto Scaling constantly monitors the metric and reacts according to customer-defined policies to trigger the launch of additional number of instances.
Given the inherently reactive nature of dynamic scaling policies, you may find it useful to use predictive scaling in addition to dynamic scaling when:
- Your application demand changes rapidly but with a recurring pattern. For example, weekly increases in capacity requirement as business resumes after weekends.
- Your application instances require a long time to initialize.
Now, you can easily configure predictive scaling alongside your existing dynamic scaling policies to increase capacity in advance of a predicted demand increase. You no longer have to overprovision your Auto Scaling group or spend time manually configuring scheduled scaling for routine demand patterns. Predictive scaling uses machine learning to predict capacity requirements based on historical usage and continuously learns on new data to make forecasts more accurate.
A primer on EC2 Auto Scaling capacity parameters
When you launch an Auto Scaling group, you define the minimum, maximum, and desired capacity, expressed as number of EC2 instances. Minimum and maximum capacity are the customer-defined lower and upper boundaries of the Auto Scaling group. Desired capacity is the actual capacity of an Auto Scaling group and is constantly calibrated by EC2 Auto Scaling. With predictive scaling, AWS is introducing a new parameter called predicted capacity.
Every day, predictive scaling forecasts the hourly capacity needed for each of the next 48 hours. Then, at the beginning of each hour, the predicted capacity value is set to the forecasted capacity needed for that hour. At any point of time, three scenarios play out for your Auto Scaling group when using predictive scaling:
- If actual capacity is lower than predicted capacity, EC2 Auto Scaling scales out your Auto Scaling group so that its desired capacity is equal to the predicted capacity.
- If actual capacity is already higher than predicted capacity, EC2 Auto Scaling does not scale-in your Auto Scaling group.
- If the predicted capacity is outside the range of minimum and maximum capacity that you defined, EC2 Auto Scaling does not violate those limits.
Note that predictive scaling policy is not designed for use on its own because it does not trigger scale-in events. It only triggers scale-out events in anticipation of predicted demand. Therefore, you should use predictive scaling with another dynamic scaling policy, either provided by AWS or your own custom scaling automation. Dynamic scaling scales in capacity when it’s no longer needed. Each policy determines its capacity value independently, and the desired capacity is set to the higher value. This ensures that your application scales out when real-time demand is higher than predicted demand.
Predictive scaling policies operate in two modes: Forecast Only or Forecast And Scale. Forecast Only mode allows you to validate that predictive scaling accurately anticipates your routine hourly demand. This is a great way to get started with predictive scaling without impacting your current scaling behavior. Also, you can create multiple policies in Forecast Only mode to compare different configurations, such as forecasting on different metrics. Once you verify the predictions, a simple update is required to switch to Forecast And Scale mode for the policy configuration that is best-suited for your Auto Scaling group. Now that you have an understanding of this new feature, let’s walk through the steps to set it up.
Getting started with Predictive Scaling
In this section, we walk you through steps to add a predictive scaling policy to an Auto Scaling group. But first, let’s look at how dynamic scaling reacts when the demand increases rapidly. To illustrate, we created a load simulation that you can use to follow along by deploying this example AWS CloudFormation Stack in your account. This example deploys two Auto Scaling groups. The first Auto Scaling group is used to run a sample application and is configured with an Application Load Balancer (ALB). The second Auto Scaling group is for generating recurring requests to the application running on the first Auto Scaling group through the ALB. For this example, we have applied a target tracking policy to maintain CPU utilization at 25% to automatically scale the first Auto Scaling group running the application.
The following graph illustrates how dynamic scaling adjusts capacity (blue line) with changing load (red line). We are interested in the ALB Response Time metric (green line). It represents the time an application takes to process and respond to the incoming requests from the ALB. It is a good representation of the latency observed by the end users of the application. Therefore, any spike observed in this metric (green line) results in bad user experience.
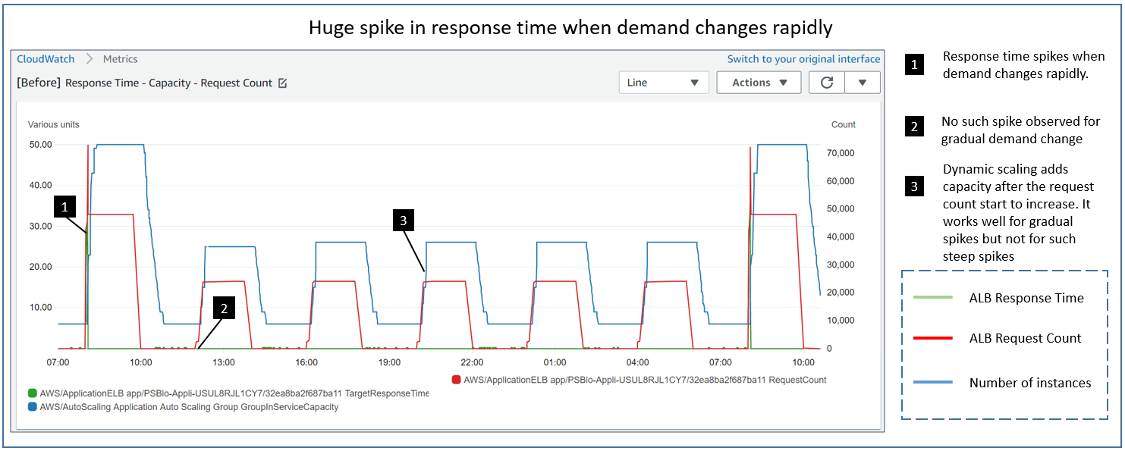
As you can see, there are recurring periods of increased requests (red line) of different ramp-up velocity. For example, from 16:00 to 18:00 UTC, before stabilizing, the load increase is relatively more gradual than what is observed for 08:00 to 10:00 UTC time range. The ALB Response Time metric (green line) remains low for the former period of gradual ramp-up. However, for the latter steep ramp-up, while auto scaling is adding the required number of instances (blue line), we observe a spike in the response time. Let’s zoom in to have a better look at the response time metric.
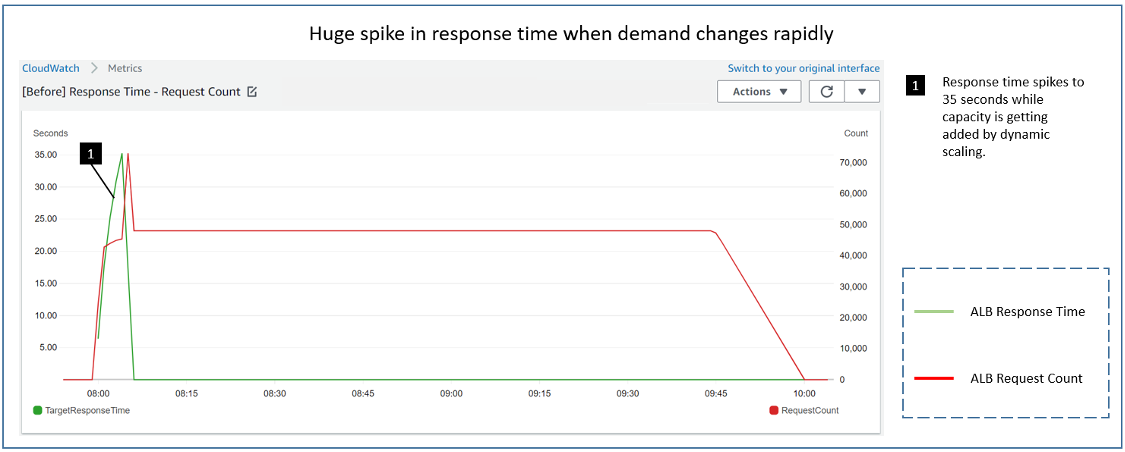
In the preceding graph, we see the response time spikes to as high as 35 seconds for the first 5 minutes of the hour before dropping down to subsecond level. Because dynamic scaling is reactive in nature, it failed to keep up with the steep demand change observed here. This may be acceptable for applications that are not sensitive to these latencies. But for others, predictive scaling helps you better manage such scenarios, by setting the baseline capacity proactively at the beginning of the hour.
We’ll now walk you through the steps to configure a predictive scaling policy. Note that, predictive scaling requires at least 24 hours of historical load data to generate forecasts. If you are using the preceding example, allow it to run for 24 hours for the load data to be generated.
Configure Predictive Scaling policy in Forecast Only mode
First, configure your Auto Scaling group with a predictive scaling policy in Forecast Only mode so that you can review the results of the forecast and adjust any parameters to more accurately reflect the behavior you desire.
To do so, create a scaling configuration file where you define the metrics, target value, and the predictive scaling mode for your policy. The following example produces forecasts based on CPU Utilization, with each instance handling 25% of the average hourly CPU utilization for the Auto Scaling group. You can further customize these policies based on the needs of your workload.
Once you have created the configuration file, you can run the following command to add the predictive scaling policy to your Auto Scaling group.
Reviewing Predictive Scaling forecasts
With the scaling policy in place, and 24 hours of historical load data, you can now use predictive scaling forecasts API to review the forecasted load and forecasted capacity for the Auto Scaling group. You can also use the console to review forecasts by navigating to the Amazon EC2 console, clicking Auto Scaling Groups, selecting the Auto Scaling group that you configured with predictive scaling, and viewing the predictive scaling policy located under the Automatic Scaling section of the Auto Scaling group details view. In the policy details, a chart represents the LoadForecast and CapacityForecast, showing what is forecasted for the next 48 hours, in addition to previous forecasts and actual average instance counts. The following screenshot demonstrates the forecasts for the policy just applied to the Auto Scaling group. The orange line represents the actual values, blue line represents the historic forecast, while the green line represents the forecast for next 2 days.
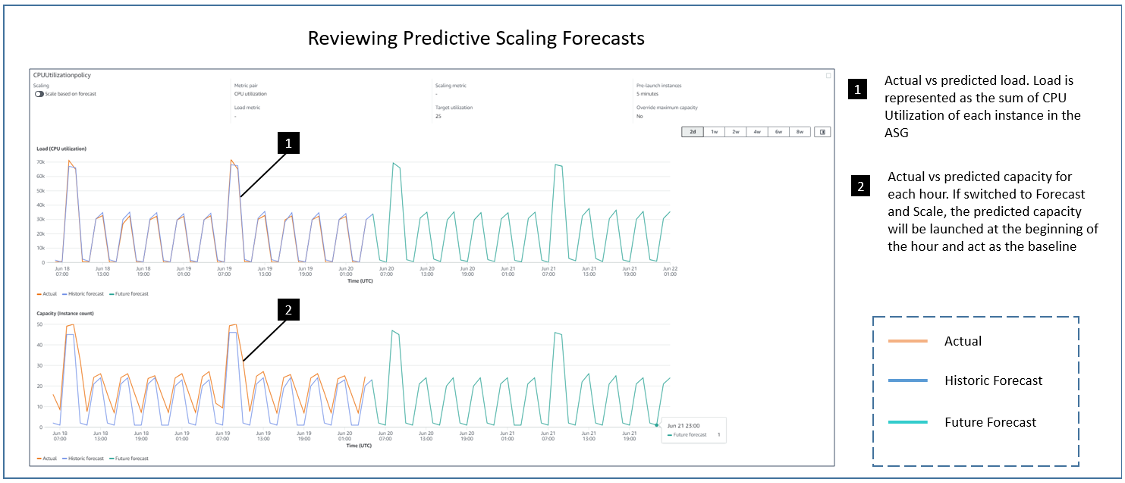
The upper graph shows that the load forecast against the actual load observed. Since the scaling policy based its forecasts on Auto Scaling group CPU Utilization, the load forecast reflects the total forecasted CPU load your Auto Scaling group must handle hourly. The lower graph shows the corresponding capacity forecast against the actual. As you can see, the forecast gets more accurate with time. Predictive scaling constantly learns about the pattern and improves the forecast accuracy as it gets more data points to forecast on.
For this example, the predictive scaling policy calculates capacity such that instances in an Auto Scaling group consume 25% of the CPU load on average for each hour. Predictive scaling also provides three other predefined metric configurations to help you quickly set up forecasts on metrics other than CPU. You can create multiple predictive scaling policies in Forecast Only mode based on different metrics and target value to determine which scaling policy is the best match for your workload. This helps you compare the behavior of the predictive scaling policy for existing workloads without impacting your current configuration. The current forecasts seem fairly accurate, so we will stick with the same configurations.
Configure scaling policies in forecast and scale mode
When you are ready to allow predictive scaling to automatically adjust your Auto Scaling group’s hourly capacity, you can easily update one of the scaling policies to allow Forecast And Scale directly on the console. Else, to switch modes, create a new predictive scaling policy configuration file with the “Mode” set to “ForecastAndScale”. You can do this with the following command:
Using the configuration file generated, run the following command to update the CPU Predictive Scaling policy.
With this updated scaling policy in place, the Auto Scaling group’s predicted capacity will now change hourly based on the predictive scaling forecasts. The predicted capacity, which acts as the baseline for an hour, will be launched at the beginning of the hour itself. You may configure to further advance the launch time according to the time an instance takes to get provisioned and warmed-up.
Impact of Switching-On Predictive Scaling
Now that we have switched to ForecastAndScale mode and predictive scaling is actively scaling the Auto Scaling group, let’s revisit the ALB Request Time metric for the Auto Scaling group.
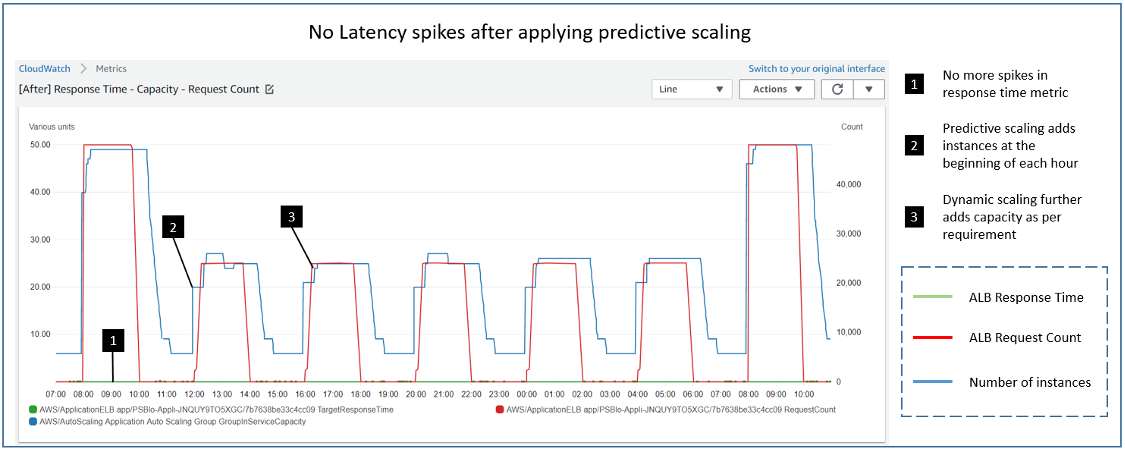
As you can see in the preceding screenshot, prior to the steep demand (8:00 – 10:00 UTC), 40 instances (blue line) have been added in a single step by predictive scaling. The dynamic scaling policy continues to add the remaining 9 instances required for the increasing demand. Because of the combined effect of both scaling policies, we no longer observe the spike in the response time metric (green line). Let’s zoom into the specific time frame to get a better look.
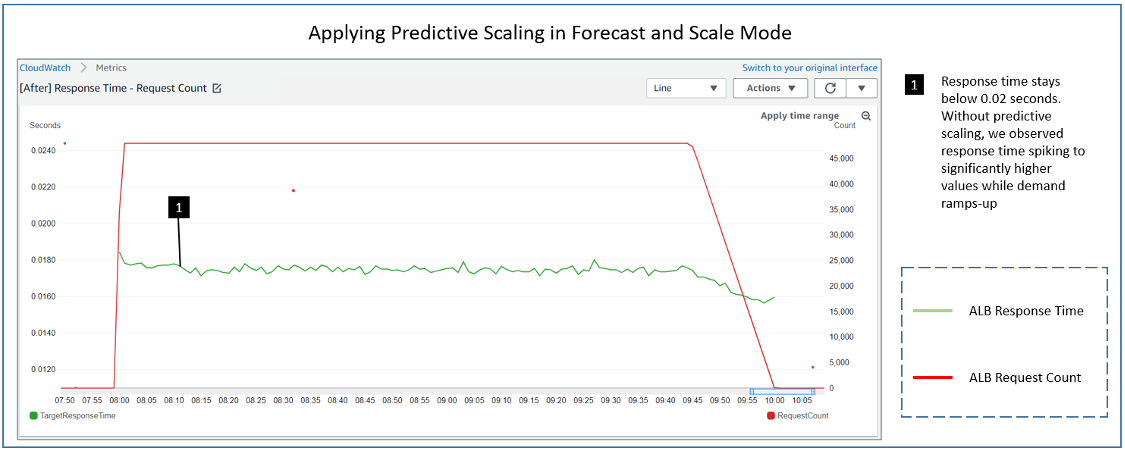
Throughout, the response time remains less than 0.02 seconds compared to reaching as high as 35 seconds earlier when we were only using dynamic scaling. By launching the instances ahead of steep demand change, predictive scaling has improved the end users’ experience. You do not need to resort to overprovisioning or do manual interventions to scale out your Auto Scaling groups ahead of such demand patterns. As long as there is predictable pattern, auto scaling enhanced with predictive scaling maintains high availability for your applications.
If you are using the example stack, do not forget to clean up after you are done testing the feature by deleting the stack.
Conclusion
Predictive scaling, when combined with dynamic scaling, help you ensure that your EC2 Auto Scaling group workloads have the required capacity to handle predicted and real-time load. You can allow predictive scaling on existing Auto Scaling groups in Forecast Only mode to gain visibility of the predicted capacity without actually taking any scaling actions. You can refine and tune your predictive scaling policies by choosing one of the four predefined metrics and adjusting its target value as necessary. Once completed, you can switch to Forecast And Scale mode to proactively scale your Auto Scaling group capacity based on predicted demand. By using predictive scaling and dynamic scaling together, your Auto Scaling group will have the capacity it needs to meet demand, which can improve your application’s responsiveness and reduce your EC2 costs. To learn more about the feature, refer the EC2 Auto Scaling User Guide.