AWS Compute Blog
Patterns for building an API to upload files to Amazon S3
This blog is written by Thomas Moore, Senior Solutions Architect and Josh Hart, Senior Solutions Architect.
Applications often require a way for users to upload files. The traditional approach is to use an SFTP service (such as the AWS Transfer Family), but this requires specific clients and management of SSH credentials. Modern applications instead need a way to upload to Amazon S3 via HTTPS. Typical file upload use cases include:
- Sharing datasets between businesses as a direct replacement for traditional FTP workflows.
- Uploading telemetry and logs from IoT devices and mobile applications.
- Uploading media such as videos and images.
- Submitting scanned documents and PDFs.
If you have control over the application that sends the uploads, then you can integrate with the AWS SDK from within the browser with a framework such as AWS Amplify. To learn more, read Allowing external users to securely and directly upload files to Amazon S3.
Often you must provide end users direct access to upload files via an endpoint. You could build a bespoke service for this purpose, but this results in more code to build, maintain, and secure.
This post explores three different approaches to securely upload content to an Amazon S3 bucket via HTTPS without the need to build a dedicated API or client application.
Using Amazon API Gateway as a direct proxy
The simplest option is to use API Gateway to proxy an S3 bucket. This allows you to expose S3 objects as REST APIs without additional infrastructure. By configuring an S3 integration in API Gateway, this allows you to manage authentication, authorization, caching, and rate limiting more easily.
This pattern allows you to implement an authorizer at the API Gateway level and requires no changes to the client application or caller. The limitation with this approach is that API Gateway has a maximum request payload size of 10 MB. For step-by-step instructions to implement this pattern, see this knowledge center article.
This is an example implementation (you can deploy this from Serverless Land):

Using API Gateway with presigned URLs
The second pattern uses S3 presigned URLs, which allow you to grant access to S3 objects for a specific period, after which the URL expires. This time-bound access helps prevent unauthorized access to S3 objects and provides an additional layer of security.
They can be used to control access to specific versions or ranges of bytes within an object. This granularity allows you to fine-tune access permissions for different users or applications, and ensures that only authorized parties have access to the required data.
This avoids the 10 MB limit of API Gateway as the API is only used to generate the presigned URL, which is then used by the caller to upload directly to S3. Presigned URLs are straightforward to generate and use programmatically, but it does require the client to make two separate requests: one to generate the URL and one to upload the object. To learn more, read Uploading to Amazon S3 directly from a web or mobile application.
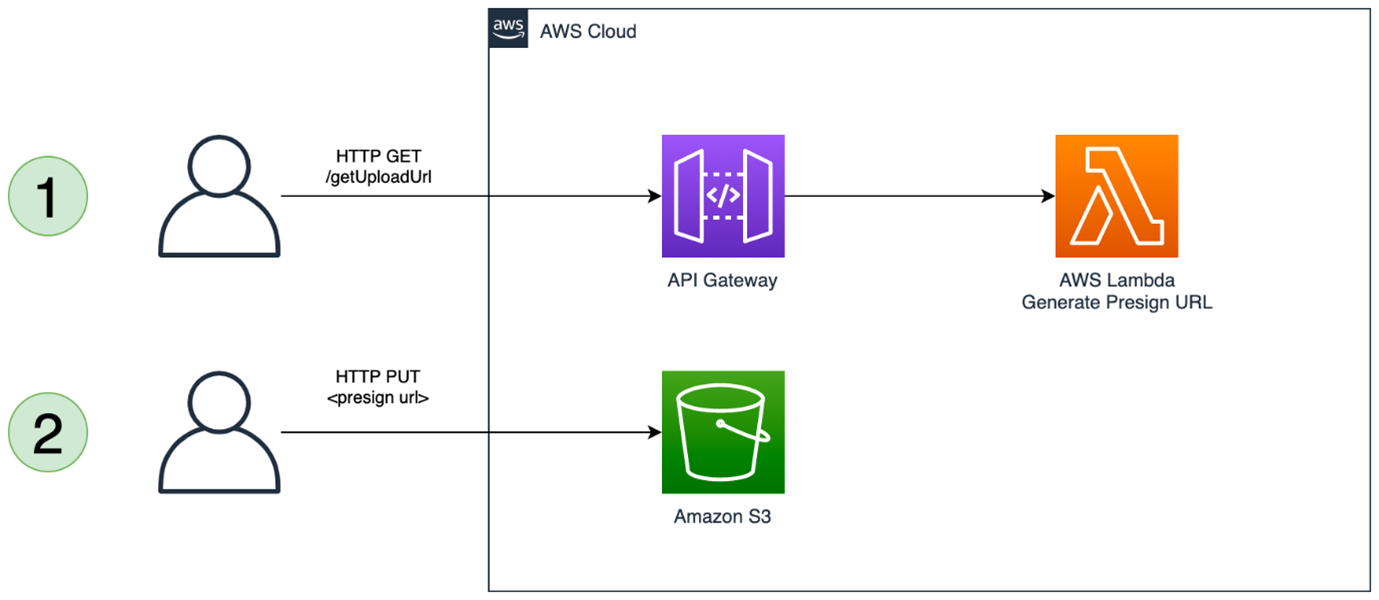
This pattern is limited by the 5GB maximum request size of the S3 Put Object API call. One way to work around this limit with this pattern is to leverage S3 multipart uploads. This requires that the client split the payload into multiple segments and send a separate request for each part.
This adds some complexity to the client and is used by libraries such as AWS Amplify that abstract away the multipart upload implementation. This allows you to upload objects up to 5TB in size. For more details, see uploading large objects to Amazon S3 using multipart upload and transfer acceleration.
An example of this pattern is available on Serverless Land.
Using Amazon CloudFront with Lambda@Edge
The final pattern leverages Amazon CloudFront instead of API Gateway. CloudFront is primarily a content delivery network (CDN) that caches and delivers content from an S3 bucket or other origin. However, CloudFront can also be used to upload data to an S3 bucket. Without any additional configuration, this would essentially make the S3 bucket publicly writable. To secure the solution so that only authenticated users can upload objects, you can use a Lambda@Edge function to verify the users’ permissions.
The maximum size of the object that you can upload with this pattern is 5GB. If you need to upload files larger than 5GB, then you must use multipart uploads. To implement this, deploy the example Serverless Land pattern:

This pattern uses an origin access identity (OAI) to limit access to the S3 bucket to only come from CloudFront. The default OAI has s3:GetObject permission, which is changed to s3:PutObject to allow uploads explicitly and prevent and read operations:
{
"Version": "2008-10-17",
"Id": "PolicyForCloudFrontPrivateContent",
"Statement": [
{
"Sid": "1",
"Effect": "Allow",
"Principal": {
"AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity <origin access identity ID>"
},
"Action": [
"s3:PutObject"
],
"Resource": "arn:aws:s3::: DOC-EXAMPLE-BUCKET/*"
}
]
}
As CloudFront is not used to cache content, the managed cache policy is set to CachingDisabled.
There are multiple options for implementing the authorization in the Lambda@Edge function. The sample repository uses an Amazon Cognito authorizer that validates a JSON Web Token (JWT) sent as an HTTP authorization header.
Using a JWT is secure as it implies this token is dynamically vended by an Identity Provider, such as Amazon Cognito. This does mean that the caller needs a mechanism to obtain this JWT token. You are in control of this authorizer function, and the exact implementation depends on your use-case. You could instead use an API Key or integrate with an alternate identity provider such as Auth0 or Okta.
Lambda@Edge functions do not currently support environment variables. This means that the configuration parameters are dynamically resolved at runtime. In the example code, AWS Systems Manager Parameter Store is used to store the Amazon Cognito user pool ID and app client ID that is required for the token verification. For more details on how to choose where to store your configuration parameters, see Choosing the right solution for AWS Lambda external parameters.
To verify the JWT token, the example code uses the aws-jwt-verify package. This supports JWTs issued by Amazon Cognito and third-party identity providers.
The Serverless Land pattern uses an Amazon Cognito identity provider to do authentication in the Lambda@Edge function. This code snippet shows an example using a pre-shared key for basic authorization:
import json
def lambda_handler(event, context):
print(event)
response = event["Records"][0]["cf"]["request"]
headers = response["headers"]
if 'authorization' not in headers or headers['authorization'] == None:
return unauthorized()
if headers['authorization'] == 'my-secret-key':
return request
return response
def unauthorized():
response = {
'status': "401",
'statusDescription': 'Unauthorized',
'body': 'Unauthorized'
}
return response
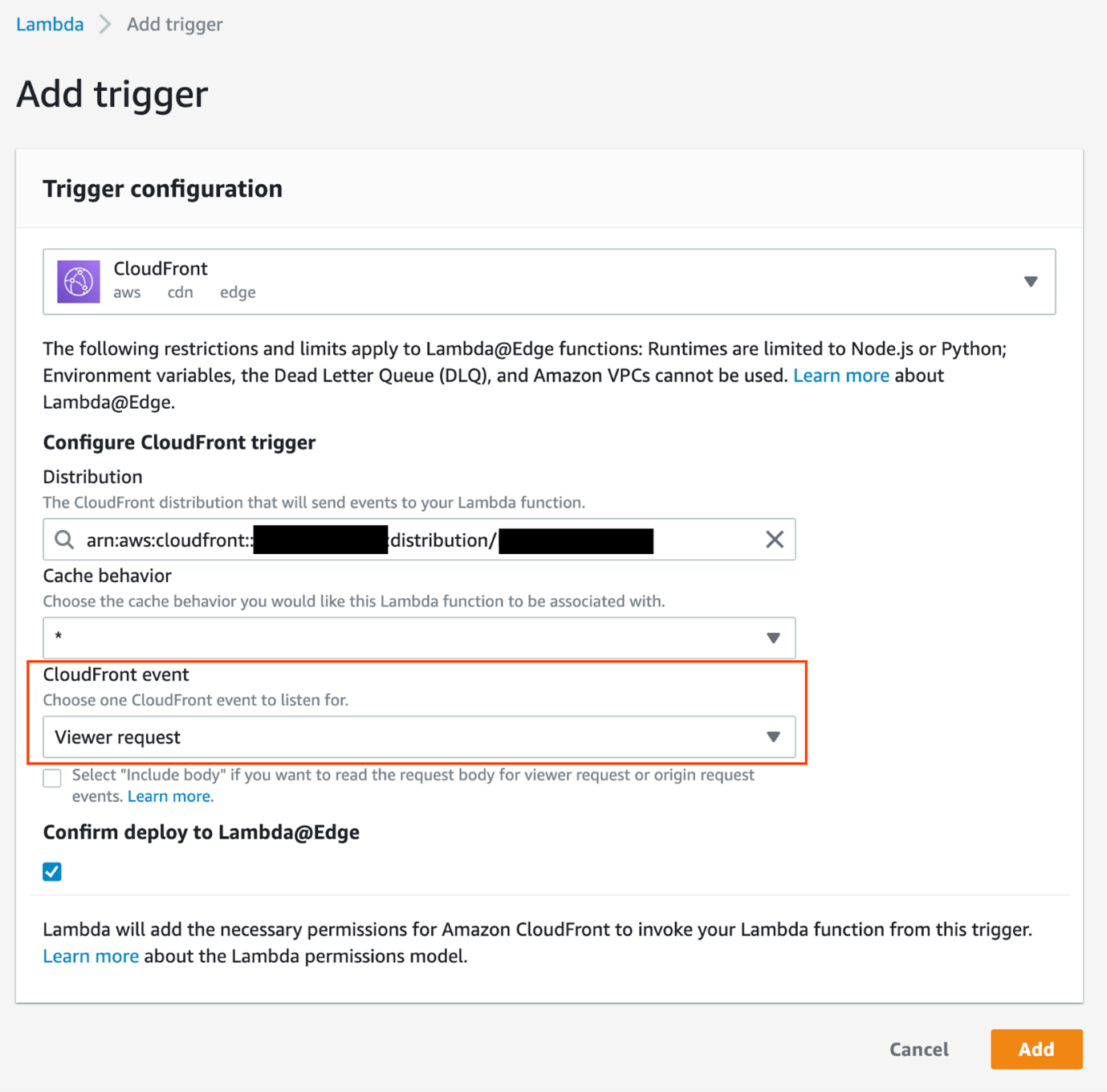
The Lambda function is associated with the CloudFront distribution by creating a Lambda trigger. The CloudFront event is set Viewer request to meaning the function is invoked in reaction to PUT events from the client.
The solution can be tested with an API testing client, such as Postman. In Postman, issue a PUT request to https://<your-cloudfront-domain>/<object-name> with a binary payload as the body. You receive a 401 Unauthorized response.
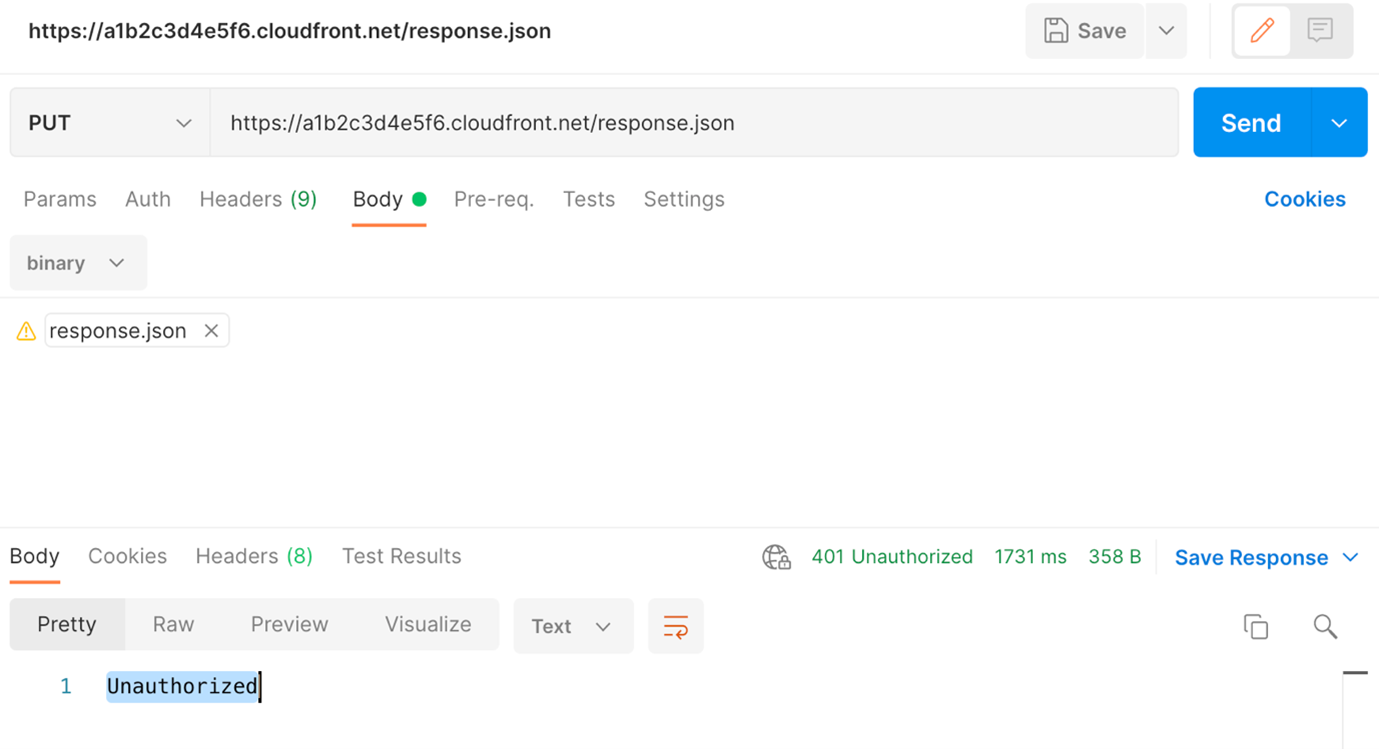
Next, add the Authorization header with a valid token and submit the request again. For more details on how to obtain a JWT from Amazon Cognito, see the README in the repository. Now the request works and you receive a 200 OK message.
To troubleshoot, the Lambda function logs to Amazon CloudWatch Logs. For Lambda@Edge functions, look for the logs in the Region closest to the request, and not the same Region as the function.
The Lambda@Edge function in this example performs basic authorization. It validates the user has access to the requested resource. You can perform any custom authorization action here. For example, in a multi-tenant environment, you could restrict the prefix so that specific tenants only have permission to write to their own prefix, and validate the requested object name in the function.
Additionally, you could implement controls traditionally performed by the API Gateway such as throttling by tenant or user. Another use for the function is to validate the file type. If users can only upload images, you could validate the content-length to ensure the images are a certain size and the file extension is correct.
Conclusion
Which option you choose depends on your use case. This table summarizes the patterns discussed in this blog post:
| API Gateway as a proxy | Presigned URLs with API Gateway | CloudFront with Lambda@Edge | |
| Max Object Size | 10 MB | 5 GB (5 TB with multipart upload) | 5 GB |
| Client Complexity | Single HTTP Request | Multiple HTTP Requests | Single HTTP Request |
| Authorization Options | Amazon Cognito, IAM, Lambda Authorizer | Amazon Cognito, IAM, Lambda Authorizer | Lambda@Edge |
| Throttling | API Key throttling | API Key throttling | Custom throttling |
Each of the available methods has its strengths and weaknesses and the choice of which one to use depends on your specific needs. The maximum object size supported by S3 is 5 TB, regardless of which method you use to upload objects. Additionally, some methods have more complex configuration that requires more technical expertise. Considering these factors with your specific use-case can help you make an informed decision on the best API option for uploading to S3.
For more serverless learning resources, visit Serverless Land.