AWS Compute Blog
Scheduling GPUs for deep learning tasks on Amazon ECS
This post is contributed by Brent Langston – Sr. Developer Advocate, Amazon Container Services
Last week, AWS announced enhanced Amazon Elastic Container Service (Amazon ECS) support for GPU-enabled EC2 instances. This means that now GPUs are first class resources that can be requested in your task definition, and scheduled on your cluster by ECS.
Previously, to schedule a GPU workload, you had to maintain your own custom configured AMI, with a custom configured Docker runtime. You also had to use custom vCPU logic as a stand-in for assigning your GPU workloads to GPU instances. Even when all that was in place, there was still no pinning of a GPU to a task. One task might consume more GPU resources than it should. This could cause other tasks to not have a GPU available.
Now, AWS maintains an ECS-optimized AMI that includes the correct NVIDIA drivers and Docker customizations. You can use this AMI to provision your GPU workloads. With this enhancement, GPUs can also be requested directly in the task definition. Like allocating CPU or RAM to a task, now you can explicitly request a number of GPUs to be allocated to your task. The scheduler looks for matching resources on the cluster to place those tasks. The GPUs are pinned to the task for as long as the task is running, and can’t be allocated to any other tasks.
I thought I’d see how easy it is to deploy GPU workloads to my ECS cluster. I’m working in the US-EAST-2 (Ohio) region, from my AWS Cloud9 IDE, so these commands work for Amazon Linux. Feel free to adapt to your environment as necessary.
If you’d like to run this example yourself, you can find all the code in this GitHub repo. If you run this example in your own account, be aware of the instance pricing, and clean up your resources when your experiment is complete.
Clone the repo using the following command:
Setup
You need the latest version of the AWS CLI (for this post, I used 1.16.98):
While AWS CloudFormation is provisioning resources, examine the template used to build your infrastructure. Open cluster-cpu-gpu.yml, and you see that you are provisioning a test VPC with two c5.2xlarge instances, and two p3.2xlarge instances. This gives you one NVIDIA Tesla V100 GPU per instance, for a total of two GPUs to run training tasks.
I adapted the TensorFlow benchmark Docker container to create a training workload. I use this container to compare the GPU scheduling and runtime.
When the CloudFormation stack is deployed, register a task definition with the ECS service:
To request GPU resources in the task definition, the only change needed is to include a GPU resource requirement in the container definition:
Including this resource requirement ensures that the ECS scheduler allocates the task to an instance with a free GPU resource.
Launch a single-GPU training workload
Now you’re ready to launch the first GPU workload.

When you launch the task, the output shows the gpuIds values that are assigned to the task. This GPU is pinned to this task, and can’t be shared with any other tasks. If all GPUs are allocated, you can’t schedule additional GPU tasks until a running task with a GPU completes. That frees the GPU to be scheduled again.
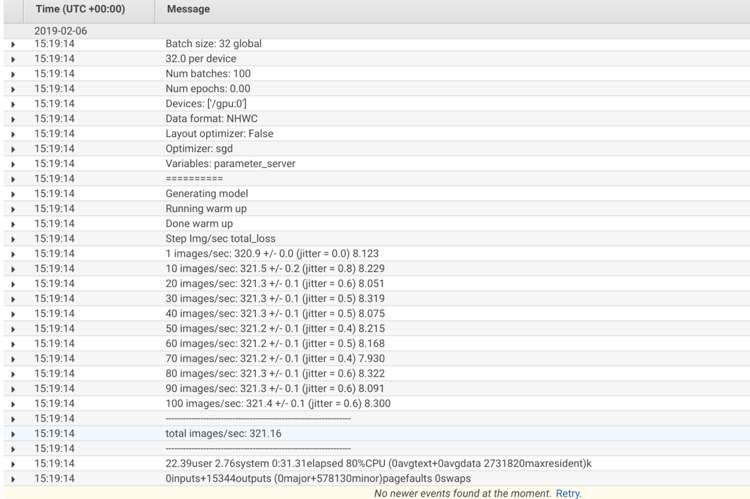
When you look at the log output in Amazon CloudWatch Logs, you see that the container discovered one GPU: /gpu0 and the training benchmark trained at a rate of 321.16 images/sec.
With your two p3.2xlarge nodes in the cluster, you are limited to two concurrent single GPU based workloads. To scale horizontally, you could add additional p3.2xlarge nodes. This would limit your workloads to a single GPU each. To scale vertically, you could bump up the instance type, which would allow you to assign multiple GPUs to a single task. Now, let’s see how fast your TensorFlow container can train when assigned multiple GPUs.
Launch a multiple-GPU training workload
To begin, replace the p3.2xlarge instances with p3.16xlarge instances. This gives your cluster two instances that each have eight GPUs, for a total of 16 GPUs that can be allocated.
When the CloudFormation deploy is complete, register two more task definitions to launch your benchmark container requesting more GPUs:
Next, launch two TensorFlow benchmark containers, one requesting four GPUs, and one requesting eight GPUs:
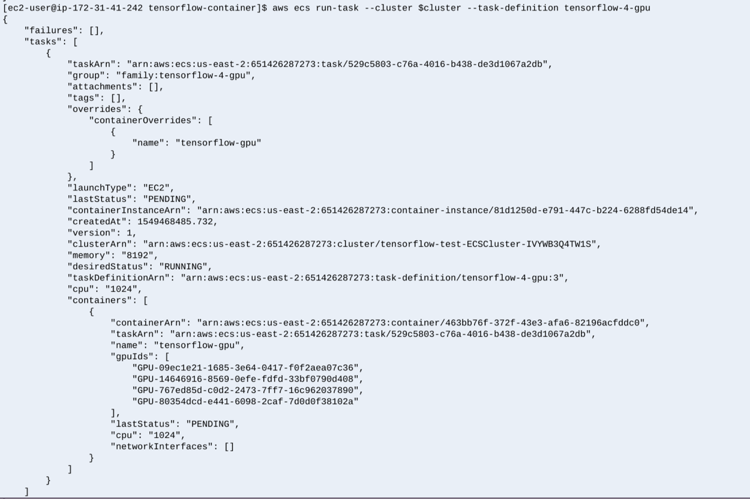
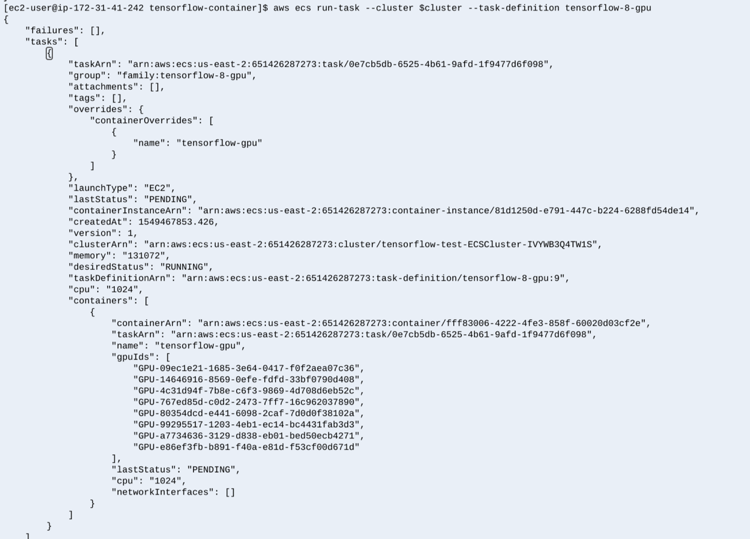
With each task request, GPUs are allocated: four in the first request, and eight in the second request. Again, these GPUs are pinned to the task, and not usable by any other task until these tasks are complete.
Check the log output in CloudWatch Logs:
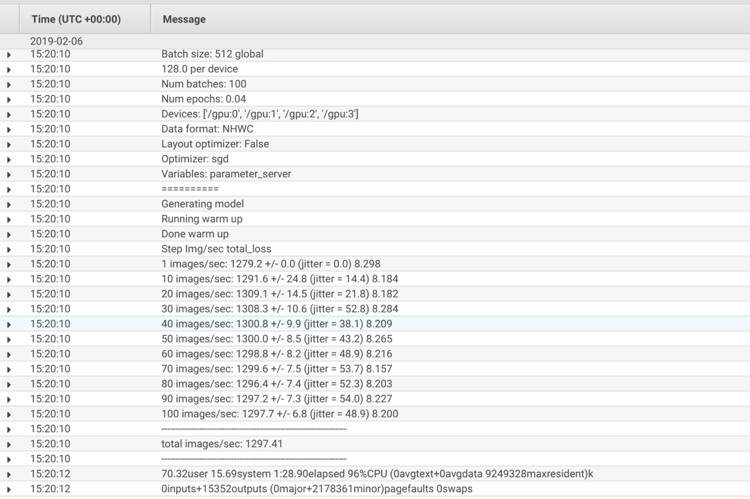
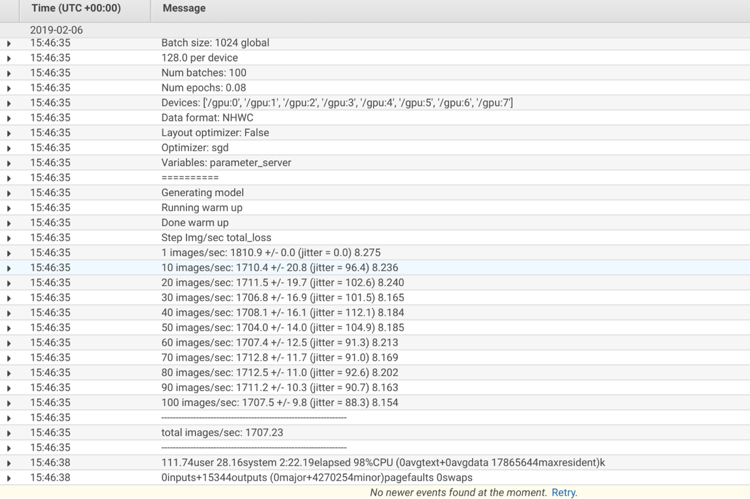
On the “devices” lines, you can see that the container discovered and used four (or eight) GPUs. Also, the total images/sec improved to 1297.41 with four GPUs, and 1707.23 with eight GPUs.
Because you can pin single or multiple GPUs to a task, running advanced GPU based training tasks on Amazon ECS is easier than ever!
Cleanup
To clean up your running resources, delete the CloudFormation stack:
Conclusion
For more information, see Working with GPUs on Amazon ECS.
If you want to keep up on the latest container info from AWS, please follow me on Twitter and tweet any questions! @brentContained