Containers
Running Slurm on Amazon EKS with Slinky
When building an AI infrastructure stack for pre-training, fine-tuning, or inference workloads, both Slurm and Kubernetes can be used as compute orchestration platforms to meet the needs of different teams and address different stages of the AI development lifecycle. However, traditionally this would result in managing disparate clusters of accelerated compute capacity, potentially duplicating operational overhead and risking resource underuse. But what if you could deploy a Slurm cluster as a Kubernetes service to get the best of both worlds?
Think of Kubernetes as a large, modern office building providing shared resources (for example, electricity, internet, security, HVAC) for its tenants. When a specialized lab moves in, needing dedicated resources such as specific power and temperature control, you don’t build a new building. Instead, you integrate the lab into the existing building infrastructure, allowing it to use shared services while maintaining its own precise controls for high-performance work. In the same way, Slurm can be ran inside a Kubernetes environment such as Amazon Elastic Kubernetes Service (Amazon EKS) using the open source Slinky Project.
In this post, we introduce the Slinky Project, discuss its benefits, explore some alternatives, and leave you with a bit of homework to go deploy the Slurm on EKS blueprint, which uses the Slinky Slurm operator.
A primer on Slurm
Slurm is an open source, highly scalable workload manager and job scheduler designed for managing compute resources on compute clusters of all sizes. It provides three core functions: allocating access to compute resources, providing a framework for launching and monitoring parallel computing jobs, and managing queues of pending work to resolve resource contention.
Slurm is widely used in traditional High-Performance Computing (HPC) environments and in AI training to manage and schedule large-scale accelerated compute workloads across multi-node clusters. Slurm allows researchers and engineers to efficiently allocate CPU, GPU, and memory resources for distributed training jobs with fine-grained control over resource types and job priorities. Slurm’s reliability, advanced scheduling features, and integration with both on-premises and cloud environments make it a preferred choice for handling the scale, throughput, and reproducibility that modern AI research and industry demand.
The Slinky Project
The Slinky Project is an open source suite of integration tools designed by SchedMD (the lead developers of Slurm) to bring Slurm capabilities into Kubernetes, combining the best of both worlds for efficient resource management and scheduling. The Slinky Project includes a Kubernetes operator for Slurm clusters, which implements custom-controllers and custom resource definitions (CRDs) to manage the lifecycle of Slurm Cluster and NodeSet resources deployed within a Kubernetes environment.
The use case for Slinky
The Slinky Project is specifically designed for organizations that need to manage both long-running, resource-intensive batch jobs and rapidly scaling, service-oriented workloads using a combination of Slurm for its deterministic scheduling and fine-grained resource control, and Kubernetes for its dynamic resource allocation and rapid scalability. For example, research institutions engaged in genome sequencing or climate modeling can run complex, multi-hour simulations using the reliable batch job management of Slurm. Simultaneously, they can host responsive APIs or microservices that benefit from rapid auto scaling with Kubernetes. Across industries, optimizing the use of compute resources and reducing operational overhead are primary drivers in controlling cost. You can use Slinky to standardize your cloud infrastructure on Kubernetes to make operations more efficient while maintaining Slurm capabilities for research teams that need it. All of this can be done on an aggregated compute footprint that makes the most of the resources you have.
Architecture overview of Slurm on EKS with Slinky
The following diagram shows how Slinky can be deployed on Amazon EKS. The central management daemon, slurmctld, and other core components (not shown) are deployed on general purpose nodes, while slurmd, the compute node daemon of Slurm, is deployed on accelerated nodes. An Amazon FSx for Lustre file system is also mounted to the slurmd pods for high-performance shared storage, and an Amazon Web Services (AWS) Network Load Balancer is configured to route traffic to the login pods. This architecture can be deployed and tested using the Slurm on EKS blueprint.
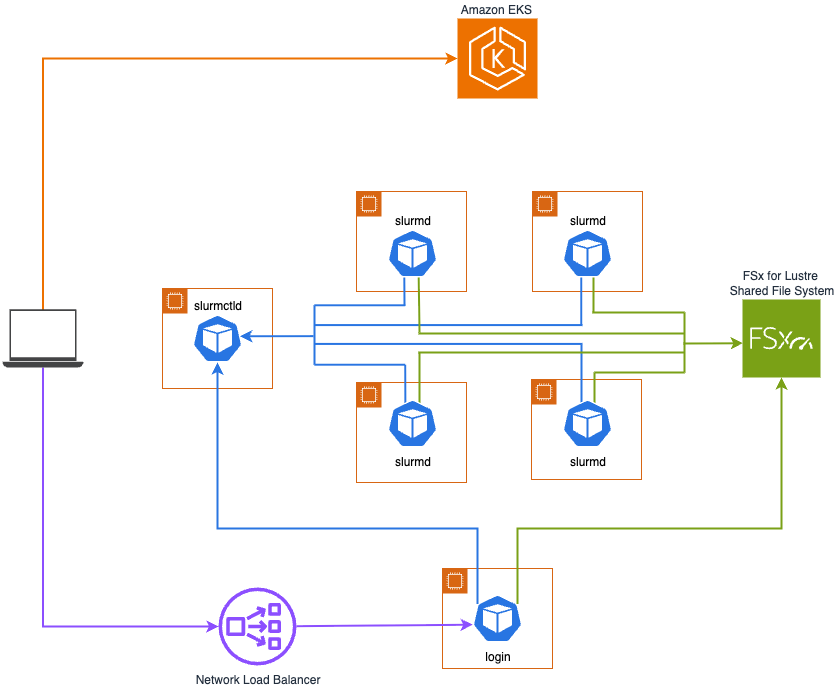
Slinky Slurm cluster components
A containerized Slinky Slurm cluster uses components that are functionally similar to those in a traditional Slurm cluster:
The controller pod, sometimes referred to as the head node, runs the slurmctld central management daemon that monitors resources, accepts jobs, and assigns work to compute nodes.
The accounting pod runs the slurmdbd daemon, which interfaces with a backend MariaDB database for archiving and managing accounting records, such as job usage and resource allocation information. By default, the backend MariaDB database is hosted as part of the Slurm cluster Kubernetes deployment, but it can be configured for external hosting using services such as Amazon Relational Database Service (Amazon RDS) for MariaDB as well.
The REST API pod runs the slurmrestd daemon to provide HTTP-based API access to the Slurm cluster for programmatic interaction. The REST API is used by the NodeSet controller to manage the lifecycle of worker node pods, and also by the Slurm cluster metrics exporter to collect telemetry data for monitoring and observability.
The worker node pods run the slurmd daemon, which monitors all running tasks, accepts new incoming tasks for launch, and kills running tasks upon request. These pods run exclusively on your accelerated compute EC2 instances based on the nodeSelector and resource quota specifications provided. Pods can also be grouped into different partitions to map them to specific hardware resources and scheduling constraints. This allows jobs with similar requirements to be managed and prioritized efficiently within a cluster. The Slurm operator considers the workloads currently running on the compute pods and marks them as drain to allow existing jobs to complete before terminating them for scale-in or upgrade operations. The Slurm operator supports scaling the compute pods down to zero replicas with any horizontal pod autoscaler (HPA) that supports scale to zero operations.
Login pods provide workspaces for users to interact with the Slurm cluster. Users can use a login pod to stage data, prepare their jobs for submission, and submit those jobs when they are ready using familiar Slurm commands such as sbatch, srun, and salloc. Login pods support authentication through the sackd daemon. Slurm’s internal authentication relies on a subsystem called the Slurm Auth and Cred Kiosk (SACK), which is handled internally by the slurmctld, slurmdbd, and slurmd daemons. The sackd daemon specifically serves login nodes that don’t have these other Slurm daemons running, enabling them to authenticate with the rest of the cluster and run Slurm client commands. For SSH access, login pods include sshd, which is the OpenSSH server process that listens for and handles incoming SSH client connections. Login pod access can also be configured with the system security services daemon (sssd) that manages access to remote directory services such as AWS Directory Service using protocols such as the Lightweight Directory Access Protocol (LDAP).
The Slurm cluster metrics exporter collects Slurm telemetry data about jobs, nodes, and partitions from the REST API, then exports that data as Prometheus metric types for monitoring and observability with tools such as Amazon Managed Service for Prometheus and Amazon Managed Grafana. For more advanced configurations, the exported metrics can also be used to configure an HPA such as KEDA to scale worker node pods based on custom metrics such as the number of pending jobs for a partition.
Benefits of running Slurm on EKS with Slinky
Slinky streamlines hybrid workload management by allowing Slurm and Kubernetes applications to run on the same infrastructure. This unified approach is ideal for organizations handling some combination of real-time and batch workloads, such as running AI training and inference, or running scientific simulations and data-intensive analytics along with modern cloud-native applications. These workloads are often managed by different teams with varying levels of operational experience and tool preferences. With both Slurm and Kubernetes workloads sharing the same set of nodes, Slinky maximizes resource usage so that organizations can avoid dedicating separate infrastructure to different workload types, while giving teams the flexibility to continue to work in familiar paradigms.
The dynamic autoscaling capabilities mean that the Slurm operator can automatically provision or decommission worker node pods based on workload demands. Slinky monitors Slurm job queues and responds in real-time, adding worker node pods when demand spikes and scaling down as jobs complete or queues clear. This allows organizations to dynamically shift how their cloud compute resources are used. For example, Kubernetes-based AI inference workloads that may take up a larger compute footprint during business hours can scale out in response to increased traffic, while Slurm-based training jobs can scale out after-hours based on the job queue without any additional reconfiguration. When combined with Karpenter or the Cluster Autoscaler, this can further improve cost efficiency when using on-demand EC2 compute. Alternatively, On-Demand Capacity Reservations (ODCRs) or Capacity Blocks for ML by passing reservation IDs to the Karpenter node class capacityReservationSelectorTerms or managed node group launch template.
Consistency is achieved using container images for Slurm components, making sure that applications and dependencies behave identically in development, staging, and production with repeatable and reliable deployments. Slinky also supports flexibility and customization with user-defined Slurm container images. Using custom container images allows specialized libraries, dependencies, and configurations to be built into the environment. For example, the AWS Deep Learning Containers can be combined with the slurmd daemon to create worker node pods that have specific version of NCCL, CUDA, and PyTorch pre-installed. This gives teams granular control over their dependency chain without relying on manually provisioned Python or Conda virtual environments.
Alternatives for running Slurm on AWS
Organizations standardizing on Slurm have multiple options for setting up their HPC or AI training environments on AWS, ranging in the level of service management they provide and how extensible or targeted their prime use cases are.
AWS ParallelCluster
For teams that need full control to tailor their cloud infrastructure based on a validated HPC reference architecture, AWS ParallelCluster is an AWS-supported open source solution that automates the setup of self-managed Slurm clusters. AWS ParallelCluster features a command line interface distributed as a Python package and a self-hosted web-based user interface that provides a console-like experience. AWS ParallelCluster also integrates with AWS CloudFormation (using a custom resource) and Terraform to enable infrastructure as code (IaC) management. AWS ParallelCluster offers a high degree of control and self-service customization to specify the operating system, custom software, and scheduler configurations of your Slurm clusters.
AWS Parallel Computing Service
For teams looking for a more fully managed Slurm experience for their HPC workloads, AWS Parallel Computing Service (AWS PCS) streamlines cluster operations with automatic Slurm controller patch updates, managed Slurm accounting, and queues for Slurm partitioning, helping to remove the burden of maintenance and management. AWS PCS is directly accessible through the AWS Management Console, the AWS SDK, and the AWS Command Line Interface (AWS CLI). The lifecycle of an AWS PCS cluster can also be managed using IaC with the first-party AWS PCS CloudFormation resource type or with the AWS PCS Terraform AWS Cloud Control provider. In essence, AWS PCS provides Slurm controller, accounting, and partitioning features as a managed service.
Amazon SageMaker HyperPod
For teams that need to train foundation models (FMs) with maximum efficiency, Amazon SageMaker HyperPod is purpose-built for automating and optimizing large-scale distributed machine learning (ML) workloads. Unlike AWS ParallelCluster or AWS PCS, HyperPod offers persistent, self-healing clusters with advanced resiliency features such as cluster health checks, automatic node replacement, job auto-resume, and multi-head node support, minimizing downtime even during long training runs. SageMaker HyperPod uses AWS Deep Learning Amazon Machine Images (DLAMIs) that come pre-installed with the essential packages for deep integration with AWS Trainium accelerators and NVIDIA GPUs. Teams can use Slurm orchestration with SageMaker HyperPod to provide familiar job scheduling and flexible partitioning, while offering the ability to customize environments, install specialized ML frameworks, and access advanced monitoring tools with Amazon Managed Service for Prometheus and Amazon Managed Grafana.
Alternative Kubernetes native job schedulers
Organizations standardizing on Amazon EKS who want to use Kubernetes-native job schedulers for managing their HPC or AI training workloads have multiple open source tools available. In this section we review a few popular options.
Volcano
Volcano stands out as a powerful batch scheduler purpose-built for compute-intensive workloads, making it ideal for teams running large-scale distributed HPC, big data or AI training jobs. Volcano integrates with kube-scheduler through plugins to augment node filtering and scoring. Its support for advanced scheduling policies, such as gang scheduling, network topology awareness, and dynamic GPU partitioning, allows resource-heavy, multi-node training jobs to launch only when all necessary resources are available, maximizing parallelism and GPU usage. Volcano also enables workload colocation and dynamic oversubscription, making sure that that resource usage remains high without sacrificing the quality of service for online workloads. These features are useful for research or production AI teams that need optimal throughput, fine-tuned control over resource management, and are comfortable integrating sophisticated scheduling strategies into their workflows.
Apache YuniKorn
Apache YuniKorn is designed with multi-tenancy, hierarchical resource sharing, and fairness as its core differentiators, making it very useful for organizations operating shared Kubernetes clusters with multiple teams. YuniKorn replaces the default kube-scheduler with a standalone custom scheduler and introduces app-aware scheduling, where users, applications and queues are recognized when making scheduling decisions, enabling fine-grained control over resource quotas and prioritizing jobs across queues. Preemption make sure that critical, high-priority AI workloads do not get stalled behind lower-priority jobs. Its ability to enforce resource fairness and hierarchical quota management makes YuniKorn particularly valuable for enterprises or academic environments with competing ML teams, each needing guaranteed access to cluster resources without manual intervention or bottlenecks.
Kueue
Kueue offers a Kubernetes-native job queueing and orchestration experience, focusing on clarity and incremental adoption. Kueue complements the default kube-scheduler by handling job-level management for queueing and suspending jobs as well as evaluating job resource quotas and priority assignments. Teams benefit from deterministic scheduling, automated fair job admission, and efficient GPU sharing, while still using familiar Kubernetes primitives. Kueue’s approach is well-suited to platform engineering teams, startups, or organizations looking for a minimal-disruption, cloud-native solution where maintaining existing scheduler compatibility and ease of integration are top priorities, but advanced job queueing and fair allocation are still needed for scalable AI training workloads.
When Slurm on EKS is right for you
AWS provides multiple options for deploying Slurm clusters in the cloud, and the open source Kubernetes community offers an evolving variety of job scheduling operators. However, the Slinky Project is specifically designed for organizations that need to manage both real-time and batch workloads using a combination of Slurm for its deterministic scheduling and fine-grained resource control and Kubernetes for its dynamic resource allocation and rapid scalability.
Workloads such as chatbots or virtual assistants are characterized by fluctuating demand, short-lived jobs, and the need for high availability and quick scaling. Here Kubernetes excels with dynamic resource allocation, rapid scalability, and high availability for services and APIs in cloud-native environments. Workloads such as HPC and AI training jobs on the other hand, tend to benefit from Slurm’s deterministic scheduling and fine-grained resource control across static clusters because of their long runtimes, high resource consumption, and more predictable computational needs.
Organizations can run Slurm on Kubernetes with Slinky to efficiently orchestrate heterogeneous workloads using a unified, cloud-native infrastructure. This approach avoids the need to maintain separate, siloed clusters and allows dynamic resource sharing, improving overall usage and adaptability to changing computational needs. Instead of forcing teams to change how they interact with Slurm or Kubernetes, Slinky lets users keep their established Slurm scripts and commands, while allowing new workloads to run using container orchestration tools familiar to cloud-native practitioners.
Get started today by trying out Slinky with the new Slurm on EKS blueprint.
About the authors
 Nathan Arnold is a Senior AI/ML Specialist Solutions Architect at AWS based out of Austin Texas. He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. When he’s not working with customers, writing Terraform modules, or tinkering with the latest open source tools, he enjoys hiking, trail running, and playing with his four dogs.
Nathan Arnold is a Senior AI/ML Specialist Solutions Architect at AWS based out of Austin Texas. He helps AWS customers—from small startups to large enterprises—train and deploy foundation models efficiently on AWS. When he’s not working with customers, writing Terraform modules, or tinkering with the latest open source tools, he enjoys hiking, trail running, and playing with his four dogs.