Containers
Scaling a Large Language Model with NVIDIA NIM on Amazon EKS with Karpenter
Many organizations are building artificial intelligence (AI) applications using Large Language Models (LLMs) to deliver new experiences to their customers, from content creation to customer service and data analysis. However, the substantial size and intensive computational requirements of these models may have challenges in configuring, deploying, and scaling them effectively on graphic processing units (GPUs). Moreover, these organizations would also like to achieve low-latency and high-performance inference in a cost-efficient way.
To help deploying LLMs, NVIDIA introduced NVIDIA Inference Microservices (NIM) containers. These containers are designed to streamline and accelerate the deployment of LLMs by using the capability of Kubernetes with these benefits:
- Streamlines AI model deployment and management for developers and IT teams.
- Optimizes performance and resource usage on NVIDIA hardware.
- Enables enterprises to maintain control and security of their AI deployments.
In this post, we show you how to deploy NVIDIA NIM on Amazon Elastic Kubernetes Service (Amazon EKS), demonstrating how you can manage and scale LLMs such as Meta’s Llama-3-8B on Amazon EKS. We cover everything from prerequisites and installation to load testing, performance analysis, and observability. Furthermore, we emphasize the benefits of using Amazon EKS combined with Karpenter for dynamic scaling and efficient management of these workloads.
Solution overview
This solution deploys the NVIDIA NIM container with the Llama-3-8B model across two g5.2xlarge Amazon Elastic Compute Cloud (Amazon EC2) instances for high availability (HA). Each instance hosts one replica of the NIM container because each g5.2xlarge instance has a single GPU. These nodes are provisioned by Karpenter when the Llama-3-8B model is deployed through the NIM Helm chart. This setup makes sure that resources are used efficiently, scaling up or down based on the demand.
The Horizontal Pod Autoscaler (HPA) can further scale these replicas based on throughput or other metrics, with data provided by Prometheus. Grafana is used for monitoring and visualizing these metrics. To access the LLM model endpoints, the solution uses a Kubernetes service, a NGINX ingress controller, and a Network Load Balancer (NLB). Users can send their inference requests to the NLB endpoint, while the NIM pods pull container images from the NVIDIA NGC Container registry and uses Amazon Elastic File System (Amazon EFS) for shared storage across the nodes.
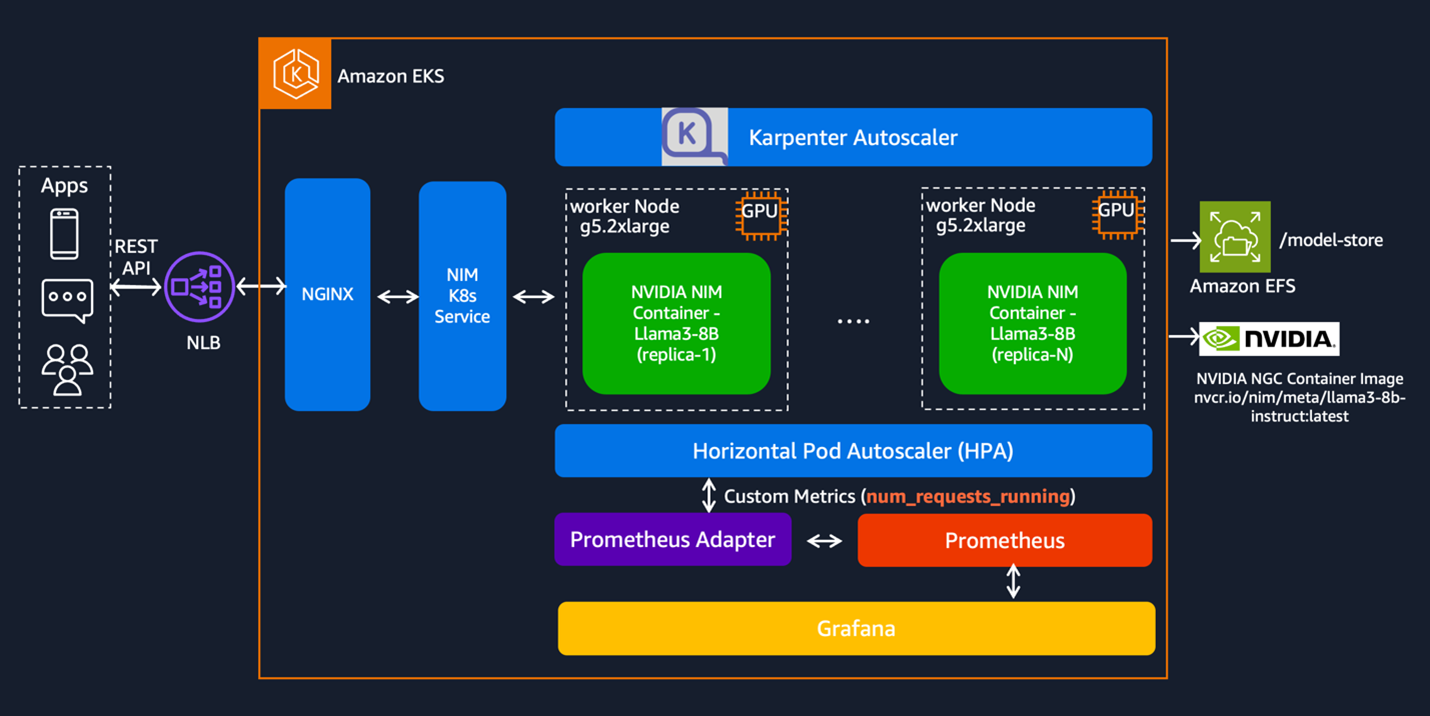
Figure 1. Architecture of NVIDIA NIM LLM on Amazon EKS
Deploying Llama-3-8B model with NIM
To streamline the deployment and management of NVIDIA NIM with the Llama-3-8B model, you use Data on EKS Blueprints with Terraform. This infrastructure as code (IaC) approach makes sure of a consistent, reproducible deployment process, which lays a strong foundation for scalable and maintainable model serving on Amazon EKS.
Prerequisites
Before we begin, make sure you have the following:
- AWS Command Line Interface (AWS CLI)
- curl
- Python3 and pip
- kubectl
- Terraform
- NVIDIA NGC account and API key (check this documentation for detailed instructions)
Setup
1. Configure the NGC API Key
Retrieve your NGC API key from NVIDIA and set it as an environment variable:
export TF_VAR_ngc_api_key=<replace-with-your-NGC-API-KEY>2. Installation
Make sure that you update the region as your desired deployment AWS Region in the variables.tf file before deploying the blueprint. Furthermore, confirm that your local AWS Region setting matches the specified AWS Region to prevent discrepancies. For example, set your export AWS_DEFAULT_REGION="<REGION>” to the desired Region.
Then, clone the repository and run the installation script:
git clone https://github.com/awslabs/data-on-eks.git
cd data-on-eks/ai-ml/nvidia-triton-server
export TF_VAR_enable_nvidia_nim=true
export TF_VAR_enable_nvidia_triton_server=false
./install.shThis installation process takes approximately 20 minutes to complete. If the installation doesn’t complete successfully for any reason, then you can try re-running the install.sh script to reapply the Terraform templates.
3. Verify the installation
When the installation finishes, you may find the configure_kubectl command from the Terraform output. Enter the following command to create or update the kubeconfig file for your cluster. Replace region-code with the Region that your cluster is in.
aws eks --region <region-code> update-kubeconfig --name nvidia-triton-serverEnter the following command to check that the nim-llm pods status is running:
kubectl get all -n nimYou should observe output similar to the following:
The llama3-8b-instruct model is deployed with a StatefulSet in NIM namespace. As it is running, Karpenter provisioned a GPU instance. To check the Karpenter provisioned EC2 instances, enter the following command:
kubectl get node -l type=karpenter -L node.kubernetes.io/instance-typeYou should observe output similar to the following:
Testing NIM with example prompts
For demonstration purposes, we’re using port-forwarding with the Kubernetes service instead of exposing the load balancer endpoint. This approach allows you to access the service locally without making the NLB publicly accessible.
kubectl port-forward -n nim service/nim-llm-llama3-8b-instruct 8000Then, open another terminal and you can invoke the deployed model with an HTTP request with the curl command
curl -X 'POST' \
"http://localhost:8000/v1/completions" \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{
"model": "meta/llama3-8b-instruct",
"prompt": "Once upon a time",
"max_tokens": 64
}'You should observe output similar to the following.
In this case, it means our deployed Llama3 model is up and running, and it can serve the request.
Autoscaling with Karpenter
Now that you’ve verified the deployed model is functioning correctly, it’s time to test its scaling capability. First, we set up an environment for the testing:
cd gen-ai/inference/nvidia-nim/nim-client
python3 -m venv .venv
source .venv/bin/activate
pip install openaiWe have prepared a file named prompts.txt containing 20 prompts. You can use the following command to run these prompts and verify the generated outputs: You should observe an output similar to the following:
python3 client.py --input-prompts prompts.txt --results-file results.txtYou can check the generated responses in results.txt, which contains output similar to the following:
You might still observe one pod, which is because the current pod can still handle the incoming load. To further increase the load, you may introduce more iterations to the script by adding the --iterations flag with the number of iterations you want to run. For example, to run five iterations, you can run the following:
python3 client.py \
--input-prompts prompts.txt \
--results-file results.txt \
--iterations 5You can also repeat this multiple times. At the same time, you may use the following command to find that there are new pods, and when it’s started it takes some time to be ready.
kubectl get po,hpa -n nimLater you might get the similar output as the following
There is an HPA resource named nim-llm-llama3-8b-instruct, which is deployed alongside the nim-llm Helm chart. The autoscaling is driven by the num_requests_running metric, which is exposed by NIM. We have preconfigured Prometheus Adapter to enable HPA to use this custom metric, which facilitates the autoscaling of NIM pods based on real-time demand.
At the instance level, Karpenter automatically helps you launch instances if pods are unscheduable, and it matches the NodePool definition. GPU instances (g5) launched for NIM pods because we have configured the NodePool as follows:
Karpenter provides the flexibility for you to define a range of instance specifications rather than being limited to fixed instance types. When both spot and on-demand instances are configured as options, Karpenter prioritizes the use of Spot Instances using the Price Capacity Optimized allocation strategy. This strategy requests Spot Instances from the pools that we believe have the lowest chance of interruption in the near-term. Then, the fleet requests Spot Instances from the lowest priced pools.
Observability
To monitor the deployment, we’ve implemented the Prometheus stack, which includes both the Prometheus server and Grafana for monitoring capabilities.
Start by verifying the services deployed by the Kube Prometheus stack with the following command:
kubectl get svc -n kube-prometheus-stackWith this command to list the services, you should observe an output similar to the following:
The NVIDIA NIM LLM service exposes metrics through the /metrics endpoint from the nim-llm service at port 8000. Verify it by running the following:
kubectl get svc -n nim
kubectl port-forward -n nim svc/nim-llm-llama3-8b-instruct 8000Open another terminal, and enter the following:
curl localhost:8000/metricsYou should observe numerous metrics (such as num_requests_running, time_to_first_token_seconds) in the Prometheus format exposed by the NIM service.
Grafana dashboard
We’ve set up a pre-configured Grafana dashboard that displays several key metrics:
- Time to First Token (TTFT): The latency between the initial inference request to the model and the return of the first token.
- Inter-Token Latency (ITL): The latency between each token after the first.
- Total Throughput: The total number of tokens generated per second by the NIM.
You can find more metrics descriptions in this NVIDIA document.
To view the Grafana dashboard, refer to our guide on the Data on EKS website.
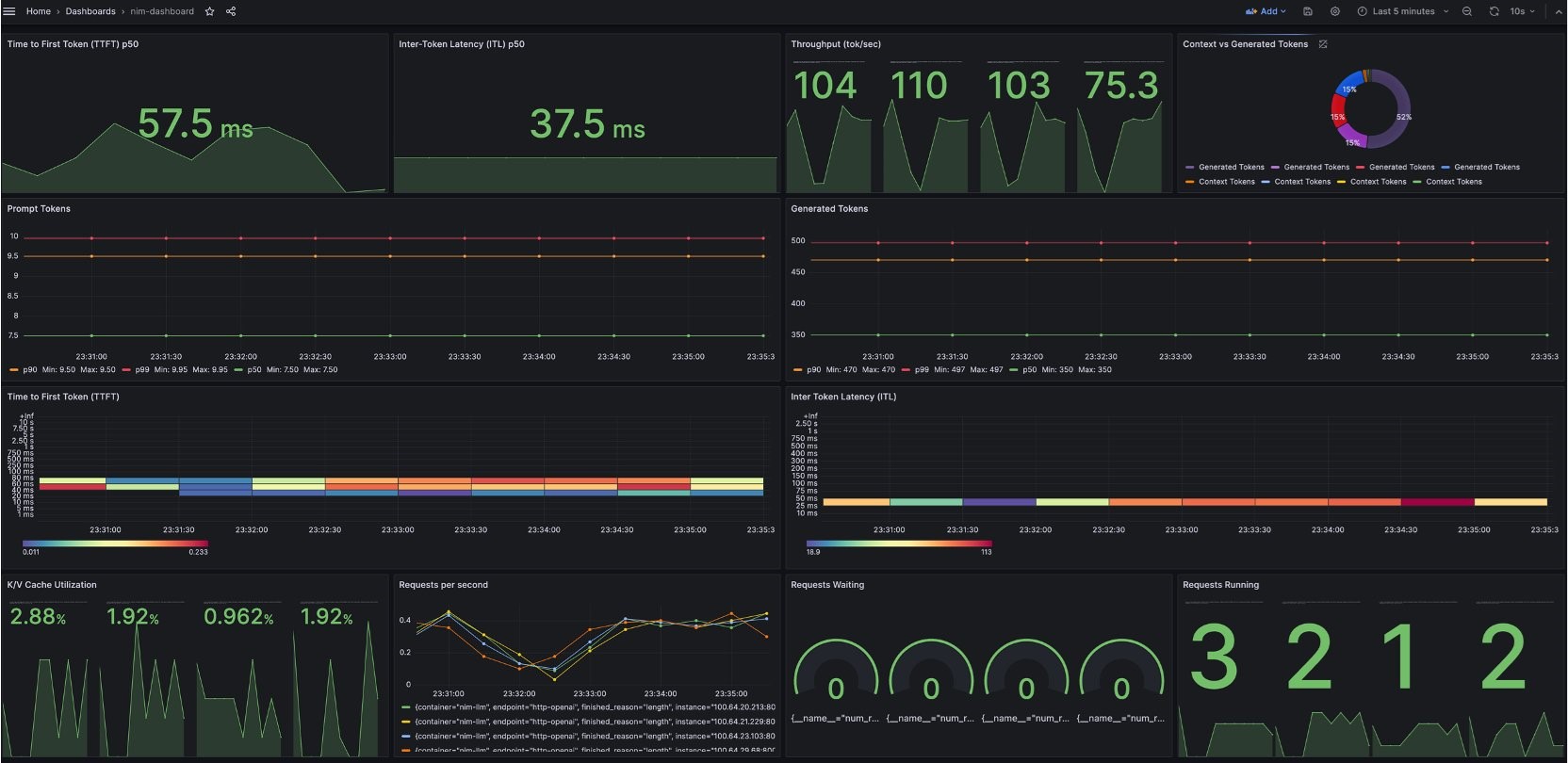
Figure 2. Grafana dashboard example provided by NVIDIA
Performance testing with the NVIDIA GenAI-Perf tool
GenAI-Perf is a command-line tool designed to measure the throughput and latency of generative AI models because they are served through an inference server. It serves as a standard benchmarking tool, which allows you to compare the performance of different models deployed with inference servers.
To streamline the testing process, in particular because the tool needs a GPU, we’ve provided a pre-configured manifest file, genaiperf-deploy.yaml, which allows you to deploy and run GenAI-Perf within your environment. This setup enables you to quickly assess the performance of your AI models and make sure that they meet your latency and throughput requirements.
cd gen-ai/inference/nvidia-nim
kubectl apply -f genaiperf-deploy.yamlWhen the pod is ready with the running status 1/1, first enter into the pod with the following command:
export POD_NAME=$(kubectl get po -l app=tritonserver -ojsonpath='{.items[0].metadata.name}')
kubectl exec -it $POD_NAME -- bash
Then enter the following command to test the deployed NIM Llama3 model:
genai-perf \
-m meta/llama3-8b-instruct \
--service-kind openai \
--endpoint v1/completions \
--endpoint-type completions \
--num-prompts 100 \
--random-seed 123 \
--synthetic-input-tokens-mean 200 \
--synthetic-input-tokens-stddev 0 \
--output-tokens-mean 100 \
--output-tokens-stddev 0 \
--tokenizer hf-internal-testing/llama-tokenizer \
--concurrency 10 \
--measurement-interval 4000 \
--profile-export-file my_profile_export.json \
--url nim-llm-llama3-8b-instruct.nim:8000You should observe similar output to the following:
You should view the metrics collected by GenAI-Perf, such as request latency, output token throughput, and request throughput. For detailed information on the command line options available with GenAI-Perf, refer to the official documentation.
Conclusion
This post outlined the deployment of the NVIDIA NIM solution with the Llama-3-8B model on Amazon EKS, using Karpenter and AWS services such as Amazon EFS, and Elastic Load Balancing (ELB) to create a scalable and cost-effective infrastructure. Karpenter’s dynamic scaling of worker nodes made sure of efficient resource allocation based on demand. We also benchmarked performance metrics using NVIDIA’s GenAI-Perf tool, showcasing the system’s capabilities.
To streamline the deployment process, Data on EKS provides ready-to-deploy IaC templates, which allow organizations to set up their infrastructure in a few hours. These templates can be customized to fit your specific IaC needs.
To get started scaling and running your data and machine learning (ML) workloads on Amazon EKS, checkout the Data on EKS project on GitHub.
Thank you to all the reviewers who provided valuable feedback and guidance in shaping this blog. Your efforts were instrumental in getting it published. Special thanks to Robert Northard, Bonnie Ng and Apoorva Kulkarni for their time and expertise in the review process. Your contributions are greatly appreciated!