AWS Database Blog
Category: DSQL

Migrate relational-style data from NoSQL to Amazon Aurora DSQL
In this post, we demonstrate how to efficiently migrate relational-style data from NoSQL to Aurora DSQL, using Kiro CLI as our generative AI tool to optimize schema design and streamline the migration process.

Auto Analyze in Aurora DSQL: Managed optimizer statistics in a multi-Region database
In this post, we give insights into Aurora DSQL Auto Analyze, a probabilistic and de-facto stateless method to automatically compute DSQL optimizer statistics. Users who are familiar with PostgreSQL will appreciate the similarity to autovacuum analyze.
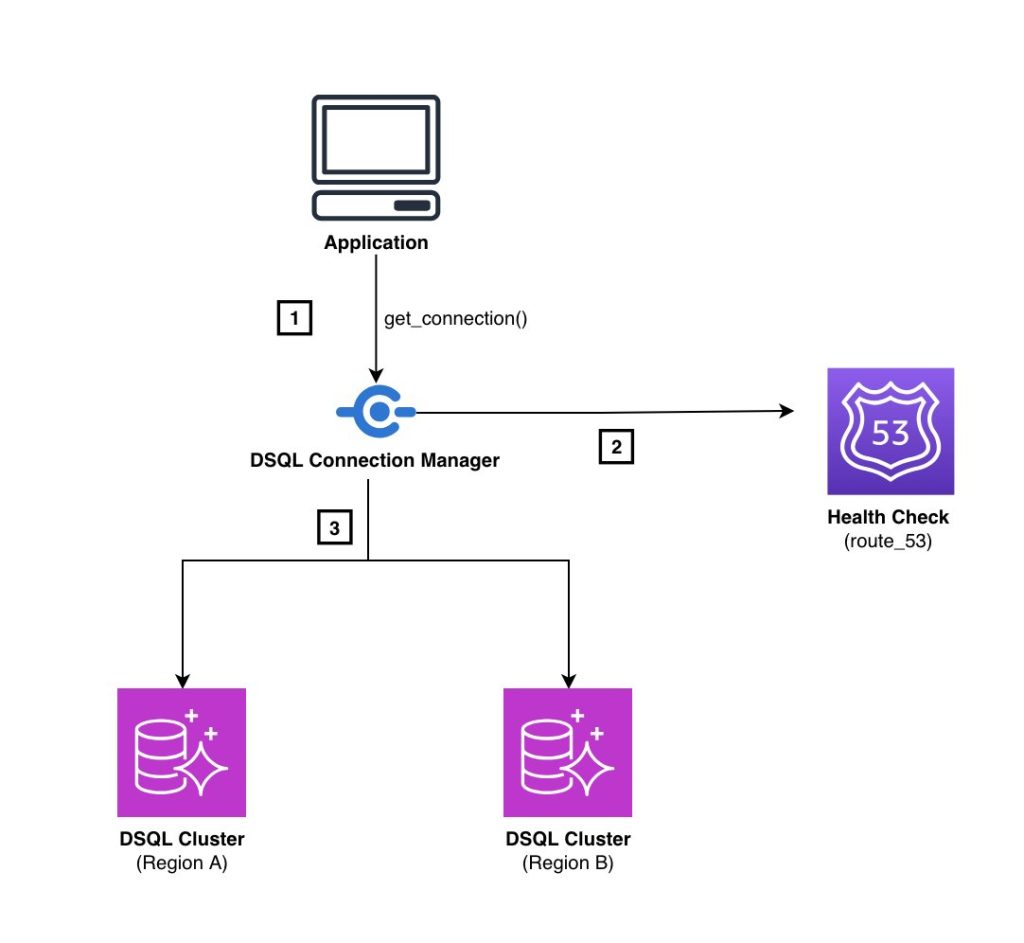
Implement multi-Region endpoint routing for Amazon Aurora DSQL
Applications using Aurora DSQL multi-Region clusters should implement a DNS-based routing solution (such as Amazon Route 53) to automatically redirect traffic between AWS Regions. In this post, we show you automated solution for redirecting database traffic to alternate regional endpoints without requiring manual configuration changes, particularly in mixed data store environments.

Everything you don’t need to know about Amazon Aurora DSQL: Part 5 – How the service uses clocks
In this post, I explore how Amazon Aurora DSQL uses Amazon Time Sync Service to build a hybrid logical clock solution.

Everything you don’t need to know about Amazon Aurora DSQL: Part 4 – DSQL components
Amazon Aurora DSQL employs an active-active distributed database design, wherein all database resources are peers and serve both write and read traffic within a Region and across Regions. This design facilitates synchronous data replication and automated zero data loss failover for single and multi-Region Aurora DSQL clusters. In this post, I discuss the individual components and the responsibilities of a multi-Region distributed database to provide an ACID-compliant, strongly consistent relational database.

Everything you don’t need to know about Amazon Aurora DSQL: Part 3 – Transaction processing
In this third post of the series, I examine the end-to-end processing of the two transaction types in Aurora DSQL: read-only and read-write. Amazon Aurora DSQL doesn’t have write-only transactions, since it’s imperative to verify the table schema or ensure the uniqueness of primary keys on each change – which results them being read-write transactions as well.

Everything you don’t need to know about Amazon Aurora DSQL: Part 2 – Shallow view
In this second post, I examine Aurora DSQL’s architecture and explain how its design decisions impact functionality—such as optimistic locking and PostgreSQL feature support—so you can assess compatibility with your applications. I provide a comprehensive overview of the underlying architecture, which is fully abstracted from the user.

Everything you don’t need to know about Amazon Aurora DSQL: Part 1 – Setting the scene
In this post, I dive deep into fundamental concepts that are important to comprehend the benefits of Aurora DSQL, its feature set, and its underlying components.

Vibe code with AWS databases using Vercel v0
In this post, we explore how you can use Vercel’s v0 generative UI to build applications with a modern UI for AWS purpose-built databases such as Amazon Aurora, Amazon DynamoDB, Amazon Neptune, and Amazon ElastiCache.

Securing Amazon Aurora DSQL: Access control best practices
You can access an Amazon Aurora DSQL cluster by using a public endpoint and AWS PrivateLink endpoints. In this post, we demonstrate how to control access to your Aurora DSQL cluster by using public endpoints and private VPC endpoints through PrivateLink, both from inside and outside AWS.