AWS Database Blog
Category: Amazon DynamoDB
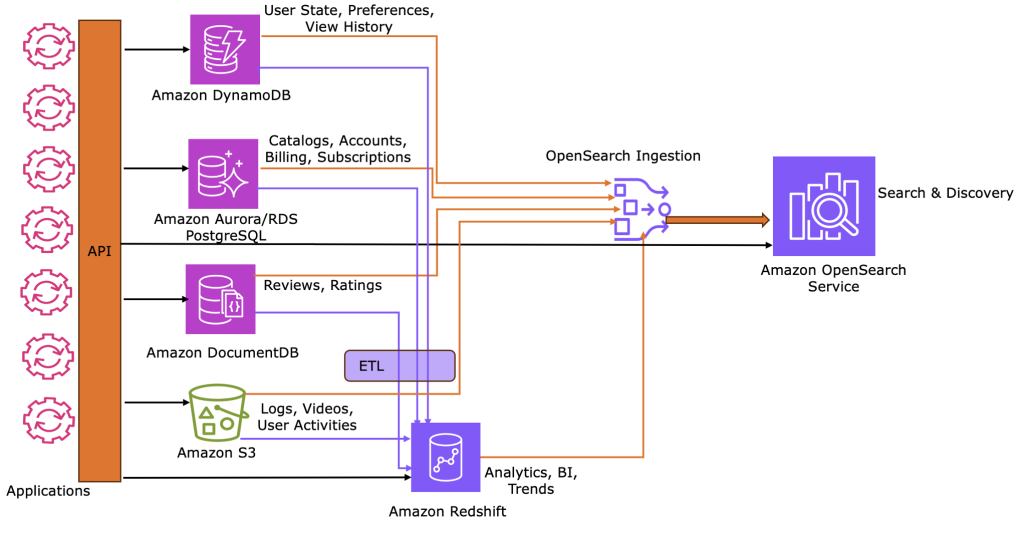
How to build unified JSON search solutions in AWS
Using a movie streaming reference architecture, this post shows how to implement and sync operational, analytical, and search JSON workloads across AWS services. This pattern provides a scalable blueprint for any use case requiring multi-modal JSON data capabilities.

Enabling nested transactions in Amazon DynamoDB using C#
In this post, I introduce a framework for managing atomicity, consistency, isolation, and durability (ACID) compliant transactions in Amazon DynamoDB using C#, featuring support for nested transactions. This capability allows you to implement sophisticated logic with finer control over data consistency and error handling within your .NET applications. With this nested transaction framework, you can isolate issues, allow for partial rollbacks, and build maintainable, modular workflows on top of the built-in transactional capabilities of DynamoDB.
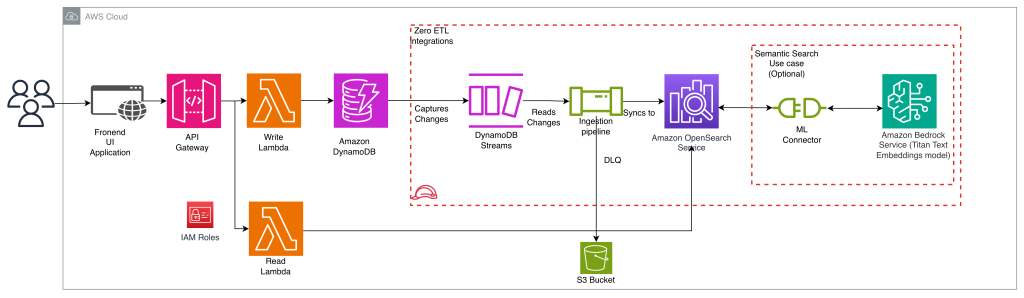
Implementing search on Amazon DynamoDB data using zero-ETL integration with Amazon OpenSearch service
In this post, we show you how to implement search on Amazon DynamoDB data using the zero-ETL integration with Amazon OpenSearch Service. You will learn how to add full-text search, fuzzy matching, and complex search queries to your application without building and maintaining data pipelines.
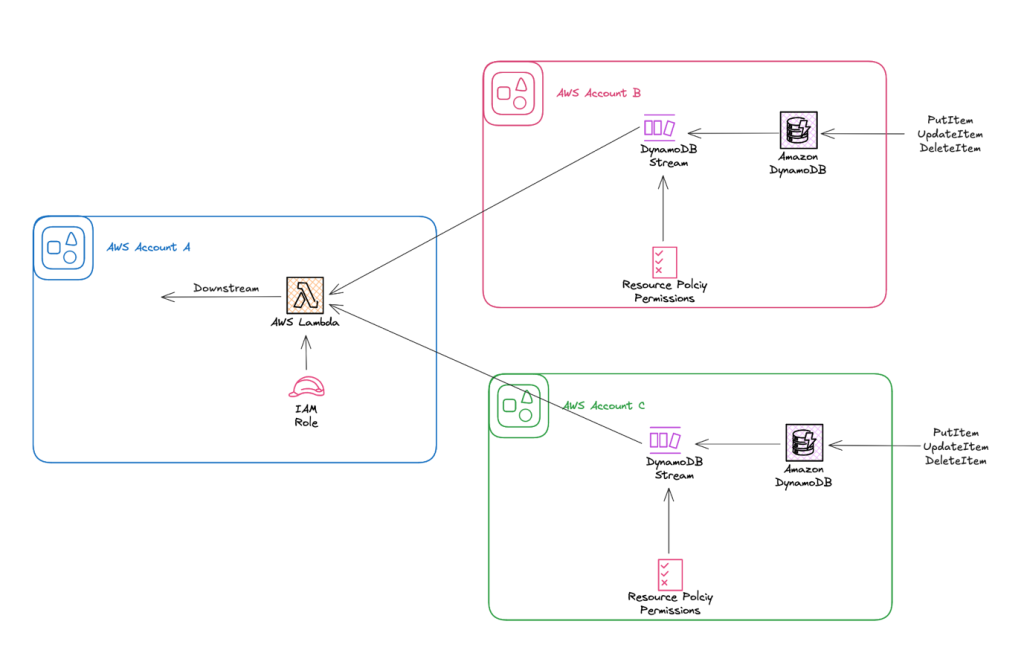
Simplify cross-account stream processing with AWS Lambda and Amazon DynamoDB
In this post, we explore how to use resource-based policies with DynamoDB Streams to enable cross-account Lambda consumption. We focus on a common pattern where application workloads live in isolated accounts, and stream processing happens in a centralized or analytics account.

New in Terraform: Manage global secondary index drift in Amazon DynamoDB
The new aws_dynamodb_global_secondary_index resource treats each GSI as an independent resource with its own lifecycle management. You can use this feature to make capacity adjustments for GSI and tables outside of Terraform. In this post, I demonstrate how to use Terraform’s new aws_dynamodb_global_secondary_index resource to manage GSI drift selectively. I walk you through the limitations of current approaches and guide you through implementing the solution.
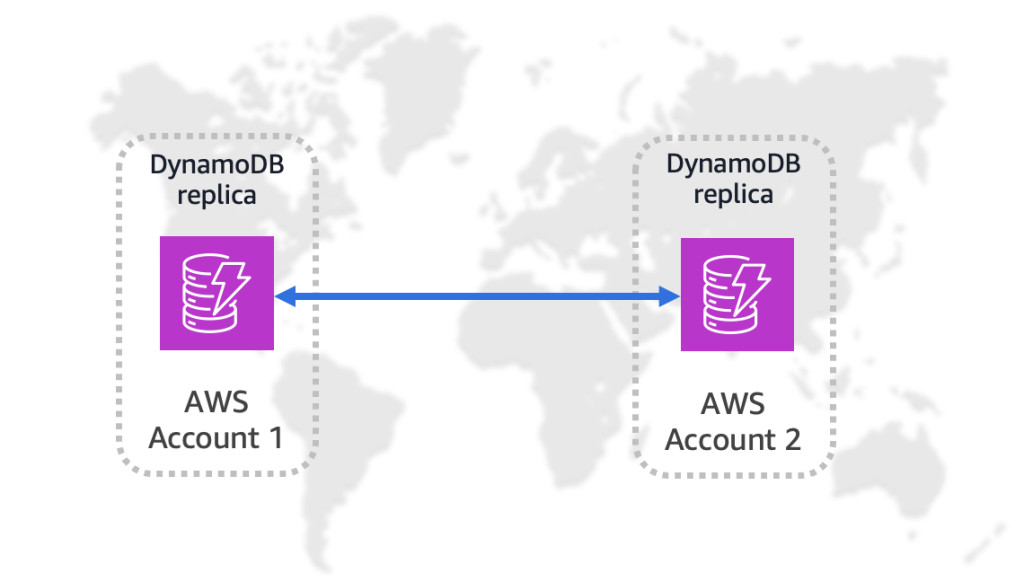
Amazon DynamoDB global tables now support replication across AWS accounts
Today, we’re announcing multi-account global tables for Amazon DynamoDB, which let you replicate DynamoDB table data across multiple AWS accounts and AWS Regions. This feature adds account-level isolation to global tables, so you can replicate DynamoDB table data across multiple AWS accounts and Regions for stronger isolation and resiliency. In this post, we show you how to create and configure a multi-account global table, and introduce use cases highlighting the value of using this feature.

Optimize LLM response costs and latency with effective caching
In this post, we talk about the benefits of caching in generative AI applications. We also elaborated on a few implementation strategies that can help you create and maintain an effective cache for your application.
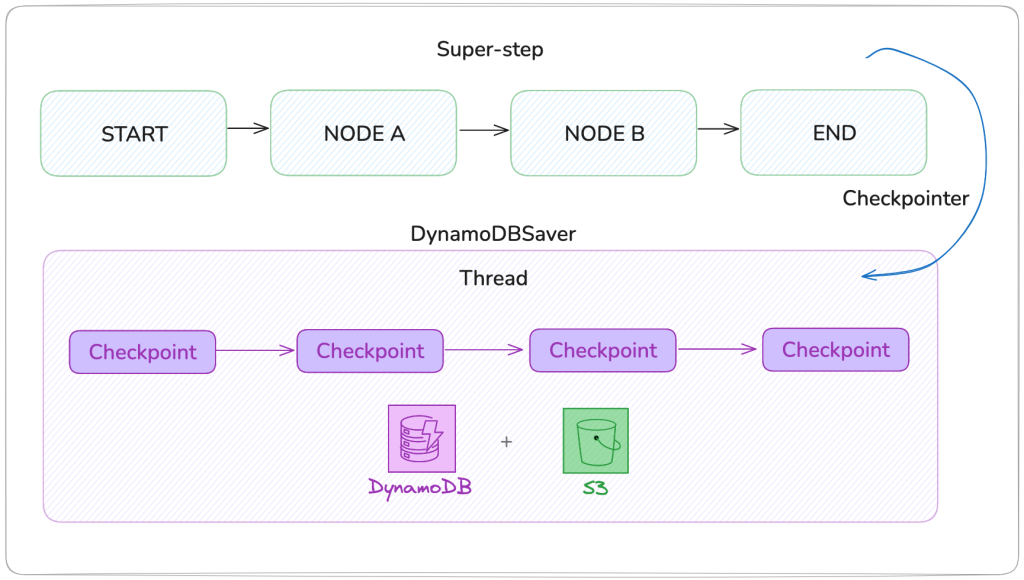
Build durable AI agents with LangGraph and Amazon DynamoDB
In this post we show you how to build production-ready AI agents with durable state management using Amazon DynamoDB and LangGraph with the new DynamoDBSaver connector, a LangGraph checkpoint library maintained by AWS for Amazon DynamoDB.

Multi-key support for Global Secondary Index in Amazon DynamoDB
Amazon DynamoDB has announced support for up to 8 attributes in composite keys for Global Secondary Indexes (GSIs). Now, you can specify up to four partition keys and four sort keys to identify items as part of a GSI, allowing you to query data at scale across multiple dimensions. In this post we show you how to design similar data models more efficiently using Global Secondary Indexes with the additional attribute support in composite keys and provide examples of DynamoDB data models with reduced complexity.

Accelerating data modeling accuracy with the Amazon DynamoDB Data Model Validation Tool
Today, we’re introducing the Amazon DynamoDB Data Model Validation Tool, a new component of the MCP server that closes the loop between generation, evaluation, and execution. The validation tool automatically tests generated data models against Amazon DynamoDB local, refining them iteratively until every access pattern behaves as intended.