AWS Database Blog
Everything you don’t need to know about Amazon Aurora DSQL: Part 3 – Transaction processing
Amazon Aurora DSQL employs an active-active distributed database design, wherein all database resources are peers and serve both write and read traffic within a Region and across Regions. This design facilitates synchronous data replication and automated zero data loss failover for single and multi-Region Aurora DSQL clusters.
In this third post of the series, I examine the end-to-end processing of the two transaction types in Aurora DSQL: read-only and read-write. Amazon Aurora DSQL doesn’t have write-only transactions, since it’s imperative to verify the table schema or ensure the uniqueness of primary keys on each change – which results them being read-write transactions as well.
Read-only transactions
The following is the system architecture diagram, illustrating data processing workflow for read-only transactions.
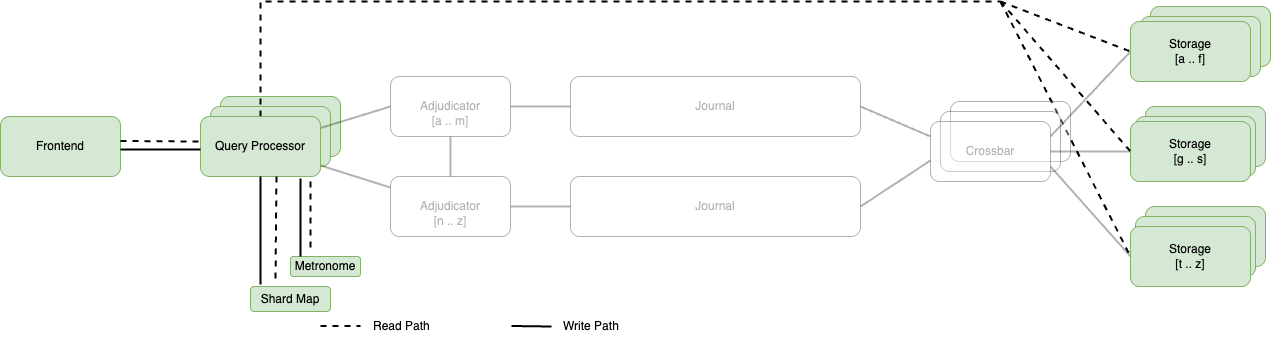
System architecture diagram illustrating data processing workflow for read only transactions
To better understand the different phases of the transaction flow, I am breaking this up into multiple steps beginning with the Transaction Initiation.
- Transaction Initiation: The transaction process begins when a client issues either a `START TRANSACTION` or `BEGIN` command. The frontend then allocates a dedicated Query Processor (QP). This QP is a specialized micro Virtual Machine (VM) that parses, plans, and executes queries for the transaction. Each transaction is assigned its own individual QP. The isolation is crucial as it ensures that each transaction operates independently without any interference from other concurrent transactions. Prior to executing a statement, the QP reads the current time, synchronized using the Amazon Time Sync Service and assigns the transaction start time τ-start. This timestamp serves as the fundamental reference point for the entire transaction and plays a crucial role in maintaining consistency across Aurora’s distributed architecture.
- Query Execution: Once initialized, the QP begins its primary function by performing a comprehensive parsing of the SQL statement. During this phase, it validates both the syntax and semantic correctness of the query and develops the execution plan. To read the data from storage, the QP consults the shard map to determine the precise location of required data across storage nodes.
- Data Retrieval from Storage Nodes: When the storage nodes receive requests, each node performs critical pre-retrieval checks. These checks ensure that all transactions with timestamps before τ-start have been fully processed. If necessary, nodes will implement a wait mechanism to maintain consistency guarantees. The storage nodes employ snapshot isolation based on the τ-start timestamp. This mechanism guarantees that all nodes provide a consistent view of the data as it existed at the transaction’s start time. This approach effectively prevents anomalies that might otherwise arise from concurrent transactions. The storage node then returns the data requested.After retrieving the data, the QP aggregates the result from multiple nodes. Aurora DSQL’s architecture supports interactive transactions, allowing multiple queries to be executed within the same transaction context, which means that query process can repeat multiple times within a single transaction. The system maintains consistent transaction state throughout the entire session, preserving all isolation guarantees across multiple operations.
- Transaction Commit: For read-only transactions, Aurora DSQL implements a unique commit mechanism where the commit time (τ-commit) is set to the transaction start time (τ-start). This creates what is effectively a zero-duration transaction from a logical perspective, guaranteeing that read-only transactions always see a consistent snapshot and cannot fail due to conflicts.
Read-write transactions
The following is the system architecture diagram, illustrating data processing workflow within Aurora DSQL.
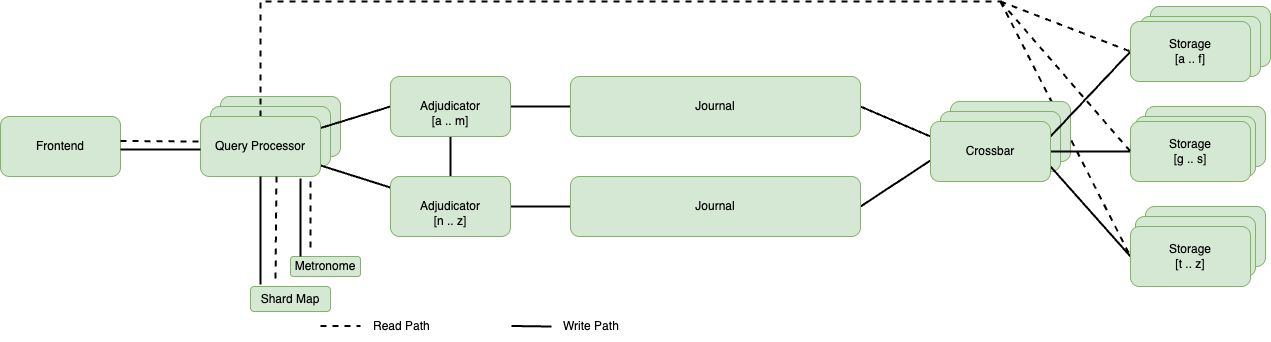
System architecture diagram illustrating data processing workflow within Amazon Aurora DSQL
- Transaction Initiation: The initial phase of a read-write transaction mirrors that of read-only transactions.
- Query Execution and Write Handling: During the execution phase, the QP processes SQL statements in a manner like read-only transactions. However, read-write transactions introduce additional complexity in handling modifications. When write operations occur, the QP stores the results of these database changes locally, effectively spooling the writes throughout the transaction’s duration. In the event of a rollback or any disconnect, the QP discards the spooled writes.Internally the execution of transactions in Amazon Aurora DSQL is optimized based on the concurrency mechanism. The implementation of MVCC used allows for Early Aborts (more details on the concept can be found in the chapter 3.3.1 Handling write-write conflicts in the paper Repairing Conflicts among MVCC Transactions) for read-write transactions that would else fail at commit time. When the QP reads from storage, storage indicates it if is seeing the newest version of the data. If the transaction attempts to update a row that already has a newer version, the transaction is immediately aborted.
- Commit Processing: At commit time the QP consults the shard map to determine the adjudicators that own the keys they’ve modified. The QP construct the write set, including the rows it wrote to (which might include newly created rows), package them with the post-images and submit them to the adjudicator. Finally, it submits this complete write set to the designated adjudicator(s).
- Adjudication Phase: Each adjudicator verifies whether any writes have occurred to the modified rows since the transaction’s start time (τ-start). If a conflict is detected by any adjudicator, the commit is rejected. If no conflicts are detected, the adjudicator places locks on the affected rows to ensure exclusive access during the commit phase. These locks prevent other transactions from modifying the same data until the current transaction completes, thereby protecting the integrity of the updates being committed. Additionally, the adjudicator selects a commit timestamp (τ-commit) that exceeds τ-start and is greater than any previously issued τ-commit value. The post-images and timestamps are then written to the journal. After the journal acknowledges these changes, the QP acknowledges them to the client. From the client’s perspective the transaction is over. From DSQL’s perspective we still need to write its contents to the storage nodes
- Storage Update Phase: The crossbar component receives the transaction’s writes from the journal and forwards the relevant rows to the appropriate storage nodes based on their subscribed portions of the key space. These storage nodes then persist the changes.
How the commit phase works
The key space within the database is sharded and distributed among the adjudicators, whose number scales proportionally to the size of the key space. Consequently, each key is owned by exactly one adjudicator globally. During a read-write transaction commit, each adjudicator independently determines whether its own key space can commit, then coordinates with other adjudicators involved in the same transaction. Writing a commit to the journal makes the commit successful and durably stored. Conversely, if a commit fails, all involved adjudicators must abort.
For the commit algorithm, the service uses a hybrid approach of a two-phase commit and a warp-style commit to minimize unnecessary round-trip times. This is illustrated in the following figure:
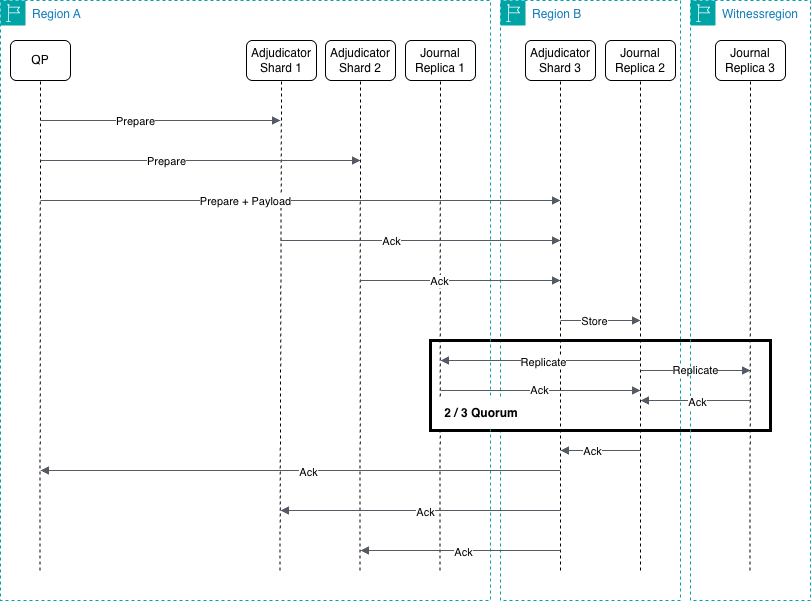
When you commit a transaction in Aurora DSQL, here’s what happens behind the scenes:
- The QP takes charge of the transaction and determines which adjudicators need to be involved based on the data being modified.
- It then sends a PREPARE message to all but one of the involved adjudicators in parallel. These adjudicators check if they can commit the transaction and send their responses to a designated final adjudicator
- The final adjudicator acts as the decision maker: It receives both the transaction data from the QP and the responses from other adjudicators. If no conflicts were detected by all adjudicators involved, it commits the transaction. If any adjudicators report a problem, it aborts the transaction and notifies everyone.
This process is designed to be efficient – data is sent once, and responses flow back through the system in a way that handles both the commitment decision and data replication across Regions in a single pass. This coordinated approach ensures that distributed transactions remain consistent across the entire system while minimizing unnecessary back-and-forth communication.
How Amazon Aurora DSQL handles SELECT FOR UPDATE
SELECT FOR UPDATE is a special kind of SQL statement in Amazon Aurora DSQL. For read-write transactions, you can utilize SELECT FOR UPDATE for managing write skew as Aurora DSQL doesn’t perform concurrency checks on read records. For more details, examples and how to handle these queries, check out Concurrency control in Amazon Aurora DSQL.
Conclusion
In this post, I explored the intricacies of transaction management within Amazon Aurora DSQL. I investigated the internal mechanisms of commit handling. In the subsequent post, I will provide a comprehensive analysis of the components that comprise Aurora DSQL: the QP, adjudicator, journal, crossbar, and storage.