AWS Database Blog
How CyberZ performs read-light operations to display followees’ activities in the timeline using Amazon DynamoDB
About CyberZ
CyberZ, Inc. is an advertising agency that was founded in 2009 and specializes in smartphone marketing. At CyberZ, we have developed a wide range of marketing businesses, including advertising on the smartphone and measuring its effectiveness, creation of ads for public transport, and creation of web commercials. We also have branches outside Japan—in San Francisco, South Korea, and Taiwan—to help our domestic clients expand their businesses overseas, as well as to help our overseas clients expand their businesses in Japan. As a media business, we operate OPENREC.tv, a video streaming platform. As an e-sports business, we operate RAGE, one of the largest e-sports events in Japan. CyberZ’s wholly owned subsidiaries include eStream, Inc., which runs an online entertainment business and a production business, and CyberE, Inc., which specializes in e-sports marketing.

OPENREC.tv is a live streaming platform service focused on game streaming. It boasts high-definition video and low latency. Its low-latency streaming platform using Wowza Streaming Engine and Low Latency HLS, as well as its real-time chat feature using Redis and Socket.io, are built on AWS. We use Amazon Aurora for a relational database, and Amazon DynamoDB and Amazon ElastiCache (Redis) for NoSQL.
This post describes how OPENREC.tv redesigned its timeline feature, which displays a list of streaming sessions by streamers the user follows, by using DynamoDB instead of a relational database.
Why OPENREC.tv adopted DynamoDB
Social media in general allows you to follow other users and display their activities in your own timeline (feed). Similarly, OPENREC.tv enables you to track live streaming sessions of your followees in chronological order.
To implement this feature, we previously used a read-heavy/write-light method based on relational database, but with the growth of our service, we started to see heavy users who follow many streamers, as well as streamers who follow back all their followers, resulting in degraded response time in our API that gets the timeline data. It eventually took as long as 3–7 seconds to load a page when the user followed several hundreds of people. Some users even followed over tens of thousands of people, which caused quite a high load.
We needed to move away from the read-heavy/write-light method to the read-light/write-heavy method to reduce the load and improve the user experience as relational database and web server were heavily loaded despite being key services.
About the read-heavy/write-light method
The mechanism of the read-heavy/write-light method is quite simple: it explores data based on the list of people you follow.
The SQL query looks like the following code:
The advantage of using this method is that it maintains a single table and its implementation cost is low. In most cases, this SQL query runs fast, but starts to slow down as the number of followees increases. To avoid the slowdown, you need to limit the number of maximum followees allowed per user and prevent a high load caused by lookup queries. The following diagram illustrates this method.

About the read-light/write-heavy method
The read-heavy/write-light method is slow querying data for the timeline if the user follows many people. A solution to this problem is to add a record for each user’s timeline. In other words, when a streamer starts a session, they insert a new record to each of their followers, and each follower gets the record set sorted chronologically by user ID. The following diagram illustrates this method.

The advantage of using this method is that it can reduce the load when users get data for their timelines. This method is preferred if users follow many people or make frequent requests to get data for their timelines.
On the other hand, instead of reducing the load for querying data, this method writes the same number records as the number of followers when a streamer updates data (starts a streaming session). As of June 2020, the most-followed streamer has about 220,000 followers, meaning that the streamer writes up to 220,000 records when they start a single streaming session.
This approach required a high throughput data store that could instantaneously respond to imbalanced write requests. OPENREC.tv decided to use DynamoDB—which offers high throughput and a flexible data structure—as the data store for the timeline feature.
Migrating to DynamoDB
We had the following requirements for our timeline:
- When a streamer distributes, a timeline record is generated for each user for each follower. Therefore, writes spike when a popular streamer delivers.
- Ensure enough write/read performance to withstand concurrent access.
- The information displayed in the timeline for each user is different.
- The ability to view them in chronological order.
Key design
A DynamoDB table can have composite primary keys, composed of a partition key and a sort key. You can get items sorted by partition key when you query a table that has composite primary keys. The timeline is displayed in chronological order by using a table that has composite primary keys.
Although DynamoDB is a virtually infinitely scalable NoSQL database service, its scalability is compromised if you make a mistake in designing keys, so you need to design them properly. For more information, see Partitions and Data Distribution.
Partition keys
A partition key, as its name implies, is a key that is passed on to the hash function, which determines the partition (internal shard) of DynamoDB.
If a table doesn’t have composite primary keys, partition keys work alone as primary keys just like other KVSs. If a table has composite primary keys, partition keys work in conjunction with sort keys (described in the next section) to uniquely identify items.
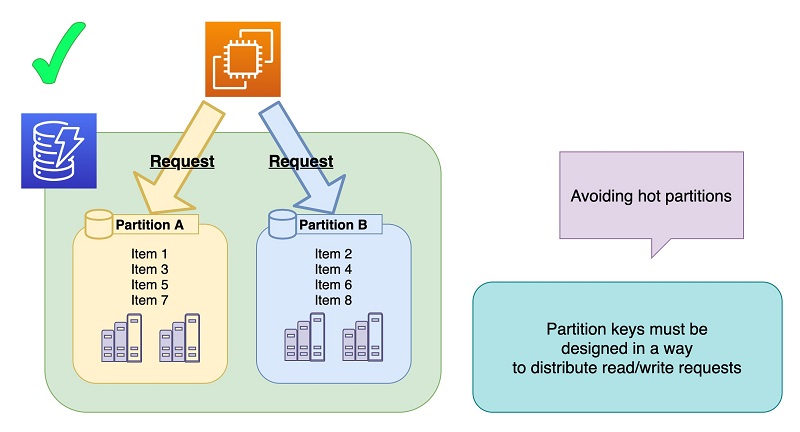
Partition keys may be duplicated in a table that has composite primary keys. Having the same partition key means the items are stored in the same partition, so a single partition could get a traffic spike if the partition key is equal to a parameter, like the user ID of a streamer. Depending on the access characteristics of the table, you need to design keys so that access is distributed across different partitions as the number of users increases. The following diagram illustrates this architecture.

OPENREC.tv decided to use the ID of the referring user (follower) as the partition key. It’s unlikely that a single user’s query request causes a spike, and items are added to followers evenly across different partitions. The following diagram illustrates this architecture.
Sort keys
In a table that has composite primary keys, sort keys are used to sort items that have the same partition key. In DynamoDB, you can query for specific ranges, or query for data sorted in ascending or descending order.
Composite primary keys must be unique and must not be duplicated because items are accessed using the combination of a partition key and a sort key. If you simply use time data as the sort key of the timeline table that needs to be sorted in chronological order, some sort keys could be duplicated, so you need to use different values that are distinct.
The access patterns are as follows:
- Items can be generated for each viewing user ID when writing
- When loading, the timeline information can be read in chronological order by each viewer
- You can get separate information even if they are delivered at the same time
OPENREC.tv decided to use a concatenation of the date and time and the referred movie ID as the sort key. The following screenshot shows a sample of the table metadata.

We use a DynamoDB query to query the data. To query data for the second and subsequent pages, the sort_key value of the item at the bottom of the current page is passed on to another query clause, which extracts items with sort_key values greater (or smaller) than the passed value to enable paging. Strings are compared based on ASCII character code values, so you can perform a range query such as sort_key BETWEEN '20200501' AND '20200508'. See the following code:
Because the timeline table only holds data such as movie IDs and times, we get data from another table in the relational database that stores streaming information using the list of IDs after retrieving items from DynamoDB. We needed to ensure data consistency is maintained as data is stored in both the relational database and DynamoDB. OPENREC.tv ensures data consistency by not deleting the streaming session data from the DynamoDB table even when a session is deleted. Instead, the session is discarded on the application side.
Setting the Time to Live
We can have DynamoDB automatically delete its items by setting Time to Live (TTL) information. You may want to consider setting TTL if users don’t need to refer to old data, because older items tend to be less accessed in the timeline where information is sorted in chronological order. For more information, see Expiring Items By Using DynamoDB Time to Live (TTL).
We decided to use TTL to reduce storage usage costs. The number of items and storage usage vary depending on the number of streaming sessions and followees. As of June 2020, the actual number of items generated in OPENREC.tv was between 1–3 million items per day, which totals to as many as 60 million items per month. Therefore, we set the TTL to 1 month, so that the storage size wouldn’t grow too much.
Setting the capacity mode
DynamoDB supports up to 3,000 RCUs (RRUs) or 1,000 WCUs (WRUs) per partition, and offers two pricing modes for the capacity unit (request unit): provisioned capacity mode and on-demand capacity mode.
Provisioned capacity mode
In provisioned capacity mode, you reserve the capacity you’re going to consume. You need to estimate the capacity based on data such as frequency of access to the table, so that you can optimize costs and performance. Because you can set Auto Scaling based on utilization or time, you can reduce costs by using provisioned capacity mode if the table tends to get more access in proportion to the number of users, or if the table is accessed at specific times. However, keep in mind that a burst of requests could result in throttling. For more information, see Provisioned Mode.
On-demand capacity mode
On-demand capacity mode offers pay-as-you-go pricing where you’re billed only for the capacity you consume. You don’t need to specify the capacity for the table, and it automatically scales up to double the maximum throughput used in the past. For more information, see On-Demand Mode.
The biggest advantage of this mode is that it’s highly resilient to traffic spikes. If you want to increase resilience to traffic spikes in the provisioned capacity mode, all you can do is increase the reserved capacity.
Especially in our case, if we reserved enough capacity in the provisioned mode—taking the fact into account that hundreds of thousands of write requests are generated by some streamers who have many followers—most of the reserved capacity would end up being unconsumed while we are billed quite a lot of money.
In our case, traffic spikes are unlikely to be correlated to times of a day, so we thought that switching to on-demand mode would reduce costs. In addition, it automatically scales up to double the maximum throughput used in the past, so we don’t need to worry about increasing the capacity.
When you create a table in on-demand capacity mode, the default capacity is maximum 12,000 RCUs or 4,000 WCUs, so OPENREC.tv created a table with high capacity (tens of thousands of RCUs/WCUs) in provisioned capacity mode first, and then changed it to on-demand capacity mode for release. We pre-warmed the table so we could handle a spike in write requests by streamers with many followers immediately after the release.
Retry mechanism
A retry mechanism needs to be designed so that it works correctly in case throttling or unexpected errors occur in DynamoDB. For more information, see Error Retries and Exponential Backoff.
OPENREC.tv sends a timeline message (start of a streaming session) to an Amazon Simple Queue Service (Amazon SQS) queue. Then an AWS Lambda function gets the messages and divides them into groups of 25 items each, and sends them to DynamoDB in parallel using BatchWriteItem.
Within Lambda, retries are attempted at the application level when any of the UnprocessedItems or retryable errors are returned. The max number of retries Lambda performs is set in the SQS queue. By design, Amazon SQS can deliver a duplicate SQS message multiple times, so you need to make the Lambda function idempotent. In DynamoDB, PUT requests overwrite existing items, so there’s no problem even if they are performed multiple times.
We also specified that messages that failed a certain number of times are sent to the dead-letter queues (DLQ) to avoid indefinitely retrying failed messages. Messages loaded in the DLQ are output to Amazon CloudWatch Logs, and a CloudWatch alarm notifies Slack. The following diagram illustrates this architecture.

Performance
The response time was shortened from about 1,500 milliseconds to about 100 milliseconds after the update, when the user followed about 300 people.
As to the spike in writes, the write capacity graph in the DynamoDB metrics shows a momentary spike of about 3,500 writes, which occurred when a user with around 210,000 followers started a streaming session. The following screenshot shows some of our performance metrics.

This metric indicates the 1-minute average of WCUs per second, which translates to 210,000 WCUs per minute (= 3,500 WCUs * 60 seconds). Because it took 10,800 milliseconds for the Lambda function to complete writing, the request to write to 210,000 items instantaneously was processed at an average throughput of 21,000 WCUs per second.
The default throughput limit in on-demand capacity mode is 40,000 RCUs or 40,000 WCUs, but you can request a limit increase if more throughput is needed.
Summary
In this post, I talked about how we redesigned the timeline feature—which displays a list of streaming sessions by the streamers the user follows in OPENREC.tv—by using DynamoDB instead of a relational database.
If you need to implement a query feature where each user queries a different number of items in the IN clause, you can prepare data for each user to optimize the query. Also, write requests should be distributed and queued properly as the load tends to be high at the time of writing. When using DynamoDB, partition keys and sort keys need to be properly designed, and on-demand capacity mode may be more appropriate depending on the frequency of access and its characteristics. In particular, for a table where traffic spikes are expected, you will likely reduce both costs and throttling errors without compromising the high throughput, which is one of the characteristics of DynamoDB.
For more information about DynamoDB, see the Amazon DynamoDB Developer Guide and AWS Black Belt Online Seminar 2017 Amazon DynamoDB.
About the Author
Takahiro Fujii (@toro_ponz) / CyberZ, Inc.

Takahiro Fujii is a software engineer working for the SRE team of OPENREC.tv. He is engaged in service development and is mainly working on load testing, capacity planning for Amazon DynamoDB, and operation of Amazon EKS.