AWS Database Blog
Impactful features in PostgreSQL 15
PostgreSQL is one of the most popular open-source relational database systems. The product of more than 30 years of development work, PostgreSQL has proven to be a highly reliable and robust database that can handle a large number of complicated data workloads. AWS offers services that make PostgreSQL database deployments straightforward to set up, manage, and scale for the cloud in a cost-efficient manner. These services are Amazon Relational Database Service (Amazon RDS) for PostgreSQL and Amazon Aurora PostgreSQL-Compatible Edition.
The PostgreSQL developer community released PostgreSQL 15 about a year ago, which has given us time to study the impactful features of the release. PostgreSQL 15 further enhances the performance gains of recent releases, offering significant improvements for managing workloads in local and distributed environments, particularly in sorting operations. Inclusion of the popular MERGE command enhances the developer experience, while additional capabilities for observing the database’s state provide more insights.
In this post, we take a close look at some of the most impactful features of PostgreSQL 15. We explore the MERGE statement, new WAL compression algorithms, enhancements to logical replication and PUBLIC schema permissions, improvements to partition tables, and some general performance improvements.
Prerequisites
To follow along with this post, complete the following prerequisites:
- Create an Aurora PostgreSQL cluster or RDS for PostgreSQL instance if you don’t already have one. For instructions, refer to Create an Amazon Aurora PostgreSQL-Compatible DB cluster or Create a PostgreSQL DB instance, respectively.
- Create an Amazon Elastic Compute Cloud (Amazon EC2) instance to install the PostgreSQL client to access the Aurora PostgreSQL or RDS for PostgreSQL instance. For instructions, refer to Create your EC2 resources and launch your EC2 instance. Or you can set up connectivity between your RDS database and EC2 compute instance in one click.
- Install the PostgreSQL client. On Amazon Linux 2023, you can use the following commands to download the psql command line tool:
MERGE command
MERGE was one of the most highly anticipated features in PostgreSQL 15 because it provides a single command that lets you perform conditional inserts, updates, and deletes. Prior to PostgreSQL 15, you could use the INSERT ... ON CONFLICT statement to run upsert-style queries, but the target row needed to have a unique or exclusion constraint. With MERGE, you now have more options for modifying rows from a single SQL statement, including inserts, updates, and deletes. It simplifies data manipulation and enhances the overall developer experience by reducing complexity and optimizing database interactions. This command is used to merge data from a source table into a target table, allowing you to update or insert data into an existing table based on a match between the source and target tables.
Usage of the MERGE command
The basic syntax for the MERGE command is as follows:
Let’s look at the explanation of the syntax:
- MERGE INTO target_table – Specifies the target table that you want to merge data into.
- USING source_table – Specifies the source table that you want to merge data from.
- ON join_condition – Specifies the join condition that determines which rows in the source table match which rows in the target table.
- WHEN MATCHED THEN UPDATE – Specifies the action to take when a match is found between a row in the source table and a row in the target table. In this case, the specified columns in the target table will be updated with their respective specified values from the source table.
- WHEN NOT MATCHED THEN INSERT – Specifies the action to take when no match is found between a row in the source table and a row in the target table. In this case, a new row will be inserted into the target table with the specified values.
Example usage
Let’s explore an example of a source table calledemployee_updatesand a target table calledemployees. You can connect to your EC2 instance and then to a PostgreSQL database engine running on the instance.
- Create the employees table:
- Insert some initial data into the employees table:
- Create the employee_updates table:
- Insert some updated data into the
employee_updatestable: - Use the
MERGEcommand to update the data in the target table:The
MERGEcommand is used to update and insert data from theemployee_updatestable into the employees table. It uses the following clauses:- ON – Specifies that we want to match rows in the employees table with rows in the
employee_updatestable based on the id column - WHEN MATCHED – Specifies that we want to update the
first_name,last_name, andsalarycolumns in the employees table with the corresponding values from theemployee_updatestable - WHEN NOT MATCHED – Specifies that we want to insert new rows into the employees table for any rows in the
employee_updatestable that don’t have a matching id in the employees table
- ON – Specifies that we want to match rows in the employees table with rows in the
- Finally, verify that the data has been updated and inserted correctly by running a SELECT statement on the employees table:
Improve MERGE performance with work_mem
PostgreSQL employs a temporary work area in memory (which can be set through the work_mem parameter) for various operations, such as storing intermediate results during index creation, sorting, and grouping records for queries. Therefore, the performance of MERGE can be improved by increasing the work_mem. The following is a simple example with a db.r5.large instance:
- Create two sample tables and insert some dummy data:
- Get the backend process ID of the connection and run the
MERGEcommand:In this example, it took 18.3 seconds to process the
MERGEcommand. - Download the recent postgresql log and check for the process ID:
The logs in the preceding code show that running
MERGEcreated 128 temporary files of total 575 MB in size to process theMERGEcommand - You can increase the
work_memat the session level and try theMERGEcommand:As you can see, it took 14.7 seconds, where it took 18.3 seconds without setting
work_mem(a 20% improvement) and no temporary files were created because the operation was done in memory.
Accelerate MERGE queries with Amazon RDS Optimized Reads
Without setting the working memory, PostgreSQL uses the work area on disk instead of memory, which degrades the performance of MERGE. However, configuring the working memory to high values may not necessarily be the optimal solution.
To deal with these kinds of situations, a new deployment option called Optimized Reads is introduced in Amazon RDS, which helps with up to twice the read performance for workloads that heavily rely on a temporary work area. Optimized Reads uses the local storage provided by the NVMe SSDs on the underlying instances used in the Multi-AZ DB clusters. Refer to Introducing Optimized Reads for Amazon RDS for PostgreSQL for more details.
Let’s try the same example with a db.r6gd.large instance type, which offers local NVMe-based SSD block-level storage:
Note: We are running this query with default work_mem (4MB). As, we want to understand the improvement we are going to get with Optimized Reads feature and without changing work_mem defaults.
With the default work_mem setting of 4 MB, the db.r6gd.large instance took 15.7 seconds, compared to 18.3 seconds with a db.r5.large instance (a 15% improvement) and the same amount of temporary files creation (128 files and 575 MB in size).
WAL compression (zstd and lz4)
PostgreSQL 15 includes improvements to Write-Ahead Logging (WAL) compression, with the introduction of the zstd and lz4 compression algorithms. This allows for more efficient logging of transactions, resulting in improved performance, reduced disk space usage, and faster recovery.
The lz4 and zstd WAL compression methods are supported in Amazon RDS for PostgreSQL 15 and the default WAL compression is zstd. Due to the unique distributed storage system of Aurora, Amazon Aurora PostgreSQL version 15 does not support server-side compression with Gzip, LZ4, or Zstandard (zstd) using pg_basebackup, online backups using pg_backup_start() and pg_backup_stop(), and prefetching during WAL recovery.
The zstd algorithm is a high-performance data compression algorithm, similar to gzip or bzip2, but often with better compression ratios and faster compression speeds. It’s designed for applications that require high write throughput. The lz4 algorithm is a high-speed data compression algorithm, designed to provide faster speeds than gzip or bzip2, while still providing good compression ratios. It’s commonly used for applications that require low read latency.
To use WAL compression in PostgreSQL 15, you can set the wal_compression parameter. The supported methods are pglz, lz4 (if PostgreSQL was compiled with --with-lz4), and zstd (if PostgreSQL was compiled with --with-zstd). The default value for PostgreSQL 15 is off. See the following code:
In Amazon RDS, it is enabled by default with the zstd option. You can see the performance difference between each available WAL compression method through benchmarking.
The following graph provides a representation of transactions per second (TPS) as they correspond to varying numbers of connections, each associated with distinct WAL compression methods.

The following graph displays the size of WAL files relative to the number of connections for each respective WAL compression method.
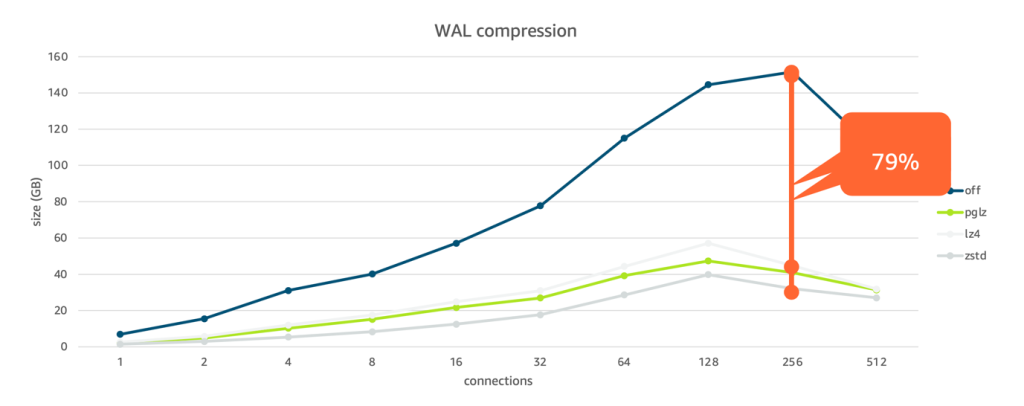
The result shows a significant performance improvement in terms of transactions per second (up to 41% improvement) and reduction in size of WAL generated (up to 79% improvement).
Enhancements in logical replication
Logical replication is a technique of replicating data objects and related changes or transactions at a logical level (based on replication identity). Unlike physical replication, which replicates the entire database cluster, logical replication allows for selective replication of data.
In logical replication, changes made to a source table are captured as a stream of logical changes and then replayed on a target table. This allows for real-time replication of changes, while also allowing for more fine-grained control over what data is replicated.
The following are some use cases for logical replication:
- Real-time replication of data between geographically dispersed databases
- Replication of data between different PostgreSQL versions
- Replication of specific columns or rows within a table
- Synchronization of multiple databases to maintain data consistency
In previous versions of PostgreSQL, logical replication was limited to replicating entire tables. However, in PostgreSQL 15, logical replication has been enhanced to allow for more granular replication, including the ability to replicate specific columns within a table.
The following are the steps to look at column-level replication:
- Set up logical replication in your Aurora PostgreSQL or RDS for PostgreSQL databases. For instructions, refer to Setting up logical replication for your Aurora PostgreSQL DB cluster or Performing logical replication for Amazon RDS for PostgreSQL, respectively.
For the examples in this post, we use Aurora PostgreSQL databases as source and target.
- Connect to the source Aurora PostgreSQL instance and create a source database, table, and publication as follows:
In this example, we create a publication for the
my_tabletable but only replicate the col1 and col2 columns. We then create a subscription to the publication on a target database. - Connect to the target Aurora PostgreSQL instance and create a target database, table with the selected columns, and subscription as follows:
- Insert some data into the source table and verify the target database:
ALTER SUBSCRPTION … SKIP
If incoming data violates any constraints, logical replication will stop until it is resolved. By using the ALTER SUBSCRIPTION … SKIP command, the logical replication worker skips all data modification changes within the transaction. It can be done by specifying the log sequence number (LSN). Note that it requires superuser privileges.
Consider a duplicate transaction on the subscription. The logs show the following entries in the target database logs:
In PostgreSQL 15, with the ALTER SUBSCRPTION … SKIP feature, you can skip particular transactions using the LSN number that’s in the logs:
Now, the logs show that this transaction has been skipped:
Automatically disable logical replication on error
By default, when a conflict arises during logical replication, the worker enters an error loop, repeatedly attempting to apply the same change in the background after restarting. However, a new option (disable_on_error) allows the subscription worker to automatically disable the subscription upon encountering an error, breaking the loop. This empowers users to make informed decisions on how to proceed. Furthermore, during the initial table synchronization, any failures will also disable the subscription. The default value for this option is false—the same error would be recurring in case of a conflict. The following command sets the option:
You can enable the replication when the publisher is ready:
Publish all tables in a schema
Previously, you could only publish all tables in a database. However, PostgreSQL 15 allows you to publish all the tables in a specific schema:
SELECT DISTINCT
In PostgreSQL 15, the SELECT DISTINCT query can be parallelized using a two-phase distinct process. In phase 1, parallel workers make rows distinct by either hashing or sorting them. The results from the parallel workers are then combined, and the final distinct phase is performed serially to remove any duplicate rows that appear due to combining rows for each of the parallel workers. This allows PostgreSQL to improve the performance of SELECT DISTINCT queries on large datasets by splitting the work across multiple CPU cores.
Let’s look at the following example in PostgreSQL 14 and PostgreSQL 15.
In PostgreSQL 14, we use the following code:
You can see the normalSeq Scanon the table for the DISTINCT query.
In PostgreSQL 15, we use the following code:
You can see theParallel Seq Scanon the table for the DISTINCT query.
Improved performance for sorts that exceed work_mem
In version 14, PostgreSQL uses a polyphase merge algorithm for sorting. However, in PostgreSQL 15, this algorithm is replaced with a simple balanced k-way merge algorithm. Due to this, sorting on a single column is improved in PostgreSQL 15.
Let’s look at the following example in PostgreSQL 14 and PostgreSQL 15.
In PostgreSQL 14, use the following code:
The process took 1.9 seconds, and sorting went to disk with 41176 KB in size.
In PostgreSQL 15, use the following code:
The process took 1.6 seconds, and sorting went to disk with 35280 KB in size, an improvement of approximately 12.18% in query runtime.
Let’s consider Amazon RDS Optimized Reads (using a db.r6gd.large instance) for the same example:
With the same disk sort (35280 KB), the runtime is 1.1 seconds, which is another 30% improvement.
PUBLIC schema permissions and ownership
PostgreSQL 15 has introduced several new security enhancements, one of which is the removal of the PUBLIC creation permission on the public schema. The public schema is the default schema that is created when a new database is created. This schema is owned by the default user, usually the installation user, and is used to store all objects that are created without specifying a schema. This change is designed to improve the security of PostgreSQL databases by restricting access to the public schema.
In previous versions of PostgreSQL (14 and earlier), the public schema was created automatically and was accessible to all users by default. This meant that by default, users with access to this database could create objects in the public schema, which under certain conditions could allow users to create attacks, as specified in CVE-2018-1058.
To mitigate this issue, PostgreSQL 15 removes the ability for users to create objects in the public schema by default. Instead, users must explicitly grant the CREATE permission on the public schema to other users or roles if they wish to allow them to create objects in the public schema.
Note that this change could impact people upgrading, particularly those who have existing database bootstrapping scripts that rely on the previous behavior.
In PostgreSQL 14, use the following code:
As you can see, the new user has permissions on the public schema by default.
In PostgreSQL 15, use the following code:
PostgreSQL 15 doesn’t allow new users to create objects in the public schema by default. You would need to explicitly grant CREATE privileges to specific users on the public schema.
The following code is an example of how to remove PUBLIC creation permission on the public schema prior to PostgreSQL 15:
Prior to PostgreSQL 15, the public schema was owned by the database superuser postgres (or the bootstrap user) role by default in any database. You typically provide ownership to a user because it’s a trusted user. However, the risk comes from being able to perform trojan-style attacks that can subvert the database owner or superuser (CVE-2018-1058). This is a risk mitigation feature to help remove that attack vector.
To address this issue, the public schema is owned by the new pg_database_owner role in PostgreSQL 15 by default. The role is automatically granted to the database owner when the new database is created.
In PostgreSQL 15, use the following code:
To change the owner of the public schema to the new pg_database_owner role prior to PostgreSQL 15, run the following SQL command:
Security invoker views
PostgreSQL 15 includes a new feature that allows you to create views with the security invoker option. Security invoker views are run with the permissions of the user accessing the view, not the creator. This provides an extra layer of security and control over the data that is returned by the view.
To create a view with the security invoker option, add the SECURITY INVOKER clause to the CREATE VIEW statement, as shown in the following example:
UNIQUE NULLS NOT DISTINCT
PostgreSQL 14 and older versions are treating NULL values as distinct or not equal to other NULL values. This is in line with the SQL standard because NULL is an unknown value. Therefore, it’s comparing one unknown to another unknown. In earlier PostgreSQL versions, a UNIQUE constraint could still accept multiple rows with NULL values.
In PostgreSQL 14, use the following code:
As you can see in the preceding example, although there is a unique constraint created on the name and dept columns, we can still add repeated NULL values in the dept column.
With the new option, the unique constraint defined on the latest_version table has become more restraining.
In PostgreSQL 15, use the following code:
The row is added successfully. Now, if we try to add another row in this table with NULL in the dept column, it throws a unique constraint violation error:
The UNIQUE NULLS NOT DISTINCT option adds a more granular level of control in handling NULLs in PostgreSQL. This is an additional option available starting from PostgreSQL 15 and the default behavior will be still the same as that of PostgreSQL versions 14 and earlier.
Conclusion
PostgreSQL 15 introduces impactful features and enhancements that make it more straightforward to manage complex data workloads while improving security and performance. You can get started using PostgreSQL 15 on Aurora and Amazon RDS, and use features such as Amazon RDS Optimized Reads to further accelerate performance with PostgreSQL 15 features.
Take advantage of the great new features in PostgreSQL version 15 and experience the potential for even more innovation in future releases. Join the community mailing lists and stay up to date with the latest developments in one of the most powerful and reliable database management systems available.
About the Authors
 Baji Shaik is a Sr. Lead Consultant with AWS Professional Services, Global Competency Centre. His background spans a wide depth and breadth of expertise and experience in SQL and NoSQL database technologies. He is a Database Migration Expert and has developed many successful database solutions addressing challenging business requirements for moving databases from on premises to Amazon RDS and Amazon Aurora PostgreSQL/MySQL. He is an eminent author, having written several books on PostgreSQL. A few of his recent works include “PostgreSQL Configuration,” “Beginning PostgreSQL on the Cloud,” and “PostgreSQL Development Essentials.” Furthermore, he has delivered several conference and workshop sessions.
Baji Shaik is a Sr. Lead Consultant with AWS Professional Services, Global Competency Centre. His background spans a wide depth and breadth of expertise and experience in SQL and NoSQL database technologies. He is a Database Migration Expert and has developed many successful database solutions addressing challenging business requirements for moving databases from on premises to Amazon RDS and Amazon Aurora PostgreSQL/MySQL. He is an eminent author, having written several books on PostgreSQL. A few of his recent works include “PostgreSQL Configuration,” “Beginning PostgreSQL on the Cloud,” and “PostgreSQL Development Essentials.” Furthermore, he has delivered several conference and workshop sessions.
 Jonathan Katz is a Principal Product Manager – Technical on the Amazon RDS team and is based in New York. He is a Core Team member of the open-source PostgreSQL project and an active open-source contributor.
Jonathan Katz is a Principal Product Manager – Technical on the Amazon RDS team and is based in New York. He is a Core Team member of the open-source PostgreSQL project and an active open-source contributor.
![]() Swanand Kshirsagar is a Lead Consultant within the Professional Services division at Amazon Web Services. He specializes in collaborating with clients to architect and implement scalable, robust, and security-compliant solutions within the AWS Cloud environment. His primary expertise lies in orchestrating seamless migrations, encompassing both homogenous and heterogeneous transitions, facilitating the relocation of on-premises databases to Amazon RDS and Amazon Aurora PostgreSQL with efficiency.
Swanand Kshirsagar is a Lead Consultant within the Professional Services division at Amazon Web Services. He specializes in collaborating with clients to architect and implement scalable, robust, and security-compliant solutions within the AWS Cloud environment. His primary expertise lies in orchestrating seamless migrations, encompassing both homogenous and heterogeneous transitions, facilitating the relocation of on-premises databases to Amazon RDS and Amazon Aurora PostgreSQL with efficiency.