AWS Database Blog
Modify SSIS packages from SQL Server to Babelfish for Aurora PostgreSQL
July 2023: This post was reviewed for accuracy.
Customers want to migrate from SQL Server to license-free databases like Amazon Aurora PostgreSQL–Compatible Edition, but it takes considerable work from an application point of view. Applications have SQL Server database code written in T-SQL; to modify that takes effort and is time-consuming. With Babelfish for Aurora PostgreSQL, you can make this process much simpler and easier.
If you’re planning to migrate or have migrated from SQL Server to Babelfish for PostgreSQL, which supports running T-SQL queries against PostgreSQL databases, you may be wondering, what’s going to happen to your SSIS packages? Your SSIS package is an important part of your workload for SQL Server.
This post provides steps to modify your existing Microsoft SSIS package connection from SQL Server to Babelfish.
Solution overview
Babelfish for Aurora PostgreSQL provides an endpoint for an Aurora PostgreSQL DB cluster that supports the SQL Server TDS protocol and the T-SQL dialect. With this endpoint, you can accelerate migrations from SQL Server to Aurora PostgreSQL. This endpoint makes it possible for your Aurora database to understand the SQL Server wire protocol and commonly used T-SQL statements. With Babelfish for PostgreSQL, applications that were originally built for SQL Server can work directly with PostgreSQL with few to no code changes and without changing connectivity drivers in existing client applications.

Babelfish is a optional Aurora feature and incurs no additional cost. Please note that Babelfish will not host SSIS packages, you will need an instance of SQL Server running SSIS components.
The SSIS package has many control flow tasks. The following tasks use database connections, including SQL Server:
- Execute SQL
- Execute T-SQL Statement
- Bulk Insert
- Data Flow
Prerequisites
Before you get started, make sure you have the following prerequisites:
- SQL Server Integration Services components
- SQL Server 2012 or newer version
- Visual Studio with SQL Data Tools installed
- Aurora for PostgreSQL with Babelfish enabled
Execute SQL task
The Execute SQL task runs SQL statements or stored procedures from a package. The task can contain either a single SQL statement or multiple SQL statements that run sequentially.
The Execute SQL task supports the following providers in connections using Babelfish for Aurora PostgreSQL:
- Native OLEDB\SQL Server Native Client X.X
- .NET Provider OLEDB\SQL Server Native Client X.X
- .NET Provider\SQL Client Data Provider X.X
To create or modify the connections for the Execute SQL task, complete the following steps:
- Choose any supported provider from the preceding list on the Provider drop-down menu.
- For Server name, enter the Babelfish for Aurora PostgreSQL endpoint.
- Enter your user credentials.
- For Connect to a database, select Select or enter a database name.
- Choose or enter a database.
- Choose OK.
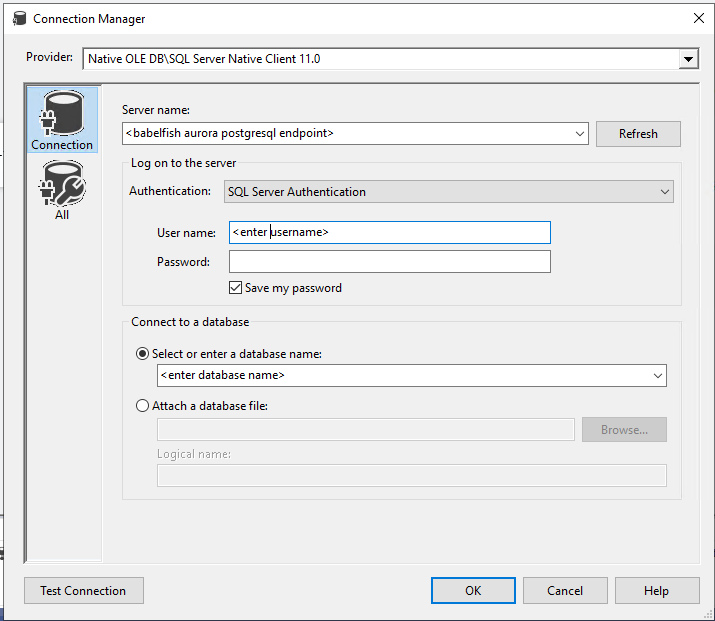
The following screenshot shows the Execute SQL Task Editor pane, where you can create your Execute SQL task.

Execute T-SQL Statement task
The Execute T-SQL Statement task is similar to the Execute SQL task. However, the Execute T-SQL Statement task supports only the Transact-SQL version of the SQL language, and you can’t use this task to run statements on servers that use other dialects of the SQL language. If you need to run parameterized queries, save the query results to variables, or use property expressions, you should use the Execute SQL task instead of the Execute T-SQL Statement task.
Use .NET Provider\SQL Client Data Provider X.XX to create a connection.

You can test the connection and also test the Execute T-SQL Statement task.
Bulk Insert task
As of this writing, Babelfish for Aurora PostgreSQL doesn’t support using a BULK INSERT Statement. Instead, use the COPY command in PostgreSQL.
Data Flow task
The Data Flow task encapsulates the data flow engine that moves data between sources and destinations, and lets you transform, clean, and modify data as it’s moved.
Create or modify the SSIS Data Flow task using Babelfish for Aurora PostgreSQL as a source
The following supporting providers use connections to Babelfish for Aurora PostgreSQL as a source in the Data Flow task:
- Native OLEDB\SQL Server Native Client X.X
- .NET Provider OLEDB\SQL Server Native Client X.X
- .NET Provider\SQL Client Data Provider X.X
To create a Data Flow task using one of these connections, complete the following steps:
- Create a connection for Aurora Postgres Babelfish as a source using any of the providers in the preceding list.
- For Server name, enter the Babelfish Aurora PostgreSQL endpoint.
- Enter your credentials to connect.
- For Connect to a database, select Select or enter a database name.
- Choose or enter the database name.
- Choose Test Connection.
- If the test connection succeeds, choose OK.

- Create a Data Flow task.

- Open the Data Flow task.
- In the Toolbox, choose OLE DB Source.
- For the OLE DB connection manager, choose the connection using Native OLEDB\SQL Server Native Client X.X.
- For Data access mode, choose SQL command.
- For SQL command text, enter the SELECT statement.
- Choose Columns and select the columns to include in the transformation.
- Choose OK.
- Choose Flat File Destination.
- Choose New to create a new connection or choose the existing text file connection (if you have an existing package with a connection).
- In the Flat File Connection Manager Editor pane, choose or enter your file path.
- Enter or choose the CSV file properties.
- Choose Columns and enter delimiters of the CSV file.
- Choose OK.
- In the Flat File Destination Editor pane, choose Mappings.
- Map the columns you want to export to a CSV file and choose OK.
Now the Data Flow task should look like the following screenshot without any errors.

- Run the package or run the Data Flow itself.
- To monitor the Data Flow task, open the task and note the transformation state.
Similarly, you can also update the Data Flow task with ADO .Net Source to a Babelfish for Aurora PostgreSQL endpoint.
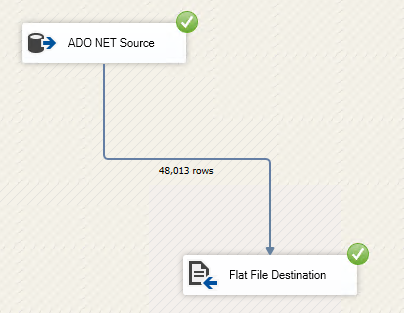
- Verify the file was created in the destination folder.
Create or modify the SSIS Data Flow task using Babelfish for Aurora PostgreSQL as a destination
Use the following providers when creating connections using Babelfish for Aurora PostgreSQL as a destination in the Data Flow task:
- .NET Provider OLEDB\SQL Server Native Client X.X
- .NET Provider\SQL Client Data Provider X.X
To create a Data Flow task using one of these connections, you first create an Aurora Postgres for Babelfish connection as a destination.
- Choose Connections manager (right-click) and create a new connection choosing one of the supported providers in the preceding list.
- For Server name, enter the Babelfish for Aurora PostgreSQL endpoint.
- Enter your credentials.
- For Connect to a database, select Select or enter a database name.
- Choose or enter the database name.
- Choose Test Connection.
- If the test succeeds, choose OK.
Now you create a flat file connection as a source connection. If you already have one, you can skip this series of steps.
- Choose Connections manager (right-click) and create a new flat file connection.
- Choose the file name that you want to import the data.
- Choose Columns and select row and column delimiters.
- Choose OK.
Now you create a Data Flow task.
- In the Toolbox, choose Flat File Source and choose the flat file connection.
- Choose ADO NET Destination in the Toolbox and choose the Aurora Postgres for Babelfish connection.
- Choose Flat File Source and drag the green arrow to ADO NET Destination.
- Choose Mappings.
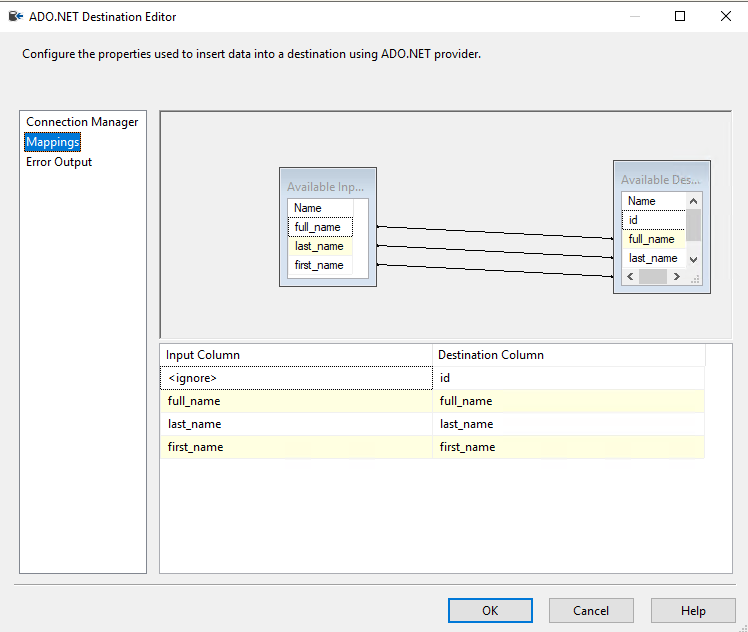
- Run the package or run the Data Flow task.
- To check the status of the Data Flow task, open the task and verify the state.

Conclusion
Your SSIS package is important part of your workload for SQL Server. With Babelfish for Aurora PostgreSQL, you can create SSIS packages or modify your existing one using the connections with Babelfish.
In this post, we provided steps to modify an existing Microsoft SSIS package connection from SQL Server to Babelfish. If you have an Execute T-SQL and Execute SQL task, and SQL Server as your source and destination connection using Native OLEDB SQL Server Native Client, .NET Provider OLEDB Client, or .NET Provider SQL Client, these connections work with Babelfish.
To learn more about Babelfish, check out Getting Started with Babelfish.
About the Authors
 Chandra Pathivada is a Senior Database Specialist Solutions Architect with Amazon Web Services. He works with AWS RDS team, focusing on Opensource database engines like RDS PostgreSQL and Aurora PostgreSQL. He enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS
Chandra Pathivada is a Senior Database Specialist Solutions Architect with Amazon Web Services. He works with AWS RDS team, focusing on Opensource database engines like RDS PostgreSQL and Aurora PostgreSQL. He enjoys working with customers to help design, deploy, and optimize relational database workloads on AWS
 Yogi Barot is Microsoft Specialist Senior Solution Architect at AWS, she has 22 years of experience working with different Microsoft technologies, her specialty is in SQL Server and different database technologies. Yogi has in depth AWS knowledge and expertise in running Microsoft workload on AWS.
Yogi Barot is Microsoft Specialist Senior Solution Architect at AWS, she has 22 years of experience working with different Microsoft technologies, her specialty is in SQL Server and different database technologies. Yogi has in depth AWS knowledge and expertise in running Microsoft workload on AWS.