AWS Database Blog

Amazon Aurora for MySQL compatibility now supports global transaction identifiers (GTIDs) replication
In this blog post, we discuss the advantages of GTID-based replication and support of Amazon Aurora for MySQL.

Analyze URL paths to search individual elements in Amazon Elasticsearch Service
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details. If you’re building a data lake in the AWS cloud, you’ll most likely want to have metadata and catalog search capability for the underlying data. We recommend Amazon Elasticsearch Service (Amazon ES) for storing and searching S3 keys, and S3 […]

How to Scale AWS Database Migration Service (DMS) replication instances
AWS Database Migration Service (DMS) helps you migrate databases to AWS quickly and securely. The AWS DMS migration process encompasses setting up a replication instance, source and target endpoints, and replication tasks. Your replication instance uses resources like CPU, memory, storage, and I/O, which may get constrained depending on the size of your instance and the […]
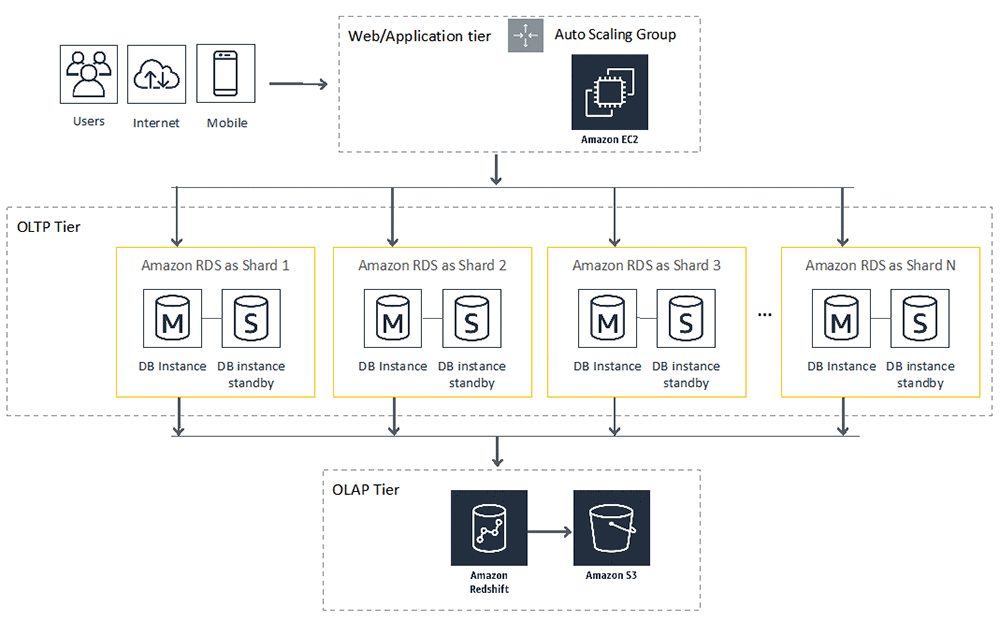
Sharding with Amazon Relational Database Service
Sharding, also known as horizontal partitioning, is a popular scale-out approach for relational databases. Amazon Relational Database Service (Amazon RDS) is a managed relational database service that provides great features to make sharding easy to use in the cloud. In this post, I describe how to use Amazon RDS to implement a sharded database […]

Boosting application performance and reducing costs with Amazon ElastiCache for Redis
Contributed by Senior Software Development Engineer, Shawn Wang, Software Development Engineer, Maddy Olson, and Senior Manager, Software Engineering, Itay Maoz. Amazon ElastiCache for Redis helps customers achieve extreme performance with very low latencies at cloud scale and minimal management costs. Redis’s high performance, simplicity, and support for diverse data structures have made it the most […]

How to design Amazon DynamoDB global secondary indexes
Back in college, I created entity-relationship diagrams to model the system requirements of a relational database. The process involved finding all of the entities of the software system and defining relationships among them. I then modeled the relationships and entities into database tables before deciding which queries the database had to support. This method of […]
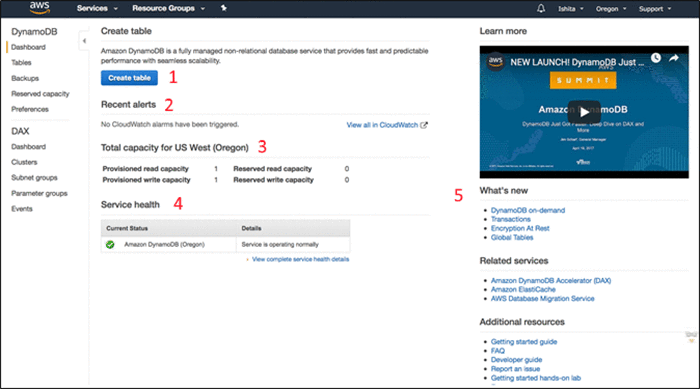
Everything you ever wanted to know about the Amazon DynamoDB console but were afraid to ask: A detailed walkthrough
Since its release in 2012, Amazon DynamoDB has become a fully managed, multi-region, multimaster database service designed to deliver fast and predictable performance at any scale. DynamoDB is a NoSQL database that provides three options for performing operations: a web-based console, the AWS Command Line Interface (CLI), and a set of SDKs for a number […]
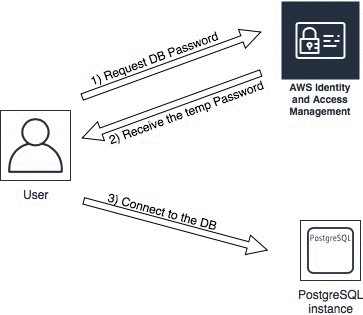
Managing PostgreSQL users and roles
July 2023: This post was reviewed for accuracy. PostgreSQL is one of the most popular open-source relational database systems. With more than 30 years of development work, PostgreSQL has proven to be a highly reliable and robust database that can handle a large number of complicated data workloads. PostgreSQL is considered to be the primary […]

New Amazon DocumentDB features for aggregations, arrays, and indexing
Amazon DocumentDB (with MongoDB compatibility) is a fast, scalable, highly available, and fully managed document database service that supports MongoDB workloads. You can use the same MongoDB application code, drivers, and tools as you do today to run, manage, and scale workloads on Amazon DocumentDB. This way, you can enjoy improved performance, scalability, and availability without having to […]
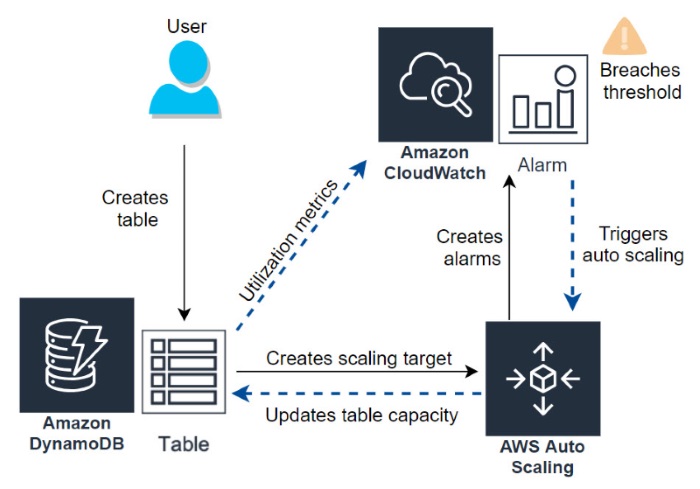
Amazon DynamoDB auto scaling: Performance and cost optimization at any scale
September 2022: This post was reviewed for accuracy. Scaling up database capacity can be a tedious and risky business. Even veteran developers and database administrators who understand the nuanced behavior of their database and application perform this work cautiously. Despite the current era of sharded NoSQL clusters, increasing capacity can take hours, days, or weeks. […]