AWS Database Blog
Category: Amazon Simple Storage Service (S3)

Automate PostgreSQL audit log extraction and analysis with Amazon S3
In this post, we show you how to deploy an automated pipeline that extracts PostgreSQL audit logs from CloudWatch Logs, converts them into structured comma-separated values (CSV) format, and stores them in Amazon S3 for long-term analysis. The solution processes log entries in near real time after generation.

Converting an RDS for SQL Server instance from license included to Bring Your Own Media (BYOM)
Amazon RDS for SQL Server recently launched Bring Your Own Media (BYOM), so you can use your existing SQL Server licenses with fully managed RDS instances. This is particularly valuable if you have existing Microsoft licensing agreements and want to optimize your cloud spending by using those investments on AWS. If you’re already running RDS for SQL Server with the license-included (LI) model, you can now convert those instances to BYOM in place, no database migration required. In this post, we walk you through the end-to-end conversion process: preparing your installation media, creating a BYOM engine version, and performing the in-place license model change.

Similarweb’s migration from HBase to Amazon DynamoDB
Managing massive data volumes at scale presents significant operational challenges. At Similarweb we faced these challenges with Apache HBase and found a solution in Amazon DynamoDB. Similarweb is a digital intelligence platform that provides AI-powered insights into website traffic, app usage, and market trends to help businesses benchmark competitors and optimize growth strategies. We faced growing scalability and operational complexity issues with our existing Apache HBase infrastructure, which prompted us to explore more flexible and efficient alternatives. This post walks you through our journey migrating our data storage from Apache HBase to DynamoDB. We discuss the technical challenges, migration approach, data modeling strategies, cost optimization techniques, and key benefits achieved along the way.

Automate Amazon Aurora PostgreSQL major or minor version upgrade using AWS Systems Manager and Amazon EC2
Managing Aurora PostgreSQL-Compatible Edition upgrades across multiple database clusters can be time-consuming and error-prone when done manually. In this post, we show you how to automate Amazon Aurora PostgreSQL upgrades across your entire database fleet through consistent, repeatable procedures.

Query billion-scale vectors with SQL: Integrating Amazon S3 Vectors and Aurora PostgreSQL
In this post, you’ll learn how to query Amazon S3 Vectors from Amazon Aurora PostgreSQL-Compatible Edition using standard SQL, and how to combine vector similarity results with relational filters in a single query, for example, finding the most semantically similar products and then filtering by price, stock status, or tenant in one SQL statement.

AWS purpose-built database recovery: A guide to business continuity and disaster recovery strategies
This post addresses recovery challenges in multi-database architectures, focusing on both low-consistency and mission-critical scenarios. We explore practical strategies for implementing resilient recovery mechanisms across Amazon DynamoDB, Amazon Aurora, Amazon Neptune, Amazon OpenSearch Service, and other AWS database services.

Stream live data from Amazon Keyspaces to S3 vector for real time AI applications
In this post, you learn how to build a real-time AI movie recommendation system by streaming live data changes from Amazon Keyspaces to Amazon S3 vector storage. The post shows how to use Keyspaces change data capture streams to capture database modifications, convert them into vector embeddings using Amazon Bedrock, and store them in S3 Vector indexes for similarity searches that give AI applications access to fresh data within milliseconds.

Export Amazon SimpleDB domain data to Amazon S3
As AWS continues to evolve its services to better align with customer needs and modern workloads, we’re excited to introduce a new export functionality for Amazon SimpleDB . By using this feature, you can export domain data to Amazon S3 in JSON format, unlocking new opportunities for long-term storage, and migration to purpose-built databases. The export generates a complete JSON representation of Amazon SimpleDB data. In this post, we walk you through how to use the new export functionality, highlight best practices, and share monitoring functionality to help you make the most of it.
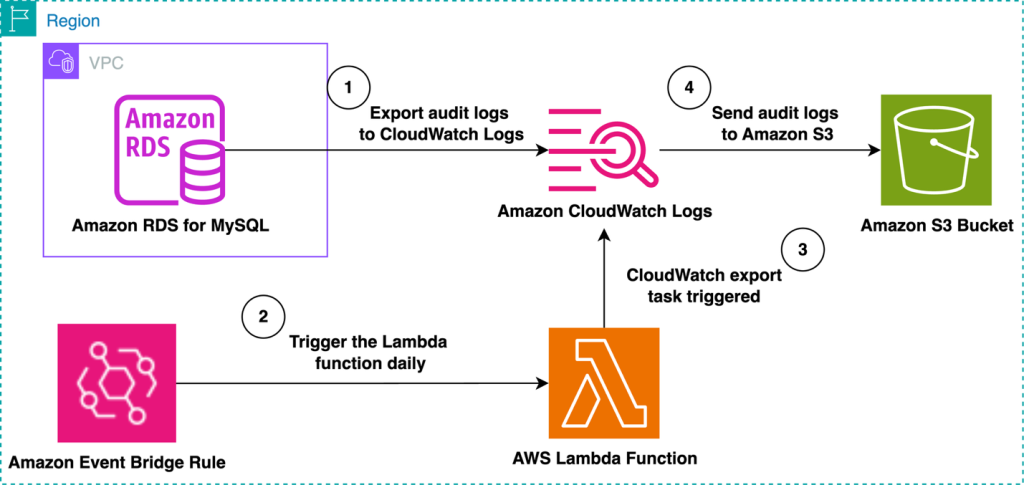
Automate the export of Amazon RDS for MySQL or Amazon Aurora MySQL audit logs to Amazon S3 with batching or near real-time processing
Amazon RDS for MySQL and Amazon Aurora MySQL provide built-in audit logging capabilities, but customers might need to export and store these logs for long-term retention and analysis. Amazon S3 offers an ideal destination, providing durability, cost-effectiveness, and integration with various analytics tools. In this post, we explore two approaches for exporting MySQL audit logs to Amazon S3: either using batching with a native export to Amazon S3 or processing logs in real time with Amazon Data Firehose.

Gracefully handle failed AWS Lambda events from Amazon DynamoDB Streams
In this post, we show how to capture and retain failed stream events for later analysis or replay using Amazon S3 as a durable destination. We compare this approach with the traditional Amazon SQS dead-letter queue (DLQ) pattern, and explain when and why Amazon S3 is a preferred option.