AWS Database Blog
Category: Analytics

AWS purpose-built database recovery: A guide to business continuity and disaster recovery strategies
This post addresses recovery challenges in multi-database architectures, focusing on both low-consistency and mission-critical scenarios. We explore practical strategies for implementing resilient recovery mechanisms across Amazon DynamoDB, Amazon Aurora, Amazon Neptune, Amazon OpenSearch Service, and other AWS database services.
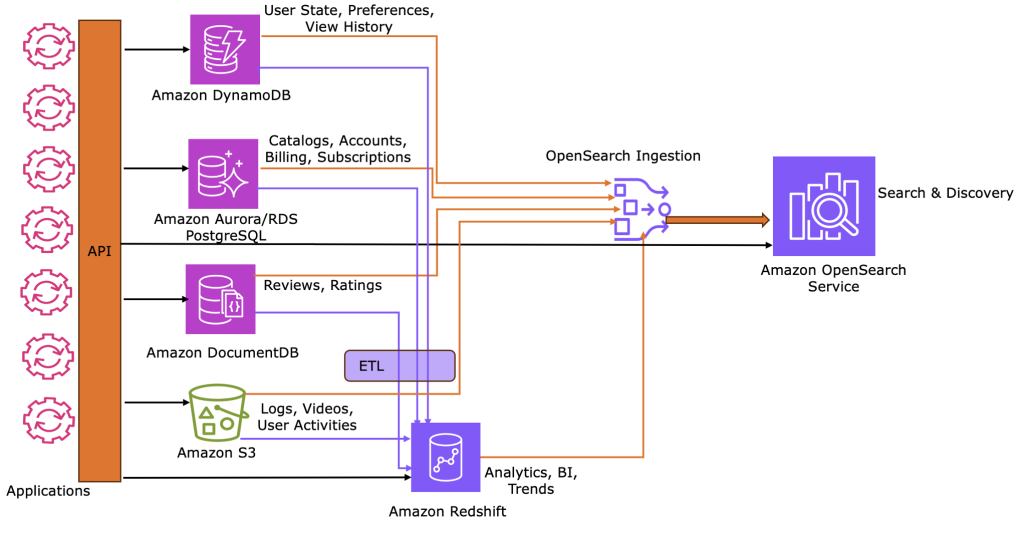
How to build unified JSON search solutions in AWS
Using a movie streaming reference architecture, this post shows how to implement and sync operational, analytical, and search JSON workloads across AWS services. This pattern provides a scalable blueprint for any use case requiring multi-modal JSON data capabilities.
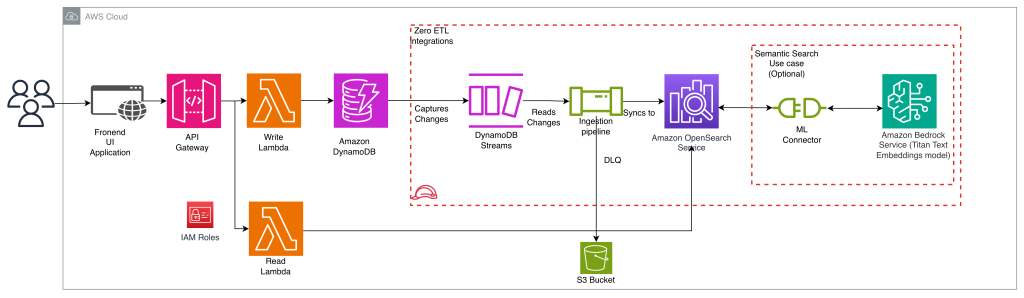
Implementing search on Amazon DynamoDB data using zero-ETL integration with Amazon OpenSearch service
In this post, we show you how to implement search on Amazon DynamoDB data using the zero-ETL integration with Amazon OpenSearch Service. You will learn how to add full-text search, fuzzy matching, and complex search queries to your application without building and maintaining data pipelines.

Optimize LLM response costs and latency with effective caching
In this post, we talk about the benefits of caching in generative AI applications. We also elaborated on a few implementation strategies that can help you create and maintain an effective cache for your application.
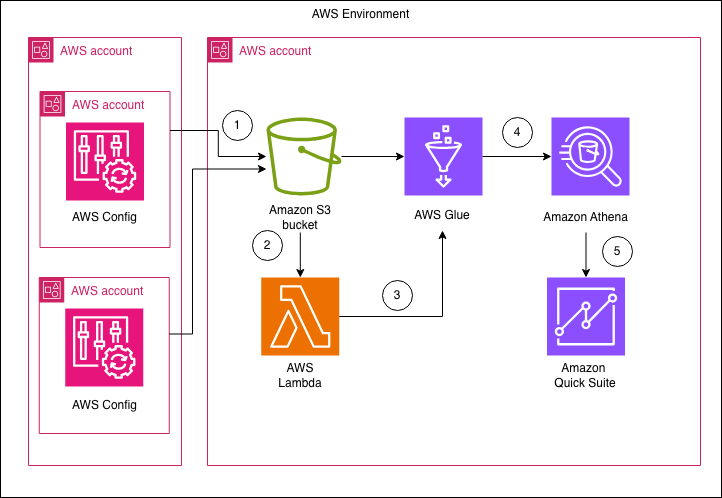
Enhance the visibility of Amazon RDS instances and configuration with AWS Config and Amazon Quick Suite
In this post, we show you how to build a centralized dashboard for monitoring Amazon RDS configurations across your organization by using AWS Config and Amazon Quick Suite. This solution delivers detailed insights across different areas, such as summary metrics, backup configurations, security posture, engine and support information, extended configurations, and resource tagging.

Analyze JSON data efficiently with Amazon Redshift SUPER
Amazon Redshift transforms how organizations analyze JSON data by combining the analytical power of a columnar data warehouse with robust JSON processing capabilities. By using Amazon Redshift SUPER datatype, you can efficiently store, query, and analyze complex hierarchical data alongside traditional structured data without sacrificing performance. This post focuses on JSON features of Amazon Redshift.

Efficiently compare items across two Amazon DynamoDB tables
In this post, we show an algorithm to efficiently compare two Amazon DynamoDB tables and find the differences between their items. We provide an example where two tables, each containing approximately half a billion items, are compared in less than 7 minutes, for less than $10.

Rate-limiting calls to Amazon DynamoDB using Python Boto3, Part 2: Distributed Coordination
Part 1 of this series showed how to rate-limit calls to Amazon DynamoDB by using Python Boto3 event hooks. In this post, I expand on the concept and show how to rate-limit calls in a distributed environment, where you want a maximum allowed rate across the full set of clients but can’t use direct client-to-client communication.

GroundTruth reduces costs by 45% and improves reliability migrating from Aerospike to Amazon ElastiCache for Valkey
GroundTruth, an advertising platform leading the way in location- and behavior-based marketing, empowers brands to connect with consumers through real-world behavioral data to drive real business results. As our advertising platform scaled to process increased volume of ad requests and third-party segment ingestion, maintaining our Aerospike-based caching infrastructure introduced significant operational complexity and rising costs, while also compromising performance and limiting our ability to scale efficiently. To meet our requirements we implemented Amazon ElastiCache for Valkey, which streamlined our operations, improved reliability, and reduced costs. In this post, we walk through our migration journey, covering the migration strategy we adopted, the optimizations we made to reduce cost by 45%, reliability improvements including reducing write failures by 20x, and operational gains from managed service capabilities.

Amazon Aurora MySQL zero-ETL integration with Amazon SageMaker Lakehouse
In this post, we explore how zero-ETL integration works, the key benefits it delivers for data-driven teams, and how it aligns with the broader zero-ETL strategy in AWS services. You’ll learn how this integration can enhance your data workflows, whether you’re building predictive models, entering interactive SQL queries, or visualizing business trends. By eliminating traditional extract, transform, and load (ETL) processes, this solution enables real-time intelligence securely and at scale to help you make faster, data-driven decisions.