AWS Database Blog
Category: Amazon Managed Streaming for Apache Kafka (Amazon MSK)

Build a streaming ETL pipeline on Amazon RDS using Amazon MSK
Customers who host their transactional database on Amazon Relational Database Service (Amazon RDS) often seek architecture guidance on building streaming extract, transform, load (ETL) pipelines to destination targets such as Amazon Redshift. This post outlines the architecture pattern for creating a streaming data pipeline using Amazon Managed Streaming for Apache Kafka (Amazon MSK). Amazon MSK offers a fully managed Apache Kafka service, enabling you to ingest and process streaming data in real time.

Stream change data in a multicloud environment using AWS DMS, Amazon MSK, and Amazon Managed Service for Apache Flink
When workloads and their corresponding transactional databases are distributed across multiple cloud providers, it can create challenges in using the data in near real time for advanced analytics. In this post, we discuss architecture, approaches, and considerations for streaming data changes from the transactional databases deployed in other cloud providers to a streaming data solution deployed on AWS.

Real-time serverless data ingestion from your Kafka clusters into Amazon Timestream using Kafka Connect
Organizations require systems and mechanisms in place to gather and analyze large amounts of data as it is created, in order to get insights and respond in real time. Stream processing data technologies enable organizations to ingest data as it is created, process it, and analyze it as soon as it is accessible. In this […]

Build a sensor network using AWS IoT Core and Amazon DocumentDB
In this post, we discuss how you can build an Internet of Things (IoT) sensor network solution to process IoT sensor data through AWS IoT Core and store it with Amazon DocumentDB (with MongoDB compatibility). An IoT sensor network consists of multiple sensors and other devices like RFID readers made by various manufacturers, generating JSON […]

Stream data with Amazon DocumentDB, Amazon MSK Serverless, and Amazon MSK Connect
A common trend in modern application development and data processing is the use of Apache Kafka as a standard delivery mechanism for data pipeline and fan-out approach. Amazon Managed Streaming for Apache Kafka (Amazon MSK) is a fully-managed, highly available, and secure service that makes it simple for developers and DevOps managers to run applications […]

Modernize legacy databases using event sourcing and CQRS with AWS DMS
When moving from monoliths to microservices, you often need to propagate the same data from the monolith into multiple downstream data stores. These include purpose-built databases serving microservices as part of a decomposition project, Amazon Simple Storage Service (Amazon S3) for hydrating a data lake, or as part of a long-running command query responsibility segregation […]

Capture changes from Amazon DocumentDB via AWS Lambda and publish them to Amazon MSK
When using a document data store as your service’s source of truth, you may need to share the changes of this source with other downstream systems. The data events that are happening within this data store can be converted to business events, which can then be sourced into multiple microservices that implement different business functionalities. […]
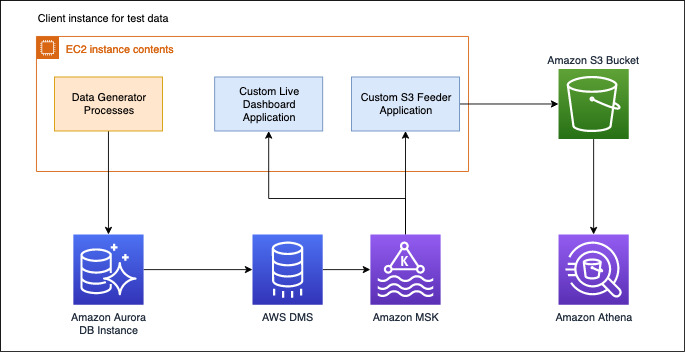
Streaming data to Amazon Managed Streaming for Apache Kafka using AWS DMS
AWS Database Migration Service (DMS) announced support of Amazon Managed Streaming for Apache Kafka (Amazon MSK) and self-managed Apache Kafka clusters as target. With AWS DMS you can replicate ongoing changes from any DMS supported sources such as Amazon Aurora (MySQL and PostgreSQL-compatible), Oracle, and SQL Server to Amazon Managed Streaming for Apache Kafka (Amazon MSK) and self-managed Apache Kafka clusters.
In this post, we use an e-commerce use case and set up the entire pipeline with the order data being persisted in an Aurora MySQL database. We use AWS DMS to load and replicate this data to Amazon MSK. We then use the data to generate a live graph on our dashboard application.

Change data capture from Neo4j to Amazon Neptune using Amazon Managed Streaming for Apache Kafka
After you perform a point-in-time data migration from Neo4j to Amazon Neptune, you may want to capture and replicate ongoing updates in real time. For more information about automating point-in-time graph data migration from Neo4j to Neptune, see Migrating a Neo4j graph database to Amazon Neptune with a fully automated utility. This post walks you […]