AWS Database Blog
Raising the bar on Amazon DynamoDB data modeling
In April 2025, we introduced the Amazon DynamoDB data modeling tool for the Model Context Protocol (MCP) server. The tool guides you through a conversation, collects your requirements, and produces a data model that includes tables, indexes, and cost considerations. It runs inside MCP-enabled assistants such as Amazon Q Developer, Kiro, Cursor, and Windsurf.
As customers began experimenting with the tool, we ran into a familiar challenge: how do you know if the guidance it provides is good? Each interaction produces two artifacts: a dynamodb_requirements.md file and a dynamodb_data_model.md file. But reviewing these outputs by hand was slow, subjective, and difficult to scale. With multiple prompts, model upgrades, and new scenarios, subtle regressions could easily slip through.
To solve this, we set out to build an evaluation system that could score both the process (how requirements are gathered) and the product (the final model). We built a framework combining DSPy, Strands Agents, and Amazon Bedrock into a repeatable loop that gives us measurable signals of quality and lets us ship improvements with confidence.
In this post, we show you how we built this automated evaluation framework and how it helped us deliver reliable DynamoDB data modeling guidance at scale.
From subjective review to measurable signals
Our first step was to define what “good” means for a data modeling conversation. It’s not enough to check whether a table name appears or whether a partition key is correct. We care about whether requirements are captured fully, access patterns are considered, and the proposed schema is scalable and cost-effective.
To understand what we were optimizing for, we manually reviewed 150 real conversations from our teams testing. Each review took over 45 minutes and required deep DynamoDB expertise to spot these nuanced issues.
This manual analysis confirmed that we needed evaluation criteria beyond basic syntax checking. Rather than simply verifying a table has a partition key, we needed to assess whether the conversation methodology was thorough and the resulting schema would actually perform well in production.
DSPy provided the right level of abstraction. Instead of writing brittle rules, we wrote judge programs that use a foundation model (FM) to grade outputs against multi-dimensional criteria. For example, a conversation is judged on requirement gathering, methodology, technical reasoning, and documentation. A data model is judged on completeness, accuracy, scalability, and cost. Each category produces two scores: one for the requirements gathering (session), one for the output data model. This approach turned quality into something we could measure, track, and improve over time.
Why FMs make better judges
Using AI to evaluate AI might seem circular, but recent research validates this approach. Studies show that GPT-4’s agreement with human evaluators reaches 85%, which is higher than human-to-human agreement at 81% (Zheng et al., 2023). For DynamoDB data modeling, this matters because we need to evaluate subjective qualities that traditional metrics can’t capture.
Before settling on FMs as evaluators, we considered several approaches, each with significant limitations:
- Manual review required more than 45 minutes per scenario and suffered from reviewer inconsistency—the same schema could be rated differently depending on the reviewer’s expertise level or fatigue.
- Rule-based checks caught syntax errors (“Does the table have a partition key?”) but missed nuanced design problems such as hot partition risks or unnecessary GSI costs.
- Simple metrics (table counts, access pattern coverage) provided no insight into actual design quality.
FMs solve the core challenge of evaluating holistic, contextual design decisions that rule-based systems can’t handle. They can reason about subjective qualities like “Does this conversation thoroughly gather requirements?” or “Is the technical reasoning for this GSI sound?” while understanding the trade-offs inherent in data modeling. Unlike rigid metrics, LLMs grasp that a design with fewer GSIs might be optimized rather than incomplete, and they recognize how business context drives technical decisions. This contextual understanding makes them uniquely suited for evaluating the nuanced design choices that define quality DynamoDB schemas.
Addressing the limitations
We’re aware of AI judge limitations – inconsistency is real, because the same judge can give different scores on repeated runs. We mitigate this through detailed scoring criteria with specific examples in our DSPy prompts, multiple evaluation runs to detect variance, and version-controlled judge prompts to support reproducible results. Criteria ambiguity poses another risk because different large language model (LLM) judges can interpret “completeness” differently, so we built custom DSPy judge programs with domain-specific prompts rather than relying on generic evaluation tools. By defining exactly what “good requirement gathering” means in a DynamoDB context, we make sure our evaluations are both consistent and meaningful for data modeling quality.
Most importantly, LLM judges give us explainable decisions. Instead of an opaque score, we get detailed reasoning, for example: “Requirement gathering scored 9/10 because the conversation captured all entities and access patterns, but could have probed deeper on query frequency estimates.” This makes evaluation results actionable for improving the tool. For a domain as nuanced as DynamoDB data modeling, FMs provide the contextual understanding that simpler approaches can’t match. They’re not perfect, but they’re sophisticated enough to guide development with confidence.
Driving realistic conversations with Strands Agents
After we knew what to measure, we needed realistic inputs. That’s where Strands Agents came in. With Strands Agents, we can script multi-turn conversations that behave like a real user interacting with the MCP tool. Each scenario, such as designing a simple ecommerce schema, runs end to end, producing requirements and a proposed data model.
By simulating conversations rather than relying on static prompts, we get evaluations that reflect how the tool is actually used. Strands Agents also integrates naturally with Amazon Bedrock, which means we can experiment with different models and quickly see how outputs vary.
Putting it all together
The result is a framework that runs a conversation, captures the artifacts, and evaluates them automatically. A simple runner lets you choose a scenario and model, execute a session, and then see the evaluation scores.
Within minutes, you have both the artifacts and evaluation summary. Instead of combing through transcripts, you can immediately see whether requirement gathering was complete, whether access patterns were mapped correctly, and how well the schema addresses scalability and cost concerns. The following screenshot shows the multi-dimensional scoring output from the evaluator.
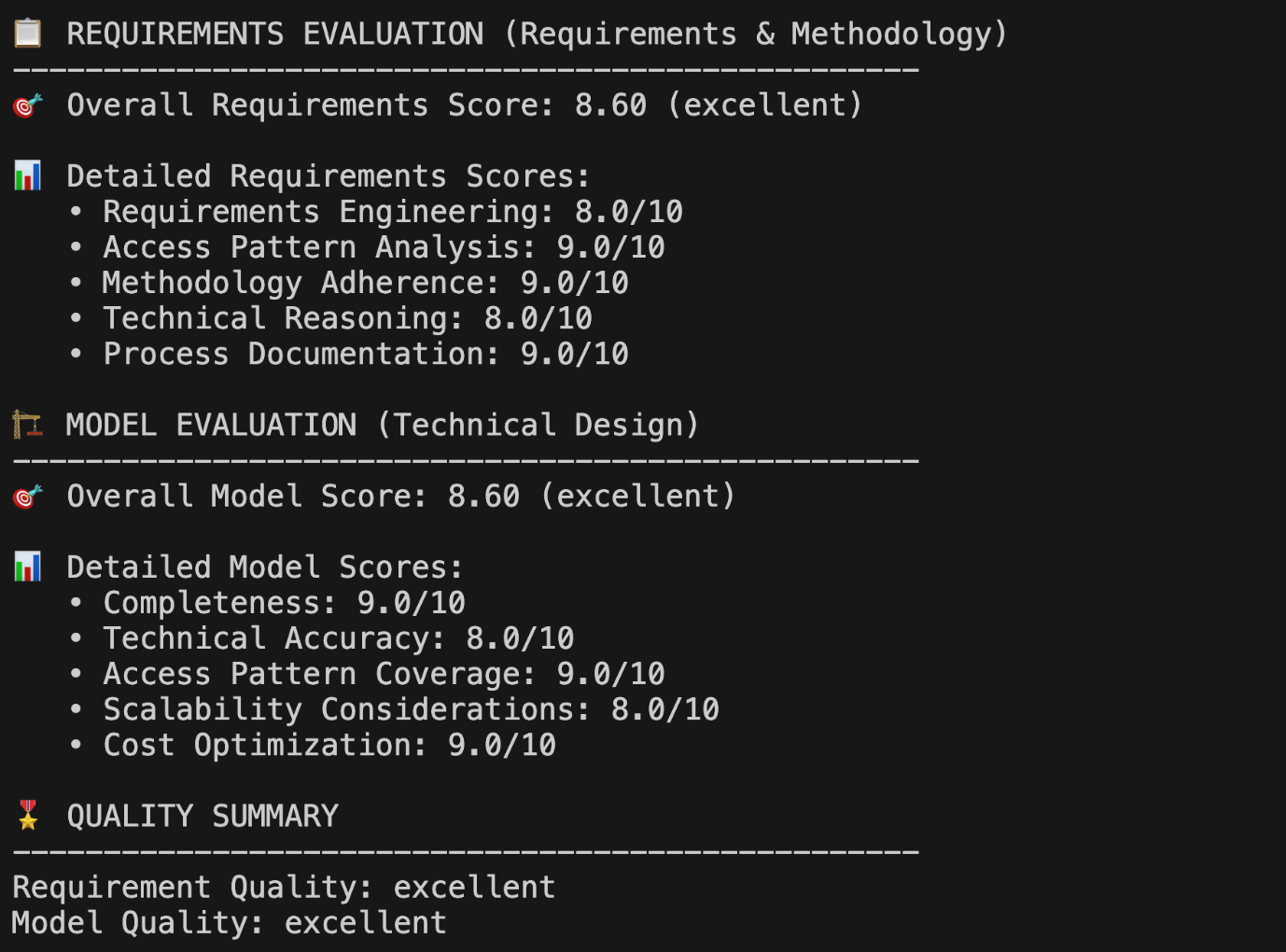
This multi-dimensional scoring gives you immediate insight into what’s working well (access pattern analysis scored 9/10) and what needs attention (technical reasoning at 8/10 suggests room for improvement in scalability depth). Instead of manually reviewing lengthy conversation transcripts, you get actionable feedback in under 3 minutes.
Why this matters
Evaluations like this help us in several ways. They catch regressions early when we refine prompts or change models. They give us a consistent way to compare approaches, rather than relying on anecdotal reviews. And they build trust; when the tool produces a data model, you know it has been tested across multiple scenarios and scored against clear criteria.
For customers, this means the guidance you receive from the DynamoDB data modeling tool continues to improve over time. For builders of MCP tools more broadly, it shows a pattern you can reuse: Strands Agents to simulate realistic conversations, DSPy to define metrics, and Amazon Bedrock to supply the models.
Conclusion
The DynamoDB data modeling tool helps you design for scale, but like other AI-driven systems, it only adds value if the outputs are trustworthy. By combining Strands Agents, DSPy, and Amazon Bedrock, we turned subjective reviews into measurable signals, enabling faster iteration and higher confidence in the tool’s recommendations.
You can explore the evaluation framework in the GitHub repository, read about DSPy’s approach to evaluation, or try Strands Agents to simulate your own MCP workflows. As we continue to evolve the system, our goal is simple: to give you better tools, better models, and better outcomes when building on DynamoDB.