AWS Database Blog
Using delayed read replicas for Amazon RDS for PostgreSQL disaster recovery
Human errors can create substantial risks to business continuity. An accidental DELETE statement, an incorrect batch update, or a faulty application deployment can instantly corrupt years of critical business data. Amazon Relational Database Service(Amazon RDS) provides protection through automated backups and transaction log backups, giving you a reliable safety net. However, the traditional recovery method involves creating new database instances and performing point-in-time recovery. For large databases, this restoration process can extend to several hours, significantly impacting business operations.
AWS recently launched delayed read replicas for Amazon RDS for PostgreSQL. This feature offers an alternative approach for disaster recovery by maintaining a standby replica that intentionally, lags behind the primary database by a configurable time interval, retaining data on the read replica as it existed minutes or hours in the past. This provides you an opportunity to detect data corruption on your production instance and promote the replica before a problematic operation is applied. This mechanism functions as a real-time safety net that reduces recovery complexity compared to traditional point-in-time backup restoration.
When data corruption occurs, you can promote the delayed replica to become the new primary cluster, recovering within minutes. You can enable this feature using the recovery_min_apply_delay parameter. It is available with Amazon RDS for PostgreSQL versions 14.19, 15.14, 16.10, and 17.6 and later.
In this post, we explore the use cases for delayed replication, the recovery procedures, and best practices for managing delayed replicas to help ensure your database recovery strategy is both robust and efficient.
Use cases for delayed replication
Delayed replicas addresses three primary use cases: preventing accidental data modifications, protecting against logical errors in applications, and enabling auditing and forensic analysis. Let’s explore each of these in detail:
- Preventing accidental data modifications – Human errors such as executing
UPDATEorDELETEstatements without properWHEREclauses can instantly corrupt large datasets. A delayed replica provides a buffer period to detect such mistakes on production and promote the replica to recover from the accidental changes. For example, if a database administrator accidentally runsDELETE FROM customer_orders WHERE status = 'pending'instead of targeting a specific date range, the delayed replica provides you a window of time to recover from the mistake. Upon detecting the error, you can catch the replica up until before the disastrous operation and promote the delayed replica to become the new primary, effectively rolling back the accidental changes. - Protection against errors in applications – Application bugs or incorrect deployment logic can introduce risks of corruption through unwanted data changes, such as bulk inserting erroneous records, applying faulty data transformations, or unintended cascade operations that affect multiple tables. Delayed read replicas gives you an opportunity to recover from such errors. When new code contains bugs that modify critical data, you can halt the delayed replica’s Write-ahead Log (WAL) application and use it to restore the correct state.
- Auditing and forensic analysis of data changes: A delayed replica can serve as an auditing resource. It preserves the history of your data for a configurable delay period, so that you can examine and compare past and present data side by side. For example, if you suspect unauthorized or unintended changes, you can query the delayed replica and the primary to see what changed in that interval. Additionally, advanced users can inspect the WAL on the delayed replica using tools like the pg_walinspect extension to pinpoint the exact transactions that occurred. This forensic capability helps in auditing data changes and investigating incidents, all without the complexity of restoring point-in-time backups.
In all these scenarios, delayed replication acts as an “undo buffer” or safety net. It is not a replacement for Automated Backups, but it complements your disaster recovery strategy by offering a real-time point-in-time recovery mechanism. As the PostgreSQL documentation notes, time-delayed replicas can be very useful for correcting data loss errors by providing a window to react.
Set up delayed replication in Amazon RDS for PostgreSQL
At its core, the recovery_min_apply_delay parameter controls PostgreSQL’s WAL replay mechanism at the transaction commit level. When configured in Amazon RDS for PostgreSQL, it modifies the replica’s recovery process by comparing the commit timestamp in each WAL record against the replica’s system clock, creating a deliberate lag in transaction visibility.
For an Amazon RDS for PostgreSQL database instance that has an Amazon RDS for PostgreSQL reader instance the following procedure shows how you can use the AWS CLI to configure delayed replication.
- Create a custom database parameter group:
- Modify the newly created custom database parameter group to configure the
recovery_min_apply_delayparameter. The default value of this parameter is 0 milliseconds (which means no delay) and can be a maximum of 86400000 milliseconds (24 hours). In this example, we configure it to be 43200000 milliseconds (approximately 12 hours):The following screenshot shows modifying the newly created database parameter group to set
recovery_min_apply_delayto 43200000 milliseconds (~12 hours) using the Amazon RDS console.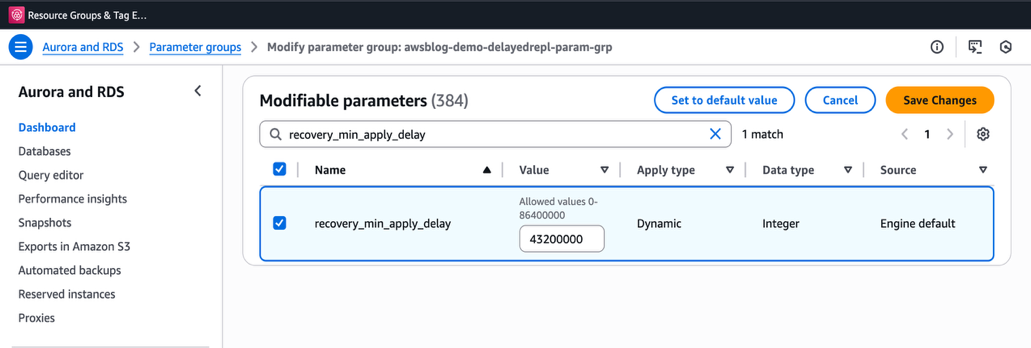
- Modify the read replica database instance to use the custom database parameter and reboot the replica for the database parameter configurations to take effect.
Note: The
recovery_min_apply_delayparameter is a static parameter, you must reboot the replica database for the parameter change to take effect. - Verify that the replica is configured with 12 hours of delay by connecting to the RDS read replica instance and running one of the following queries:
Recovery control functions with delayed replication
The delayed replication feature on RDS for PostgreSQL also introduces access to two recovery functions for greater control over the recovery process.
These functions require the rds_superuser role for execution.
- pg_wal_replay_pause(): Use this function to request a pause in the recovery process. When called, it initiates a pause request, though the actual pause may not occur immediately. To confirm the recovery has fully paused, you can use
pg_get_wal_replay_state(). During a paused state, no new changes are applied to your delayed replica giving you a stable point-in-time view of your data. - pg_wal_replay_resume(): When you’re ready to continue the recovery process, call this function to resume normal operations. The delayed replica will begin applying changes from where it is paused.
Once you pause WAL replay with pg_wal_replay_pause(), you must call pg_wal_replay_resume() to continue replay of WAL logs. Otherwise, WAL logs will accumulate indefinitely on the read replica and cause excessive storage consumption.
Demonstration and recovery with delayed replicas
Let’s explore a common disaster scenario and its resolution using delayed replication.
In this example, we’ll simulate an accidental database drop and demonstrate the recovery process using a delayed replica configured with a 12-hour delay.
At 2025-08-05 22:14:37 UTC, a critical incident occurs when a user accidentally drops a logical database from a production RDS instance. Production applications have begun failing, and a service outage is reported.
Recovering from a dropped database
Since the read replica is delayed by 12 hours, we have time to implement a recovery plan before the dangerous DROP database statement reaches our replica.
- First, we connect to the delayed replica using an account with rds_superuser privileges and verify the replication status. To prevent any further changes, we immediately pause the WAL replay.
- Capturing comprehensive replica metrics:
Given above replication metrics our key observations are:
- The output shows that the read replica is running 48 minutes behind the primary (replication_lag: 00:48:34) which is normal since we have configured a 12-hour intentional delay (configured_delay: 12h).
- There’s approximately 576 MB of WAL data waiting to be replayed (replay_lag_bytes: 603978864), calculated as the difference between the last received WAL position (1/34000000) and last replayed position (1/10000390).
- The last transaction was replayed at 21:52:58 UTC.
- We enabled
log_statements=allconfiguration on our source instance, so this helps with investigating the incident. We can trace the sequence of events and identified a checkpoint at 2025-08-05 22:10:28 UTC with LSN 1/1C000080, occurring before the database drop. Comparing the capturedlast_replayed_lsn=1/10000390on the delayed read replica and the lsn captured on the source instance, we can confirm that (‘1/1C000080’) is ahead of (‘1/10000390’) by 201,325,808 bytes in the WAL stream. - Next, we set the
recovery_target_lsn=1/1C000080 andrecovery_target_inclusive= true on the delayed read replica
Note: If you don’t have pgAudit or log_statements parameter enabled, you can userecovery_target_timeinstead ofrecovery_target_lsn. - We modify our read replica’s parameters and make the following changes:
- Remove the replication delay (
recovery_min_apply_delay) - Set target recovery point (
recovery_target_lsnandrecovery_target_inclusive). Sincerecovery_target_lsnandrecovery_target_inclusiveare static parameters, these changes require a database reboot to take effect.
While we’re settingrecovery_min_apply_delayto 0, this alone won’t restart WAL replay. When WAL replay is explicitly paused usingpg_wal_replay_pause(), it remains paused until manually resumed withpg_wal_replay_resume(), regardless of delay settings.
- Remove the replication delay (
- We connect to the database again and verify that replication delay is removed,
recovery_target_lsnandrecovery_target_inclusiveparameters are set on the database: - We resume the wal replay and monitor our recovery process.
- From the database error logs on the read replica, we see that the recovery was paused after reaching the configured recovery_target_lsn=1/1C000080.
- After confirming the
blog_productiondatabase exists on the replica, we promote the read replica to become our new primary.
Recovering applications from production outage
After the RDS for PostgreSQL read replica database instance is promoted, we verify it is active, healthy, and accepting new connections. We can now modify the RDS for PostgreSQL source instance to rename it to awsblog-demo-source-old and modify the newly promoted database instance to awsblog-demo-source, so that the application traffic can be routed to the newly promoted instance.
Best practices
When implementing delayed replication in Amazon RDS for PostgreSQL, it’s important to follow best practices for optimal performance and to prevent storage-related issues:
Storage management and monitoring
- Set up comprehensive monitoring by configuring Amazon CloudWatch Alarms to track FreeStorageSpace on your source and the delayed replica instance.
- Enable storage auto-scaling on the source as well as the delayed replica instance to
- accommodate WAL log accumulation, which is particularly important when using delayed replication.
- Consider configuring the
max_slot_wal_keep_sizeparameter to automatically rotate WAL logs, helping prevent storage-full conditions. This configuration safely manages WAL data without breaking replication – if streaming is interrupted and WAL is rotated on source, RDS for PostgreSQL switches to recovery mode using archived WAL data from Amazon S3, then automatically re-establishes streaming replication once complete.
Recovery management
- If your source instance or the delayed read replica is using too much storage because WAL logs are piling up, you can manually advance the replica to catch up and free space using Amazon RDS for PostgreSQL’s built-in recovery controls.
- Recovery target parameters:
recovery_target_time– Stop at a specific date/timerecovery_target_lsn– Stop at a specific log positionrecovery_target_name– Stop at a named checkpointrecovery_target_xid– Stop at a specific transactionrecovery_target– General recovery target settingrecovery_target_inclusive– Include or exclude the target point
- WAL replay control functions:
pg_wal_replay_pause()– Stop processing new changespg_wal_replay_resume()– Start processing changes again
- Using these parameters and functions, pause the replica, set your target point, then resume. The replica will catch up to that point and stop, reducing stored WAL logs while keeping your delayed replica functional for recovery purposes. For more details on these database parameters and functions please refer managing-rpg-delayed-replication.
- Recovery target parameters:
- Regularly review your delayed replica’s replication status to monitor the lag, storage consumption, and adjust the delay interval based on your disaster recovery requirements and storage constraints.
Summary
In this post, we showed you how delayed replication in Amazon RDS for PostgreSQL can help you protect your database from data corruption and human errors. While implementing delayed replication requires careful planning and ongoing management, the benefits of having a real-time recovery option far outweigh the operational overhead.