.NET on AWS Blog
Implementing Semantic Search using Amazon Bedrock and RDS for PostgreSQL in .NET
Introduction
Large language models (LLMs) are driving the rapid growth of semantic search applications. Semantic search understands both user intent and content context, rather than just matching keywords. LLMs enhance this capability through their advanced language processing abilities. These AI models can process multiple content formats, including text, images, audio, and video. The users receive comprehensive search results across different media types that match their intent. For example, a natural language query about “how to make sushi” might return text recipes, instructional videos and step-by-step images.
Leading search engine companies integrate semantic search to improve result accuracy. This advancement relies primarily on Embeddings and Vector Database. This blog post walks you through the step-by-step process of implementing semantic search capabilities in a .NET application using Amazon Bedrock and Amazon RDS for PostgreSQL.
Solution Overview
The solution integrates a .NET application with Amazon Titan Text Embeddings models to convert plain text into numeric vectors (embeddings) and stores them in Amazon PostgreSQL database for semantic search operations. This solution uses Amazon Titan Text Embedding v2 model (amazon.titan-embed-text-v2:0) to convert unstructured content like documents, paragraphs, and sentences into vector representations. The embeddings are stored and queried using pgvector, an open source extension for PostgreSQL that adds support for vector operations. This extension provides specialized data types for vector storage and functions for similarity calculations. User can combine these vector capabilities with standard SQL queries to perform complex similarity operations.
The following diagram illustrates the high-level architecture of semantic search application.
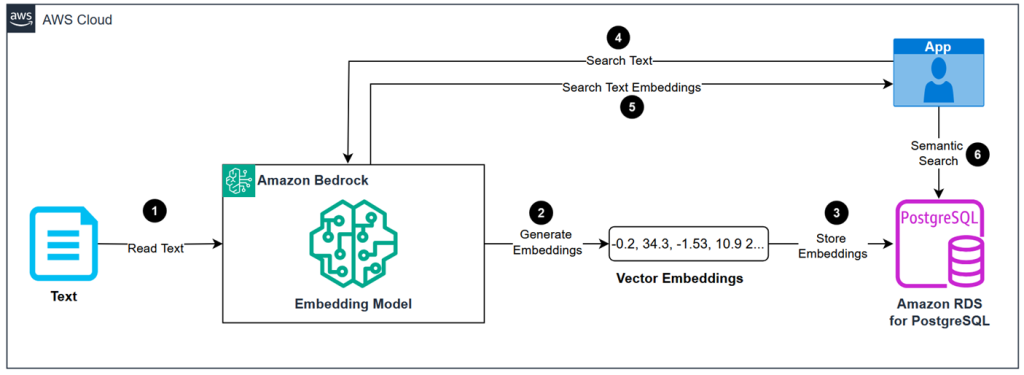
Figure 1: Semantic search application architecture
The solution architecture involves the following steps:
- Send text input to the embedding model in Amazon Bedrock.
- Generate embeddings for the input text.
- Store embeddings in PostgreSQL database.
- Send search query to embedding model in Amazon Bedrock.
- Generate embeddings for search query.
- Execute semantic search queries against stored embeddings.
Prerequisites
Before proceeding, make sure you have:
- An AWS account with permission to use Amazon Bedrock and Amazon RDS.
- Get the latest version of AWS Command Line Interface (AWS CLI), and Configure the AWS CLI.
- Enable Amazon Titan Text Embeddings V2 model with Amazon Bedrock access.
- Install Visual Studio (or your preferred .NET IDE).
- Install .NET 8.0 SDK .
- Install PgAdmin.
Set up .NET application with pgvector
This step-by-step guide demonstrates how to store, query, and search vector embeddings using AWS services. You can leverage pgvector on Amazon RDS for PostgreSQL to set up, operate, and scale databases for machine learning (ML) enabled applications. The pgvector extension is available on Amazon RDS PostgreSQL 15.2 and higher versions.
- Create a .NET app
- Generate Embeddings from plain text using Amazon Bedrock
- Provision database by creating Amazon RDS for PostgreSQL
- Enable pgvector for Vector Operations
- Store Embeddings in the PostgreSQL Database
- Implement Semantic Search on .NET application
Walkthrough
Step 1: Create a .NET app
The solution uses a .NET console application, but can be used with all .NET project types, including Windows Forms and Web Application Programming Interfaces (APIs). It demonstrates semantic search using movie descriptions to create embeddings. This process works with any text data, but for better processing accuracy, divide larger documents into smaller chunks.
1. Create a .NET 8 console app using Visual Studio. Select Do not use top-level statements.
2. Open the solution in your IDE, and add the following code in Program.cs file to define a list of movies.
private static readonly Dictionary<string, string> movies = new()
{
{"Avatar: The Way of Water", "Jake Sully and Neytiri must protect their family and Pandora when a familiar threat returns to finish what was previously started, forcing them to leave their home and explore new regions."},
{"Dune", "Set in a distant future, this sci-fi epic follows Paul Atreides, whose family accepts stewardship of the dangerous desert planet Arrakis, source of the most valuable substance in the universe – ‘the spice’."},
{"Top Gun: Maverick", "After more than thirty years of service, Pete ‘Maverick’ Mitchell returns to train a group of elite TOPGUN graduates for a specialized mission that demands the ultimate sacrifice."},
{"Everything Everywhere All at Once", "An aging Chinese immigrant is swept up in an insane adventure where she alone can save the world by exploring other universes connecting with the lives she could have led."},
{"The Batman", "In his second year of fighting crime, Batman uncovers corruption in Gotham City that connects to his own family while facing a serial killer known as the Riddler."},
{"Avengers: Endgame", "The epic conclusion to the Infinity Saga where the remaining Avengers must find a way to reverse Thanos’ actions and restore balance to the universe through a time heist."},
{"Oppenheimer", "A biographical thriller following J. Robert Oppenheimer, the theoretical physicist who led the Manhattan Project during World War II to develop the first nuclear weapons."},
{"Barbie", "Barbie and Ken’s journey from the perfect world of Barbieland into the real world explores themes of identity, feminism, and self-discovery in this imaginative comedy."},
{"Inception", "A skilled thief with the rare ability to ‘extract’ information from people’s minds while they dream must now attempt the impossible: inception – planting an idea into someone’s mind."},
{"Parasite", "A poor South Korean family infiltrates a wealthy household by posing as unrelated, highly qualified individuals, leading to an unexpected series of events."},
{"The Grand Budapest Hotel", "The adventures of a legendary hotel concierge and his trusted lobby boy in a fictional Eastern European country between the two World Wars."},
{"A Quiet Place", "In a post-apocalyptic world, a family is forced to live in silence while hiding from monsters with ultra-sensitive hearing that hunt by sound."},
{"La La Land", "A jazz pianist and an aspiring actress fall in love while pursuing their dreams in Los Angeles, but their success threatens to tear them apart."},
{"Mad Max: Fury Road", "In a post-apocalyptic wasteland, a woman rebels against a tyrannical ruler in search of her homeland with the aid of a group of female prisoners and a drifter named Max."},
{"Get Out", "A young African-American man visits his white girlfriend’s family estate and becomes ensnared in a more sinister reason for the invitation."}
};
Step 2: Generate Embeddings from plain text using Amazon Bedrock
Amazon Bedrock offers several embedding models from various providers. I will use Amazon Titan Text Embeddings V2 model to convert text into embeddings.
1. Install AWSSDK.BedrockRuntime NuGet package to the project. The package enables .NET application to interact with foundation models from Amazon Bedrock through a managed API client.
2. Add the following code in Program.cs to generate embeddings.
static async Task<float[]> GenerateEmbeddingAsync(string message)
{
var client = new AmazonBedrockRuntimeClient();
var modelId = "amazon.titan-embed-text-v2:0";
var bodyJson = new JsonObject
{
["inputText"] = message,
["dimensions"] = 256,
["normalize"] = true
};
var request = new InvokeModelRequest
{
ModelId = modelId,
Body = AWSSDKUtils.GenerateMemoryStreamFromString(bodyJson.ToJsonString())
};
var response = await client.InvokeModelAsync(request);
if (response != null && response.HttpStatusCode == HttpStatusCode.OK)
{
var contentJson = await JsonNode.ParseAsync(response.Body);
var embedding = contentJson?["embedding"].AsArray();
if (embedding != null)
{
return JsonSerializer.Deserialize<float[]>(contentJson["embedding"]);
}
}
return Array.Empty<float>();
}
The GenerateEmbeddingAsync method creates vector embeddings from input text using the TitanEmbedTextV2Model through AmazonBedrockRuntimeClient. The model accepts the following parameters:
inputText– To convert text into embeddingsdimensions– The following values are accepted as dimensions for output embeddings: 1024 (default), 512, 256.normalize– Controls embedding normalization (defaults to true)
3. Add the following code to the Main method in Program.cs.
static async Task Main(string[] args)
{
foreach (var movie in movies)
{
var embeddings = await GenerateEmbeddingAsync(movie.Value);
Console.WriteLine($"{movie.Key}, Embedding {embeddings[0]}…{embeddings[255]}");
}
}
After running the .NET application, vector embeddings are generated for each movie.
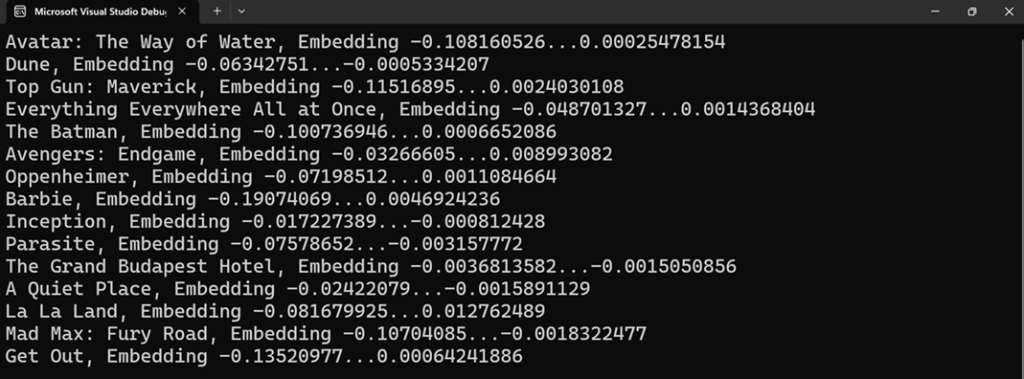
Figure 2: Vector embedding in .NET application
Step 3: Provision database by creating Amazon RDS for PostgreSQL
Create an Amazon RDS for PostgreSQL instance to handle vector operations. Amazon RDS provides scalable storage and querying capabilities with automated maintenance, backups, and security updates.
1. Create Amazon RDS for PostgreSQL instance by following steps: Creating and connecting to a PostgreSQL DB instance .
2. Connect to PostgreSQL using pgAdmin by following steps: Connecting to a PostgreSQL DB instance using pgAdmin.
3. Install pgvector extension on the self-managed PostgreSQL as an alternate to Amazon RDS for PostgreSQL.
Step 4: Enable pgvector for Vector Operations
Amazon RDS and Amazon Aurora for PostgreSQL include pre-installed PostgreSQL extensions by default.
1. To enable pgvector on PostgreSQL database, execute the following command using the PSQL tool :
CREATE EXTENSION vector;
2. Use following command to create a new table with a vector type column.
CREATE TABLE movies(
id SERIAL PRIMARY KEY,
name VARCHAR(50),
description TEXT,
vector_description vector(256)
);
This creates a movies table with vector_description column storing 256-dimensional vectors. The dimension value (256) must match the embedding size specified when generating embeddings in Step 2.
Vector dimensions affect semantic search performance. Higher dimensions provide better semantic search accuracy, but consume more storage space and require longer processing time. Lower dimensions process faster but may reduce search accuracy. The choice of dimensions depends on balancing your performance requirements with search precision needs.
Step 5: Store Embeddings in the PostgreSQL Database
The Pgvector.EntityFrameworkCore NuGet package enables PostgreSQL vector data type support in .NET applications. With this package, developers can define vector properties in EF Core entity models that map to the corresponding vector data type column in PostgreSQL. The integration provides seamless storage and retrieval of vector data within .NET applications, eliminating the need to handle low-level PostgreSQL implementation details.
1. Install Pgvector.EntityFrameworkCore NuGet package.
2. Create a new file named Movie.cs in your project to define the entity model:
[Table("movies")]
public class Movie
{
[Column("id")]
public int Id { get; set; }
[Column("name")]
public string Name { get; set; }
[Column("description")]
public string Description { get; set; }
[Column("vector_description", TypeName = "vector(256)")]
public Vector VectorDescription { get; set; }
}
3. Create a new file named MovieContext.cs in your project and define a DbContext class:
public class MovieContext : DbContext
{
public MovieContext(DbContextOptions<MovieContext> options)
: base(options)
{
}
public DbSet<Movie> Movies { get; set; }
protected override void OnModelCreating(ModelBuilder modelBuilder)
{
base.OnModelCreating(modelBuilder);
modelBuilder.HasPostgresExtension("vector");
}
}
4. Configure the database connection string in DbContext to establish database connectivity. It is recommended to store the connection string externally. To keep application simple, define the connection string in the Program.cs file and replace placeholders <endpoint> and <password> with your Amazon RDS for PostgreSQL endpoint and password, respectively.
static string connectionstring = "Server=<endpoint>;Port=5432;Database=postgres;User Id=postgres;Password=<password>;";
// Initialize database context with vector support
static MovieContext movieContext = new MovieContext(
new DbContextOptionsBuilder<MovieContext>()
.UseNpgsql(connectionstring, options => options.UseVector())
.Options);
5. Add the following code in Program.cs to store movies and their embeddings:
static async Task IngestMovies()
{
foreach (var movie in movies)
{
// Generate embeddings for movie description
var embeddings = await GenerateEmbeddingAsync(movie.Value);
Console.WriteLine($"Movie {movie.Key}, Embedding {embeddings[0]}...{embeddings[255]}");
// Create new movie entry with embeddings
await movieContext.Movies.AddAsync(new Movie
{
Name = movie.Key,
Description = movie.Value,
VectorDescription = new Vector(embeddings)
});
}
// Save all changes to database
await movieContext.SaveChangesAsync();
}
6. Update the Main method with the following code in Program.cs:
static async Task Main(string[] args)
{
await IngestMovies();
}
After running the .NET application, verify the data ingestion by executing following SELECT query in PgAdmin:
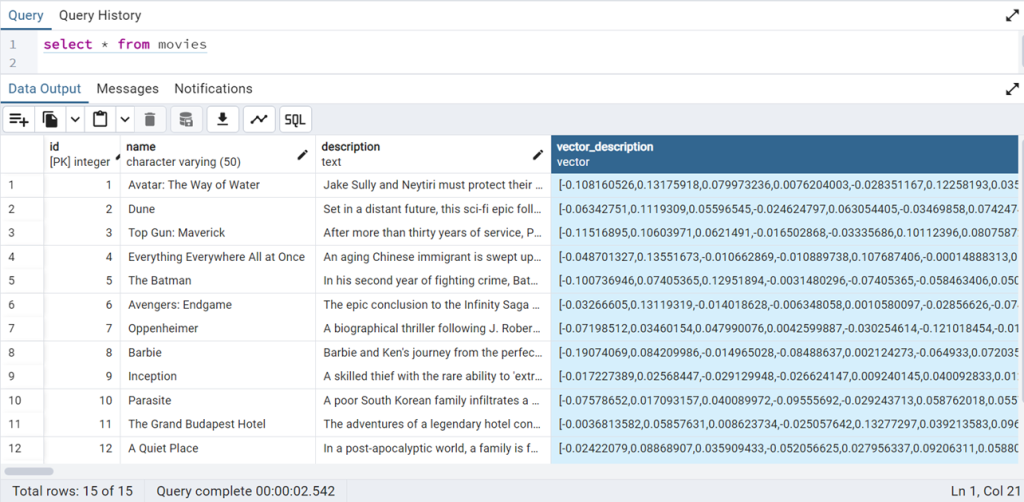
Figure 3: Vector embedding in PostgreSQL Database
Step 6: Implement Semantic Search on .NET application
Implementing semantic search in .NET applications involves two key steps: first, the embedding model converts search query (plain text) into a vector embedding, then use pgvector Entity Framework Core to calculate cosine distance and find the nearest neighbours.
1. Add the following code in Program.cs to find semantic similar movies with distance:
static async Task GetMovies(string searchQuery)
{
Console.WriteLine($"Search query:- {searchQuery}");
// Convert search query to vector embedding
var searchEmbedding = await GenerateEmbeddingAsync(searchQuery);
// Find nearest neighbors using cosine distance
var vector_embedding = new Vector(searchEmbedding);
var movies = await movieContext.Movies
.OrderBy(x => x.VectorDescription.CosineDistance(vector_embedding))
.Select(x => new { Entity = x, Distance = x.VectorDescription.CosineDistance(vector_embedding) })
.ToListAsync();
// Display results
foreach (var movie in movies)
{
Console.WriteLine($"{movie.Entity.Name} (Distance: {movie.Distance})");
Console.WriteLine(movie.Entity.Description);
Console.WriteLine();
}
}
Cosine similarity is a popular technique for finding semantic similarity, particularly in natural language processing and information retrieval. It measures the cosine of the angle between two vectors in a multi-dimensional space.
2. Update the Main method with the following code to test semantic search:
static async Task Main(string[] args)
{
var searchQuery = args.Length> 0 ? args[0] : "A movie suitable for the whole family, including children";
await GetMovies(searchQuery);
}
Launch the application from Visual Studio, or enter the following command in the terminal:
dotnet run -- "a movie suitable for the whole family, including children"
After running the .NET application, it displays the semantically similar movies, ordered by their cosine distance. Lower distance values indicate higher similarity to search query. Try your own queries.
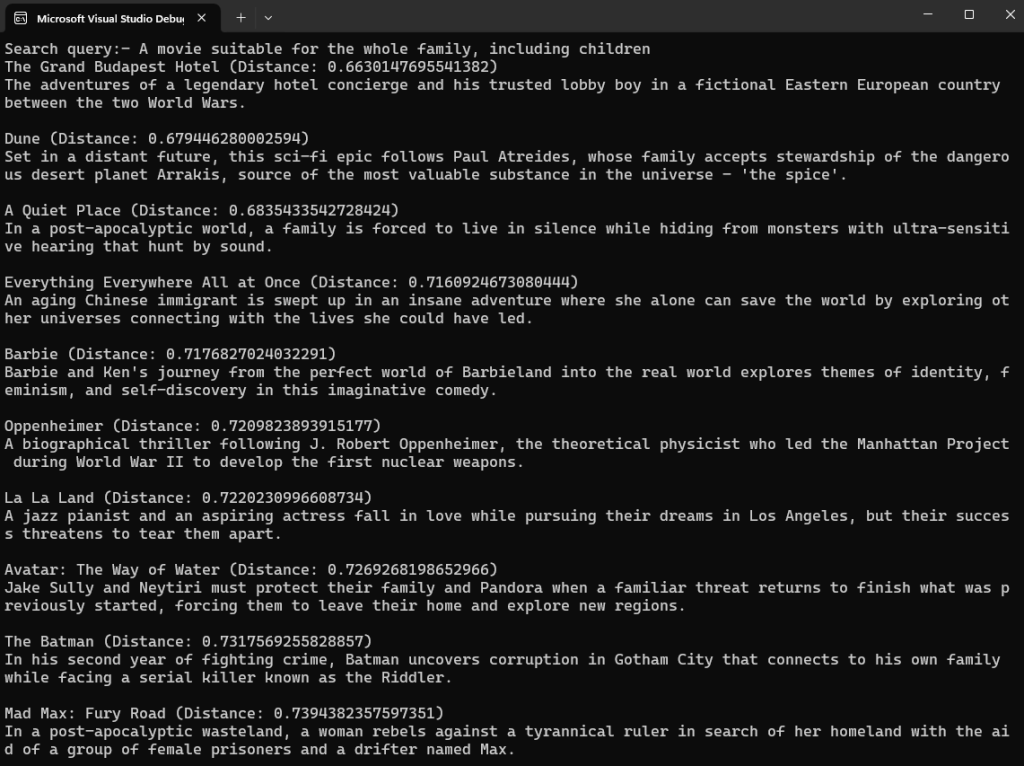
Figure 4: .NET application semantic search output
Step 7 (optional): Index Vector Data
In addition to the previous steps, users can create vector indexes to improve read performance from large datasets. Vector indexes are specialized data structures that optimize storage and retrieval of high-dimensional vector data, which is crucial for semantic search applications. pgvector offers two modes for nearest neighbor search: exact (default) and approximate. The exact search returns all relevant results with complete accuracy, while the approximate nearest neighbor search offers faster performance by using dedicated indexes like HNSW and IVF FLAT.
Create an index using either method:
-- HNSW Index
CREATE INDEX ON movies USING hnsw (vector_description vector_cosine_ops);
-- or IVF FLAT Index
CREATE INDEX ON movies USING ivfflat (vector_description vector_cosine_ops);
Clean-up
Clean up the resources that were created for the sample application to avoid incurring charges. If the foundational model is no longer needed, refer to Add or remove access to Amazon Bedrock foundation models and follow the steps to remove the model access. Delete the Amazon RDS for PostgreSQL database to avoid incurring charges, follow the instructions in the Amazon RDS User Guide: Deleting a DB Instance.
Conclusion
In this post, you learned how to build a semantic search application using Amazon Bedrock and Amazon RDS for PostgreSQL in .NET. PostgreSQL was chosen as the database solution because the enterprise applications majorly use relational databases, and it extends traditional database capabilities with vector operations. This approach adds semantic search functionality to the existing applications while leveraging familiar PostgreSQL features. I encourage you to explore building your own semantic search applications. Refer to supported foundation models in Amazon Bedrock and AWS Vector Database solutions to find the best fit for your semantic search needs.