What are Embeddings in Machine Learning?
What are embeddings in machine learning?
Embeddings are numerical representations of real-world objects that machine learning (ML) and artificial intelligence (AI) systems use to understand complex knowledge domains like humans do. As an example, computing algorithms understand that the difference between 2 and 3 is 1, indicating a close relationship between 2 and 3 as compared to 2 and 100. However, real-world data includes more complex relationships. For example, a bird-nest and a lion-den are analogous pairs, while day-night are opposite terms. Embeddings convert real-world objects into complex mathematical representations that capture inherent properties and relationships between real-world data. The entire process is automated, with AI systems self-creating embeddings during training and using them as needed to complete new tasks.
Why are embeddings important?
Embeddings enable deep-learning models to understand real-world data domains more effectively. They simplify how real-world data is represented while retaining the semantic and syntactic relationships. This allows machine learning algorithms to extract and process complex data types and enable innovative AI applications. The following sections describe some important factors.
Reduce data dimensionality
Data scientists use embeddings to represent high-dimensional data in a low-dimensional space. In data science, the term dimension typically refers to a feature or attribute of the data. Higher-dimensional data in AI refers to datasets with many features or attributes that define each data point. This can mean tens, hundreds, or even thousands of dimensions. For example, an image can be considered high-dimensional data because each pixel color value is a separate dimension.
When presented with high-dimensional data, deep-learning models require more computational power and time to learn, analyze, and infer accurately. Embeddings reduce the number of dimensions by identifying commonalities and patterns between various features. This consequently reduces the computing resources and time required to process raw data.
Train large language models
Embeddings improve data quality when training large language models (LLMs). For example, data scientists use embeddings to clean the training data from irregularities affecting model learning. ML engineers can also repurpose pre-trained models by adding new embeddings for transfer learning, which requires refining the foundational model with new datasets. With embeddings, engineers can fine-tune a model for custom datasets from the real world.
Build innovative applications
Embeddings enable new deep learning and generative artificial intelligence (generative AI) applications. Different embedding techniques applied in neural network architecture allow accurate AI models to be developed, trained, and deployed in various fields and applications. For example:
- With image embeddings, engineers can build high-precision computer vision applications for object detection, image recognition, and other visual-related tasks.
- With word embeddings, natural language processing software can more accurately understand the context and relationships of words.
- Graph embeddings extract and categorize related information from interconnected nodes to support network analysis.
Computer vision models, AI chatbots, and AI recommender systems all use embeddings to complete complex tasks that mimic human intelligence.
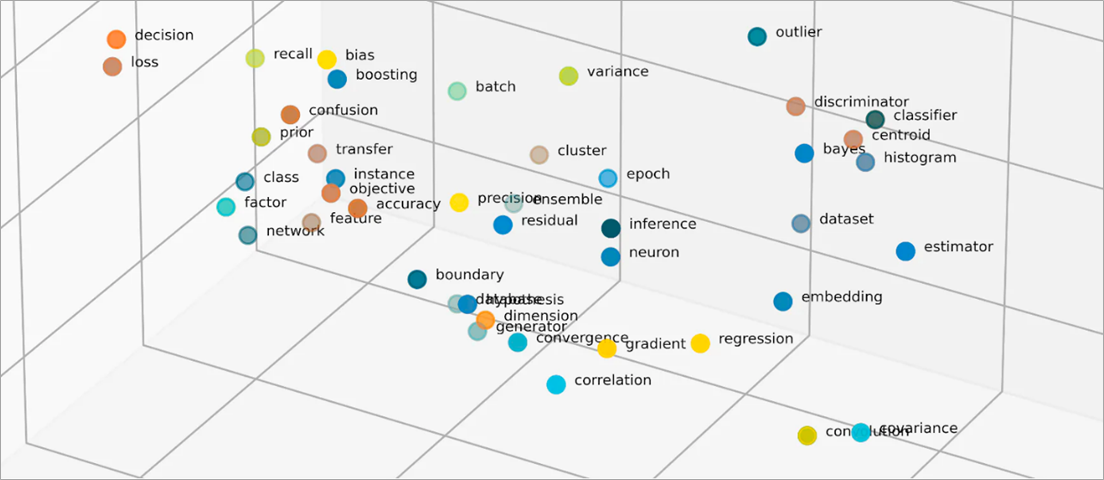
What are vectors in embeddings?
ML models cannot interpret information intelligibly in their raw format and require numerical data as input. They use neural network embeddings to convert real-word information into numerical representations called vectors. Vectors are numerical values that represent information in a multi-dimensional space. They help ML models to find similarities among sparsely distributed items.
Every object an ML model learns from has various characteristics or features. As a simple example, consider the following movies and TV shows. Each is characterized by the genre, type, and release year.
The Conference (Horror, 2023, Movie)
Upload (Comedy, 2023, TV Show, Season 3)
Tales from the Crypt (Horror, 1989, TV Show, Season 7)
Dream Scenario (Horror-Comedy, 2023, Movie)
ML models can interpret numerical variables like years, but cannot compare non-numerical ones like genre, types, episodes, and total seasons. Embedding vectors encode non-numerical data into a series of values that ML models can understand and relate. For example, the following is a hypothetical representation of the TV programs listed earlier.
The Conference (1.2, 2023, 20.0)
Upload (2.3, 2023, 35.5)
Tales from the Crypt (1.2, 1989, 36.7)
Dream Scenario (1.8, 2023, 20.0)
The first number in the vector corresponds to a specific genre. An ML model would find that The Conference and Tales from the Crypt share the same genre. Likewise, the model will find more relationships between Upload and Tales from the Crypt based on the third number, representing the format, seasons, and episodes. As more variables are introduced, you can refine the model to condense more information in a smaller vector space.
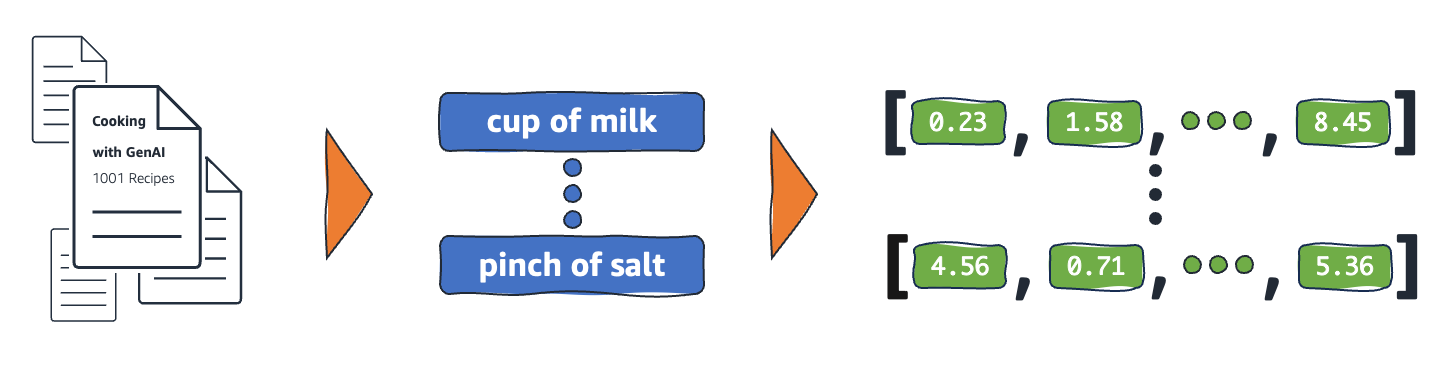
How do embeddings work?
Embeddings convert raw data into continuous values that ML models can interpret. Conventionally, ML models use one-hot encoding to map categorical variables into forms they can learn from. The encoding method divides each category into rows and columns and assigns them binary values. Consider the following categories of produce and their price.
|
Fruits |
Price |
|
Apple |
5.00 |
|
Orange |
7.00 |
|
Carrot |
10.00 |
Representing the values with one-hot encoding results in the following table.
|
Apple |
Orange |
Pear |
Price |
|
1 |
0 |
0 |
5.00 |
|
0 |
1 |
0 |
7.00 |
|
0 |
0 |
1 |
10.00 |
The table is represented mathematically as vectors [1,0,0,5.00], [0,1,0,7.00], and [0,0,1,10.00].
One-hot encoding expands dimensional values of 0 and 1 without providing information that helps models relate the different objects. For example, the model cannot find similarities between apple and orange despite being fruits, nor can it differentiate orange and carrot as fruits and vegetables. As more categories are added to the list, the encoding results in sparsely distributed variables with many empty values that consume enormous memory space.
Embeddings vectorize objects into a low-dimensional space by representing similarities between objects with numerical values. Neural network embeddings ensure that the number of dimensions remains manageable with expanding input features. Input features are traits of specific objects an ML algorithm is tasked to analyze. Dimensionality reduction allows embeddings to retain information that ML models use to find similarities and differences from input data. Data scientists can also visualize embeddings in a two-dimensional space to better understand the relationships of distributed objects.
What are embedding models?
Embedding models are algorithms trained to encapsulate information into dense representations in a multi-dimensional space. Data scientists use embedding models to enable ML models to comprehend and reason with high-dimensional data. These are common embedding models used in ML applications.
Principal component analysis
Principal component analysis (PCA) is a dimensionality-reduction technique that reduces complex data types into low-dimensional vectors. It finds data points with similarities and compresses them into embedding vectors that reflect the original data. While PCA allows models to process raw data more efficiently, information loss may occur during processing.
Singular value decomposition
Singular value decomposition (SVD) is an embedding model that transforms a matrix into its singular matrices. The resulting matrices retain the original information while allowing models to better comprehend the semantic relationships of the data they represent. Data scientists use SVD to enable various ML tasks, including image compression, text classification, and recommendation.
Word2Vec
Word2Vec is an ML algorithm trained to associate words and represent them in the embedding space. Data scientists feed the Word2Vec model with massive textual datasets to enable natural language understanding. The model finds similarities in words by considering their context and semantic relationships.
There are two variants of Word2Vec—Continuous Bag of Words (CBOW) and Skip-gram. CBOW allows the model to predict a word from the given context, while Skip-gram derives the context from a given word. While Word2Vec is an effective word embedding technique, it cannot accurately distinguish contextual differences of the same word used to imply different meanings.
BERT
BERT is a transformer-based language model trained with massive datasets to understand languages like humans do. Like Word2Vec, BERT can create word embeddings from input data it was trained with. Additionally, BERT can differentiate contextual meanings of words when applied to different phrases. For example, BERT creates different embeddings for ‘play’ as in “I went to a play” and “I like to play.”
How are embeddings created?
Engineers use neural networks to create embeddings. Neural networks consist of hidden neuron layers that make complex decisions iteratively. When creating embeddings, one of the hidden layers learns how to factorize input features into vectors. This occurs before feature processing layers. This process is supervised and guided by engineers with the following steps:
- Engineers feed the neural network with some vectorized samples prepared manually.
- The neural network learns from the patterns discovered in the sample and uses the knowledge to make accurate predictions from unseen data.
- Occasionally, engineers may need to fine-tune the model to ensure it distributes input features into the appropriate dimensional space.
- Over time, the embeddings operate independently, allowing the ML models to generate recommendations from the vectorized representations.
- Engineers continue to monitor the performance of the embedding and fine-tune with new data.
How can AWS help with your embedding requirements?
Amazon Bedrock is a fully-managed service that offers a choice of high-performing foundation models (FMs) from leading AI companies, along with a broad set of features to build generative artificial intelligence (generative AI) applications. Amazon Nova is a new generation of state-of-the-art (SOTA) foundation models (FMs) that deliver frontier intelligence and industry leading price-performance. They are powerful, general-purpose models built to support a variety of use cases. Use them as is or customize them with your own data.
Titan Embeddings is an LLM that translates text into a numerical representation. The Titan Embeddings model supports text retrieval, semantic similarity, and clustering. The maximum input text is 8K tokens and the maximum output vector length is 1536.
Machine learning teams can also use Amazon SageMaker to create embeddings. Amazon SageMaker is a hub wherein you can build, train, and deploy ML models in a secure and scalable environment. It provides an embedding technique called Object2Vec, with which engineers can vectorize high-dimensional data in a low-dimensional space. You can use the learned embeddings to compute relationships between objects for downstream tasks like classifications and regression.
Get started with embeddings on AWS by creating an account today.
Browse all cloud computing concepts
Browse all cloud computing concepts content here:
Did you find what you were looking for today?
Let us know so we can improve the quality of the content on our pages