AWS HPC Blog
High Burst CPU Compute for Monte Carlo Simulations on AWS
This post contributed by Dr. Leon Sucharov, Chief Technical Innovation Officer, and Adam Mitchell, Chief Innovation Architect, at Playtech.
Playtech is a leading supplier of online gaming and casino products. As part of the GPAS (Gaming Platform as A Service) Developer Programme Playtech provides game design and development tooling including the Ryota Maths Editor.
Introduction
Playtech mathematicians and game designers need accurate, detailed game play simulation results to create fun experiences for players.
While software developers have been able to iterate on code in an agile manner for many years, for non-analytical solutions, mathematicians have had to rely on slow CPU-bound Monte-Carlo simulations, waiting, as software engineers once did, many hours or overnight to get the results of their latest changes. These statistics are also required as evidence of game fairness in the highly regulated online gaming business.
Playtech has developed an AWS Lambda Serverless based solution that provides massive burst compute performance that allows game simulations in minutes rather than hours.
The Challenge
Monte-Carlo game simulation is a problem that is easily to parallelize. A typical simulation involves executing one billion independent game-plays and then requires aggregating the game results into a single set of statistical results.
Within Playtech we have two key users of the game simulation function. Game designers who want to tweak and iterate their game design, observing the impact of such changes on game play statistics. Game engineers who need to perform software updates and perform certification builds, validating each time that the game play is correct and generating statistics that can be used in documentation and sent to gaming regulators.
The initial, standard solution to executing a Monte-Carlo game simulation is to use a single server (either on-premises or an Amazon EC2 instance) and run a heavily multi-threaded simulation. A typical simulation might use 12 threads for 8 hours to deliver a simulation result — approximately 350K thread-seconds of execution.
This multi-hour execution time has several very significant downsides for our game designers and game engineers.
- The inability for game designers to iterate a design effectively.
- The inability for game engineers to perform game builds and generate sign-off stats in a timely manner.
- There are even more significant delays if more than one game designer / engineer wants to perform simulations concurrently.
It is also worth noting that one critical constraint is that the game logic code that is being simulated must be the exact same JVM code that we run in our production services. This is important as online gaming is a highly regulated industry and there is strict requirement to be able to show that the simulation results will exactly match those seen by real players in production.
The next challenge is that each simulation run must have deterministic results. It is important that when we re-run a simulation, we can determine whether or not a simulation execution is exactly the same as we would expect when performing maintenance releases.
The final challenge is that game engine development is a constant iterative activity. We thus require a continuous delivery function that will swiftly take game developer’s changes and build and deploy them to make them available for simulation execution in a matter of minutes.
We support many game development teams with many games in simultaneous development. We thus typically see over 100 game code updates a day and these often impact the code in our game engines (And thus our Lambda execution functions). It is also critically important from a QA and regulatory perspective that we know exactly which version of not just every execution component, but every orchestration and statistical analytical component is used on every simulation run.
The Solution
Monte Carlo Simulation has three distinct components to it:
- Simulation orchestration which controls the highly multi-threaded operations
- Individual sim execution and Individual result generation
- Results reduction
The above process can be thought of as a map-reduce activity with the map being the execution of a single (Or small batch) of sims, with the output of the map being the statistical results from the execution of those sims. The reduce is a reduction operation on the stats output.
The solution that we have developed is to use AWS Lambda for all three of the above operations with S3 to store the intermediate and final output API Gateway to control function execution versioning and Amazon CloudWatch for logging and cost monitoring.
AWS Lambda allows us to scale to thousands of executing threads in seconds and many more in minutes. A simulation that would take 50 hours on a single thread or several hours on a multicore machine can be executed in a few minutes.
It is not however possible to simply kick-off thousands of execution functions and have them write the results to a single location.
The Execution of a single simulation run therefore proceeds in four phases:
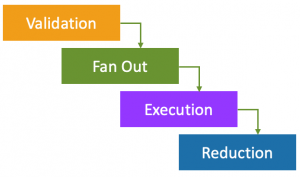
Figure 1. Highly Threaded Monte Carlo Simulation Execution Phases.
- Validation: This phase validates that the simulation is likely to complete in a reasonable time. Games with very slow code can cause very large cost impacts (see below).
- Fan Out: A single Initial Lambda function calls out to multiple Fan-Out functions that in turn call more, that eventually call the Simulation Execution functions.
- Simulation Execution: These Lambda Functions execute a small batch of Game Simulations (typically 10,000)
- Results Reduction : The final simulation state is to reduce the simulation output stats using a multi-stage reduction approach.
The Architecture
The validation is performed once per simulation to validate that the sim will execute in reasonable time. This includes both standard input data validation, and also the execution of 1000 simulations to confirm that they complete in a reasonable period of time (Our game simulation executions exhibit the well know computing problem that it is almost impossible to predict execution time of a model without executing it. We find the easiest way to predict poor behavior is to run a small sample.)
Upon completion of validation, the fan-out phase is initiated. Here a single fan-out function calls another function. In our case each fan-out calls up to 100 other Fan-Out functions, which in turn fan-out to 100 simulation Execution functions. We ensure that the simulation is deterministic by using an initial seed in our start function and then this seed to produce a new seed for each Fan-Out function each of these then does the same for the Execution function. Thus, the same input seed always produces the same results for the same configuration.
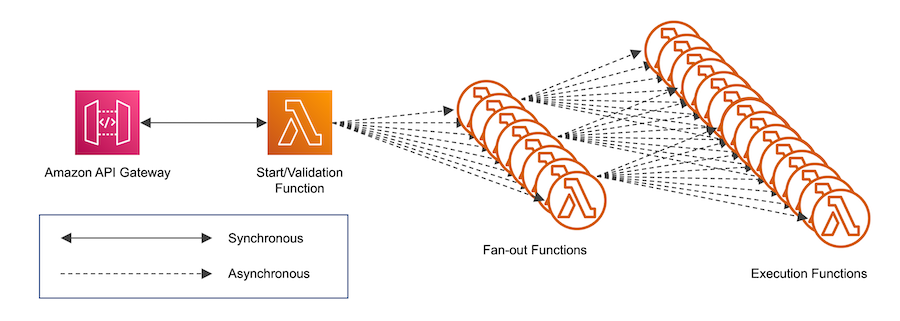
Figure 2: AWS Lambda Execution Initiation and Fan-Out
Each Execution function runs a small batch of game rounds (typically 10,000 to 100,000) and writes the statistical results of those rounds to Amazon S3.
The next stage is to perform the Reduction of the Execution function results into a single result (for a 1 billion game-round simulation, with 10,000 rounds per Execution invocation this is 100,000 results). This phase of course requires some synchronization with the Execution phase. We investigated several mechanisms for doing this, but found that the best was an external polling mechanism to pick up S3 results and reduce them iteratively until a final singular output is achieved.
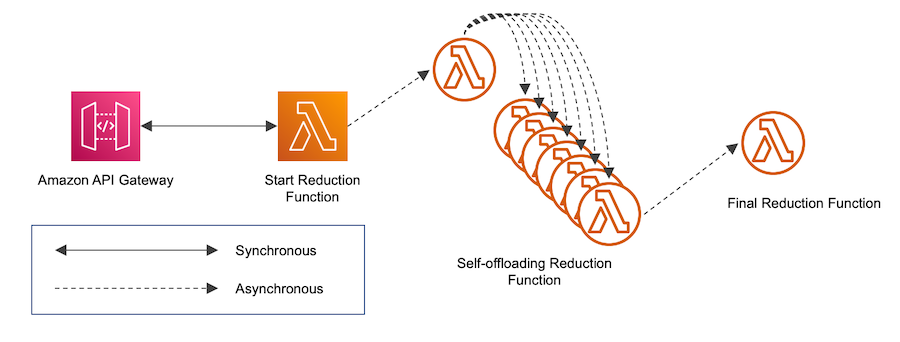
Figure 3: Reduction Phase
A single Reduction function is invoked. This function queries S3 to see how many results need to be reduced and then calls itself, delivering to each an S3 Continuation Token to indicate the result files to be handled, with the final function invoking the final reducer.
Performance
The following graph shows the number of concurrent Lambda Invocations by type for a 1,000,000,000 sim run with a batch size of 100,000, thus requiring 10,000 Execution invocations.
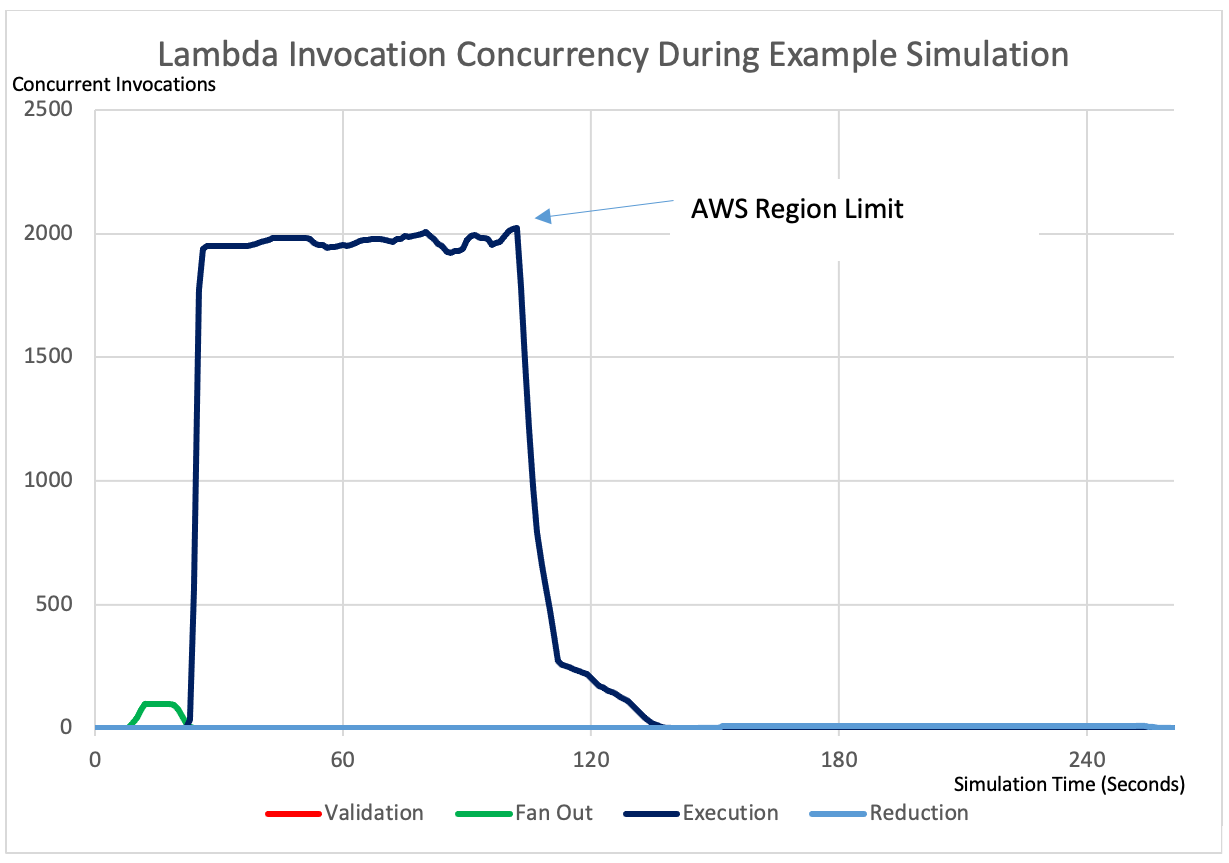
Figure 4: Lambda function invocation concurrency during example simulation run.
A comparison between Lambda and the previous EC2 Instance solution can be seen in the following table:
| Lambda Solution | EC2 Comparison* | |||
| Total Function Execution Time | Execution Time | Cost | Execution Time | Cost |
| 183 000 secs (51 hrs) | 4.5 mins | 3.09 USD | 109 mins | 4.16 USD |
* Running on a 72 Core EC2 Instance
Further Challenges
Cost Monitoring and Control
One of the biggest advantages of this approach also introduces a new business risk – cost. This solution delivers us massive burst CPU capacity for simulations consuming in a few minutes, CPU resources that would previously have been spread over many hours or days.
With great power comes great responsibility – we must ensure that a software bug, user error or a poorly designed game that has a very long running time does not run up very high AWS Costs extremely quickly (likely faster than our once-per-day billing reports).
We would also like to be able to ‘bill’ each of our game development units for the simulations that they run, so we would like to measure the cost for all the Lambda executions associated with a given simulation execution. This requires us to measure the total running time for these linked Lambda function executions.
We therefore needed a way to associate a simulation run id with the thousands of Lambda function invocations that corresponded to that run. We achieved writing the simulation id and the execution time to the Amazon CloudWatch Logs at the end of each function invocation. The following is an example of a structured data fragment written to CloudWatch Logs at the end of each Lambda function invocation:
{
"awsRequestId": "ca8414b7-f733-4a26-a468-a70900b3bf71",
"simulationRunId": "804e66d5-7d0e-4908-be18-b49b3d7ba5f0",
"duration": 54962,
"memoryLimitMB": 1040
}At the end of the simulation run we can then run a CloudWatch Insight Query to retrieve and sum the execution times, which we can then convert into a cost per simulation run. Here is an example of a CloudWatch Insight Query to sum execution time for a specific simulation run:
fields simulationRunId, duration, memoryLimitMB
| filter simulationRunId = "804e66d5-7d0e-4908-be18-b49b3d7ba5f0"
| stats count(simulationRunId),sum(duration*memoryLimitMB)Note that CloudWatch stats are delivered asynchronously, and it can take several minutes for them to become available. This means that the cost evaluation is good for completed simulations but is not very useful in terms of predicting if in-progress simulations are likely to be expensive. We thus sample the execution times of a small number of Execution functions to provide a real-time estimate.
Conclusion
This use of AWS Lambda has given Playtech tremendous business advantage over the previous on-premises / EC2 cloud solutions.
The biggest benefit is the ability for our creative game designers to iterate their designs in a few minutes rather than many hours. This is not only a huge time saving, but also allows our designers to refine their games to make much more enjoyable and engaging player experiences.
The second advantage is that this solution offers a huge cost saving. The alternative would be EC2 instances waiting to run simulations, but spending most of their time idle, a large waste and even then the maximum simulation throughput would be a fraction of what we achieve with AWS Lambda, and likely result in simulation-execution queues. EC2 Auto Scaling would help a little, but not much here given the ramp up time.
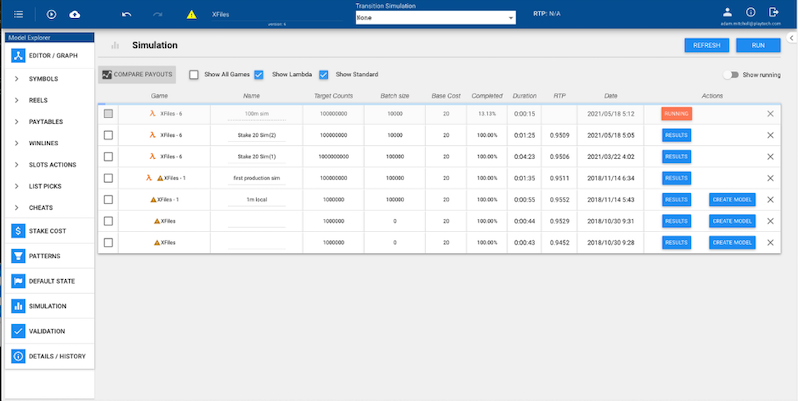
Figure 5: Playtech Ryota Maths Design Tool showing Several AWS Lambda Simulations Runs in Progress
Overall, this solution has been business changing for the way that we deliver game maths solutions at Playtech, allowing us to deliver better games, in much shorter timescales at lower cost.
The content and opinions in this blog are those of the third-party author and AWS is not responsible for the content or accuracy of this blog.