AWS HPC Blog
How Daiichi Sankyo modernized drug discovery using AWS Parallel Computing Service
 This blog was co-authored by Takehiro Nakajima and Mark Azadpour from AWS and Rintaro Yamada, Rei Kajitani and Ryo Kunimoto from Daiichi Sankyo
This blog was co-authored by Takehiro Nakajima and Mark Azadpour from AWS and Rintaro Yamada, Rei Kajitani and Ryo Kunimoto from Daiichi Sankyo
In recent years, the informatics field of drug discovery has seen a rapid increase in workloads requiring large-scale parallel computing, such as genome analysis, structure prediction, and drug design. Daiichi Sankyo has previously leveraged AWS ParallelCluster to build and operate their HPC environments. This helped them achieve greater efficiency and acceleration of their research. This environment has contributed significantly to realizing data-driven drug discovery by focusing on drug candidate design efforts in pharmaceutical research.
However, the continuous operation of HPC environments involves maintenance tasks such as troubleshooting and configuration management. These require specialized skills and know-how from personnel, sometimes leading to person-dependent operations. These kinds of working structures can hinder knowledge transfer and team-wide utilization, and they create challenges for future scalability.
Against this background, they ran a pilot with AWS Parallel Computing Service (AWS PCS), a relatively new managed service, with the aim to operate stably and flexibly, maintaining high utilization with less effort by both administrators and users. This is now their production environment.
This post introduces the architecture they adopted, and shares insights into PCS usability and operational aspects gained through their modernization efforts.
AWS architecture preview
Let’s look at the modernized AWS architecture Daiichi Sankyo adopted for their cloud environment for drug discovery research.
They built their HPC cluster environment for data scientists using PCS and several additional AWS services to streamline cluster operations. (Figure 1)
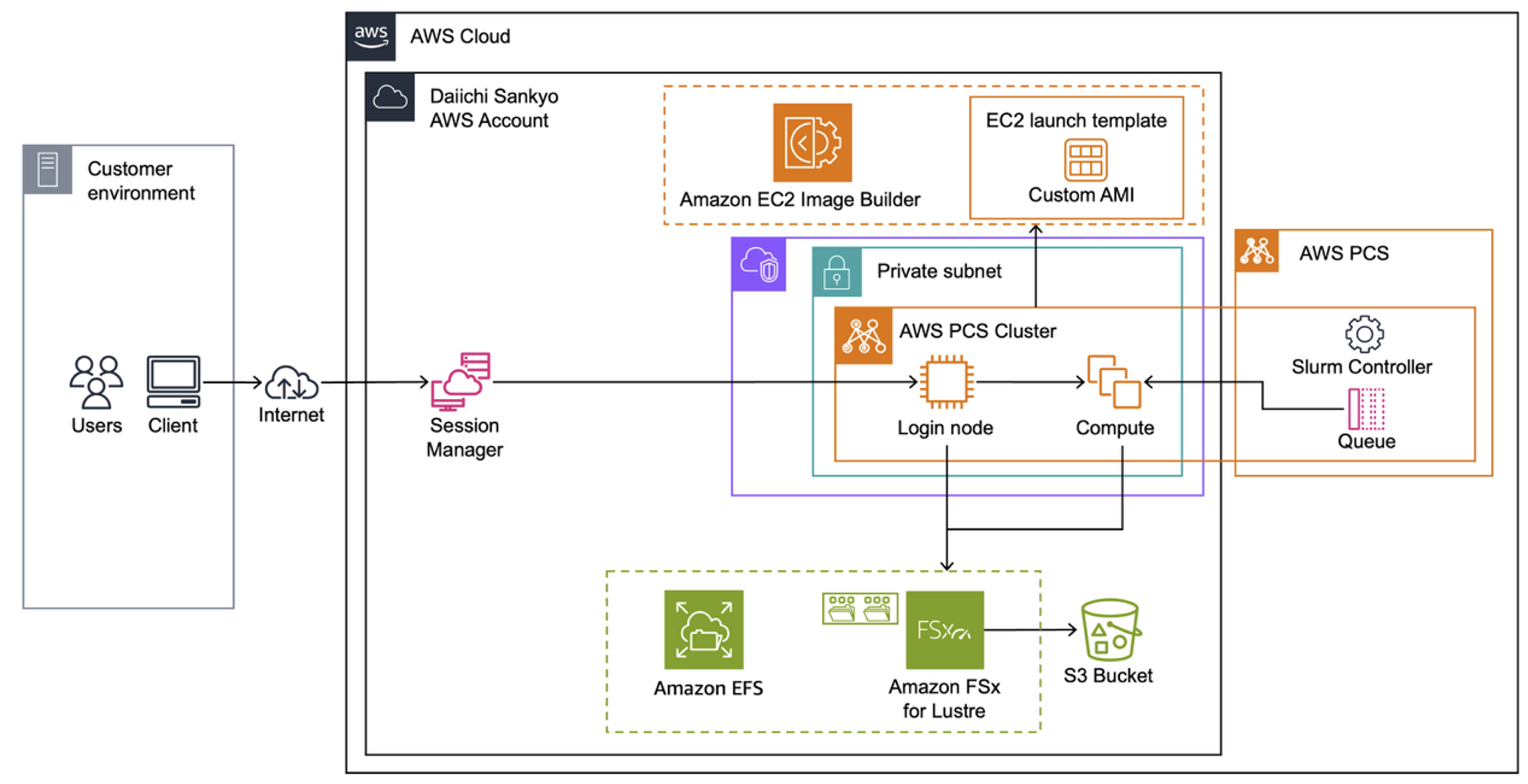
Figure 1 – HPC architecture with AWS PCS
Introducing AWS Parallel Computing Service
PCS is a managed service that uses Slurm as a job scheduler to facilitate the execution of HPC workloads on Amazon Elastic Compute Cloud (Amazon EC2). Using PCS, you can build an integrated environment that combines compute, storage, networking, and even visualization using Amazon DCV.
Customers already familiar with AWS ParallelCluster can create similar clusters in their VPC as before and use the same storage services like Amazon EFS, Amazon FSx for Lustre, and Amazon Simple Storage Service (Amazon S3).
PCS automates cluster management functions like Slurm version upgrades to reduce admin burden, allowing customers to focus more on research. Administrators can create and modify clusters through the AWS console, using APIs, or SDKs. End-users can access their clusters through familiar interfaces like SSH or AWS Systems Manager (SSM) to run jobs using Slurm.
Streamlining HPC cluster operations
A lot of tasks go into continuously operating HPC clusters, including OS version upgrades, package installation, file system mounting, and Linux user/group creation.
The team examined how to streamline each of these processes using various AWS managed services.
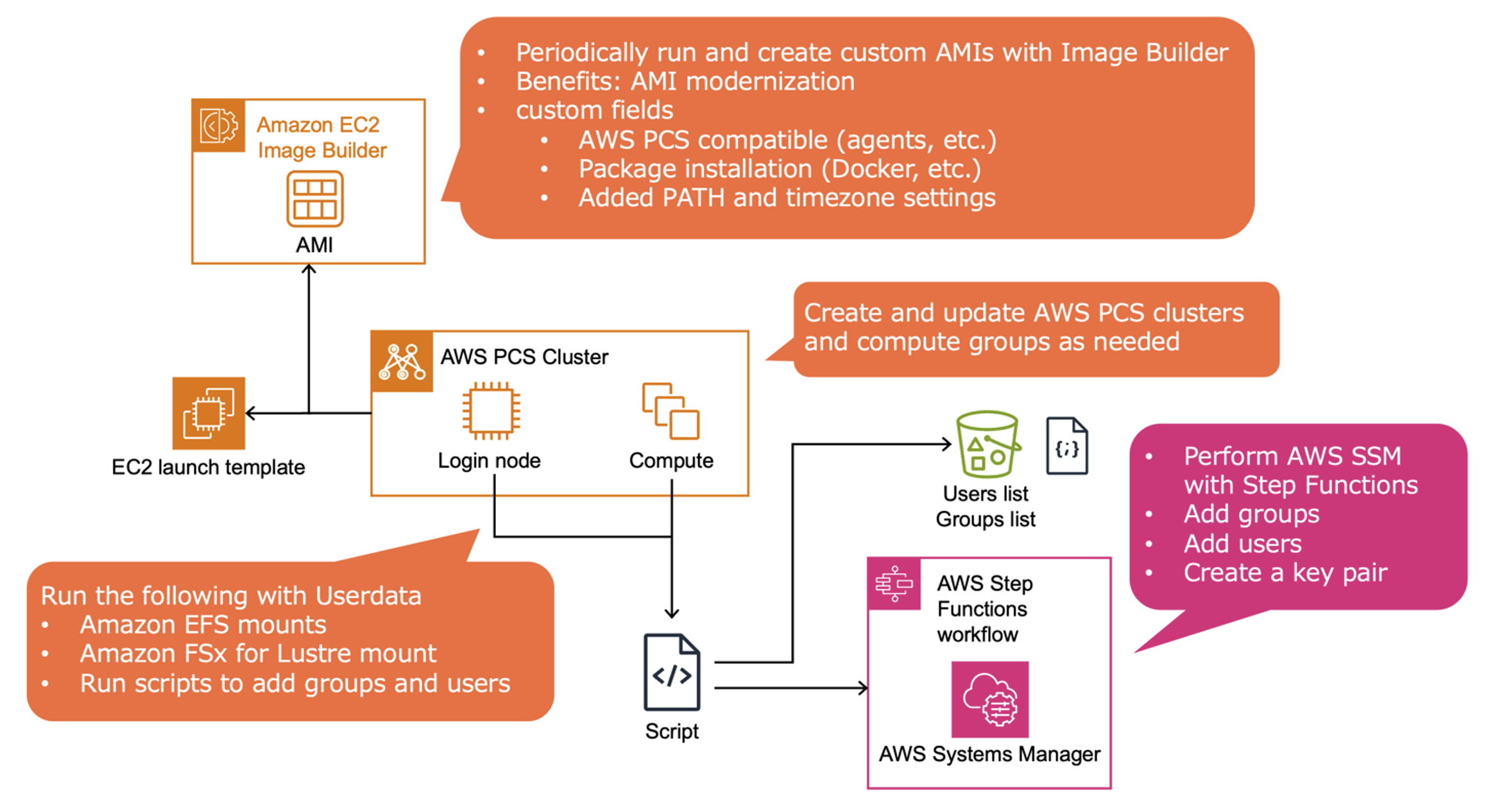
Figure 2 – Automate settings necessary for users to start using the HPC environment
Creating Custom AMIs
Unlike ParallelCluster, PCS does not provide a pre-defined “golden image”. Instead, customers are free to bring their own Amazon Machine Images (AMIs) to their PCS cluster. These can be the outputs from continuous integration (CI) pipelines, which will help you decide how you wish to keep your operating images up to date, and at what frequency. EC2 Image Builder is a fully managed service that enables custom AMI creation, management, and deployment automation.
Making your own AMIs used in PCS requires the installation of some PCS agents, a Slurm package, and some other components. Of course, you’ll need to install your own application packages too. You can accomplish this by using the same CI pipelines.
Your AMIs become the basis for launching Amazon EC2 instances. Image Builder allows you to define package installation and configuration commands as components, then combine necessary components into a recipe.
Daiichi Sankyo created recipes containing essential components for PCS and necessary components for their users. Rather than starting from a blank slate, they used recipes from the HPC Recipe Library as a starting point. This is a collection of recipe samples for HPC stacks from the simple to the complex and is available on GitHub.
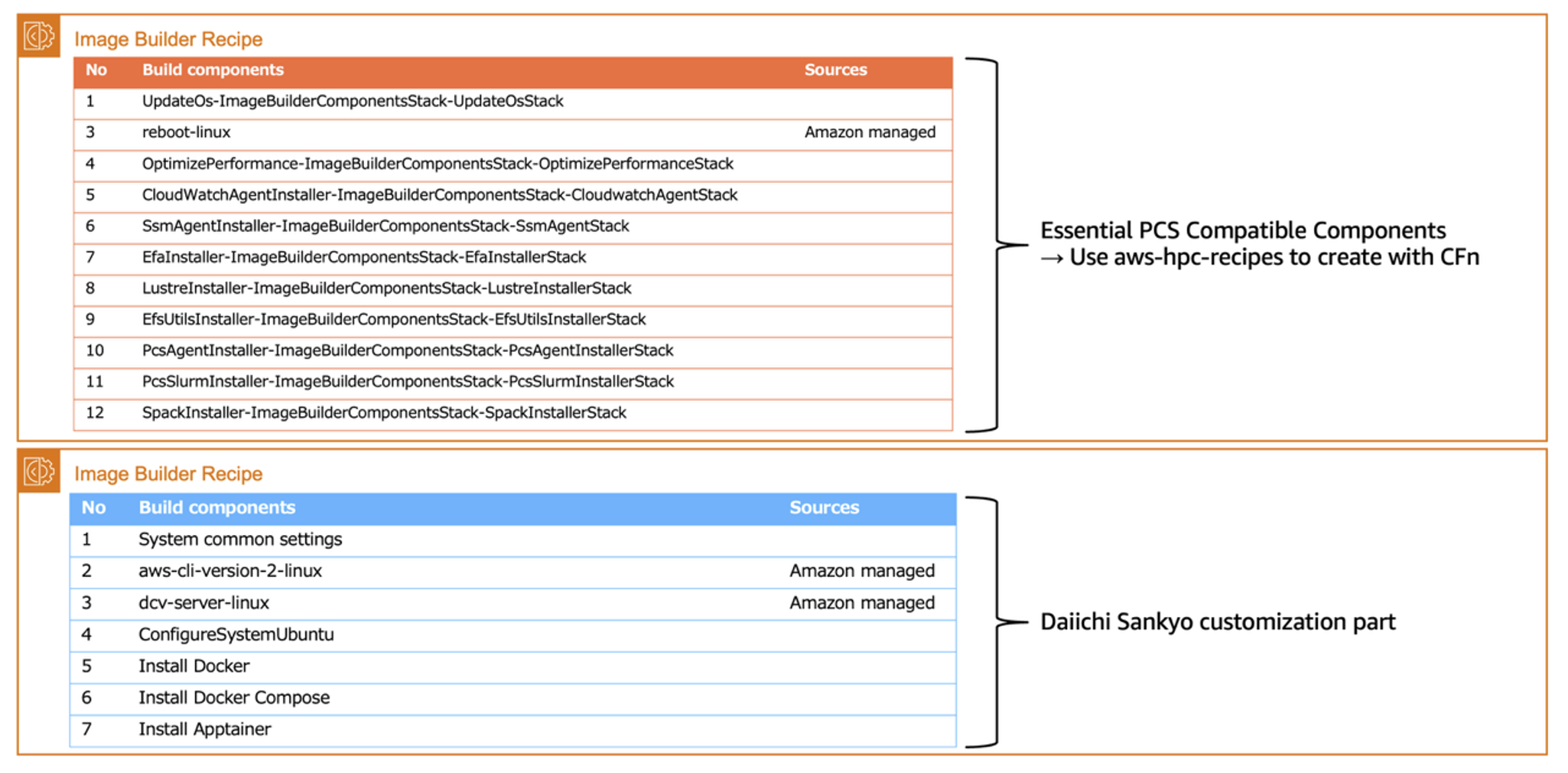
Figure 3 – Image Builder Recipe components
Automating Linux user and group management
They can automate user and group management in Linux using JSON-formatted user data, AWS Step Functions, and SSM Documents written in in JSON or YAML format that define actions of SSM on managed nodes.

Figure 4 – Automating Linux Groups and Users Settings Using AWS Step Functions and SSM
When login nodes or computing nodes start up within a PCS cluster, they execute user data scripts defined in the EC2 launch template. This includes shell scripts for mounting file systems and user and group creation and addition. These shell scripts read user information from JSON files as input data and pass them as parameters when executing the AWS Step Functions State Machine for user creation. AWS Step Functions is a fully managed AWS workflow service that enables automation and orchestration of various workloads defined as State Machines for large-scale execution.
In this implementation, Daiichi Sankyo used another managed service, SSM Documents, to document OS commands for Linux user/group creation and addition. They then call these SSM Documents when executing SSM Send commands within the State Machine to execute OS commands. These tasks are executed automatically, allowing users immediate access to a job-ready HPC environment.
Operational benefits and challenges
Management automation and configuration simplicity
The trigger for considering PCS adoption was Daiichi Sankyo’s need to lower the burden on the administrator who handled almost all HPC management and maintenance functions across departments.
They began evaluation of PCS by evaluating whether they could enable a smooth transition even for staff with limited cloud management experience. Their architecture based on PCS offered several advantages in terms of managing configurations and automating deployments compared to AWS ParallelCluster.
Configuration management included node instance types and quantities, file systems to mount, software to install, and OS types. ParallelCluster requires knowledge of command-line operations and SSH connections during configuration. Most of its tasks can’t be done from the AWS Console. In contrast, PCS allows most operations to be performed through the console, providing a consistent UI for easier management. That means there’s no need to master complex management tasks, enabling smooth handover even to less experienced personnel. Combined with automated user account provisioning and deployment through Step Functions, maintenance and operational burdens were further reduced.
Requirements in research departments and AWS PCS benefits
Research departments often have small, but many teams based on their specialties, each with somewhat unique HPC needs. Requirements can be diverse, too, stretching from groups needing lots of GPUs for machine learning and image processing, to those who emphasize storage for handling large data.
In exploratory research, it’s difficult for users to estimate in advance what scale of computational resources they need. That makes HPC environment rebuilds frequent. The new architecture enables automated deployment, allowing smooth operation and updates even for groups without AWS service experts. That’s a significant attraction. For example, in the genomics field, it’s not rare that single study handles DNA-sequence data from hundreds of people. They expect a cycle of deploying environments with large-scale, high-speed storage for these analyses, then stopping resources post-analysis to control costs. Recently, research using long-read sequencing, which can generate vastly more data than short-read sequencing, has become active in their teams. They achieved important results in their research that they couldn’t have accomplished without cloud computing environments.
AWS PCS may in fact maximize its management cost reduction effects when used by large research departments. Daiichi Sankyo concluded that PCS offers significant advantages particularly in eliminating person-dependent management and reducing educational costs through simplified operational procedures.
Operational and cost balance
Previously, Daiichi Sankyo operated four clusters (using ParallelCluster) for over 15 researchers using person-dependent management. This system required cluster administrators to respond flexibly and immediately to diverse requests from researchers. Moreover, they frequently encountered issues related to Slurm and file systems, spending considerable time and effort on troubleshooting.
In contrast, PCS not only eliminated operational costs of Slurm but also excelled in failure recovery performance, achieving significant efficiency improvements compared to traditional person-dependent approaches. PCS is a managed service while ParallelCluster is not. PCS has usage-based charges, prompting a broader analysis before use. However, they determined that they gained sufficient value, as we’ve discussed, that made the cost worthwhile.
Conclusion
Through this pilot, Daiichi Sankyo attempted HPC environment modernization with AWS Parallel Computing Service, to test the experience and benefits of fully managed HPC environments. PCS offers significant advantages in easier configuration and deployment compared to their traditional AWS ParallelCluster solutions. It’s user-friendly, even for those unfamiliar with cloud resource management.
Console-centric operability and smooth integration with custom AMIs and AWS Step Functions made reconstruction easier, contributing to eliminating dependency on people for maintenance tasks. The ability to flexibly switch configurations according to diverse research field requirements is extremely attractive in rapidly changing fields such as drug discovery.
Cost efficiency is impacted by controller fees and therefore, selecting appropriate cluster sizes and operational procedures is crucial for balancing costs with performance. Daiichi Sankyo decided that reducing operational management burden ultimately provided the greatest cost advantage to them.
Moving forward, they aim to maximize PCS flexibility and maintainability while exploring optimal HPC infrastructures according to changes in research needs. Through this, their goal is to establish a sustainable research support environment and gain even more performance and flexibility.