AWS HPC Blog
What’s the difference between AWS ParallelCluster and AWS Parallel Computing Service?
 It’s been a year since we announced AWS Parallel Computing Service (PCS). In a way this is the third generation of Slurm-based HPC orchestrators that we’ve brought to you. We’ve learned much from helping customers deploy serious production workloads on AWS ParallelCluster, which itself grew from the foundations layed by CfnCluster – the open-source project that started it all.
It’s been a year since we announced AWS Parallel Computing Service (PCS). In a way this is the third generation of Slurm-based HPC orchestrators that we’ve brought to you. We’ve learned much from helping customers deploy serious production workloads on AWS ParallelCluster, which itself grew from the foundations layed by CfnCluster – the open-source project that started it all.
Running a managed service is very different to shipping a product for self-hosting resources. Those differences are visible to both you and to us at the same time. As soon as we release a new feature for PCS, it’s available for everyone, everywhere. ParallelCluster is different in this respect. Since you use it to construct your clusters from a specification file, you manage the resulting cluster and all the attendant updates and upgrades. While AWS support is there to help when something breaks – there’s still a burden of ownership and some accrued technical debt you need to manage as we ship new releases of ParallelCluster.
Today I want to lay out the key differences between these two great ways of pursuing a cloud-enabled HPC experience. We’re continuing to develop ParallelCluster. While lots of customers continue to build this way, the feedback from many is that PCS is the product we arguably should have built many years ago. On the strength of that, it’s probably the one you should consider first.
But as with all things in HPC, the devil is in the details. Let’s discuss them.
First, the nomenclature
AWS Parallel Computing Service (PCS) is a managed high performance computing (HPC) environment that lets you run tightly coupled, large-scale simulations across many nodes with minimal infrastructure setup. AWS ParallelCluster is an open-source cluster management tool that automates the deployment and management of HPC clusters on AWS, giving you control and responsibility over configuration, scaling, and environment setup.
In case you’re wondering, we’re not forgetting AWS Batch – which is a container-based, cloud-native job scheduler service. But Batch is very much not a Slurm-based service, so we’ll leave a discussion about where it fits in for another post.
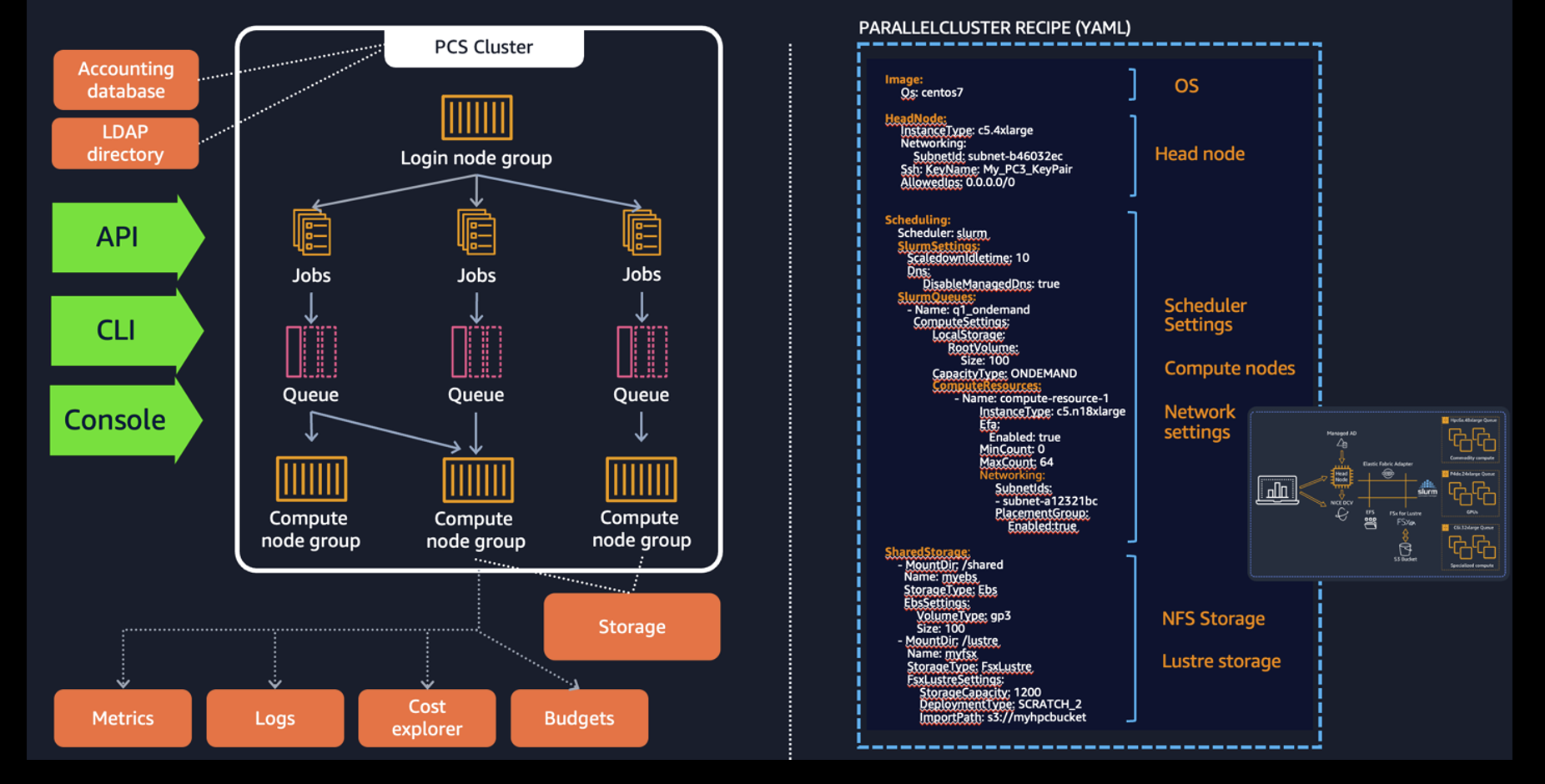
Figure 1: ParallelCluster and PCS are similar in that they both create Slurm-based clusters for you to deploy your code and workloads in, but they take different approaches. ParallelCluster (right) orchestrates a cluster on your behalf using instructions in a template you provide. You’re subsequently responsible for managing this instance of that cluster. PCS instantiates an environment for you, but manages th operations of the cluster afterwards, leaving you little maintenance to do.
Distribution and management
PCS is a fully managed AWS service. Updates, patching, and scaling are handled by AWS, just like with Amazon Elastic Container Service (ECS) or Amazon Relational Database Service (RDS). ParallelCluster, by contrast, is an open-source toolkit you download from GitHub. You install it, configure it, and own the lifecycle of both the version of the tool, and the clusters that you deploy using the CLI. That distinction alone sets the tone: PCS is cloud-native, ParallelCluster is self-managed.
This also affects the pace at which we can develop and deploy features. It’s just faster to add new capabilities to PCS. And when we ship them, they’re available to customers everywhere, immediately. ParallelCluster’s customers generally take some time to evaluate new features to see if they’re worth the effort (and cost – in time) of upgrading their existing clusters, since upgrade typically mean some data, application, and user migration.
If one of these new PCS features is almost, but not quite enough to solve a problem, we get feedback from customers sooner, which then feeds our iteration cycles, faster. The net result is that PCS will almost certainly converge on customers’ needs sooner than ParallelCluster can, given its deliberately longer upgrade cycles.
Interfaces and integration
PCS looks and feels like any other AWS service. It’s wired into the AWS Console, SDKs, CLI, CDK, and CloudFormation. You can spin up clusters with the same tools you use for EC2 or S3. ParallelCluster has its own CLI, and a UI that you install separately, which can feel like working in a parallel universe—powerful, but less integrated with the broader AWS ecosystem.
Region availability and support
PCS is being rolled out AWS Region by AWS Region, but wherever it’s available, it comes with full AWS support and service-level agreements. ParallelCluster can runs in a larger number of Regions, but it doesn’t come with a managed SLA. Support for ParallelCluster still comes from our support organization.
Use cases and trade-offs
If you’re a research lab or small team that wants to tinker, tweak, and fully control your HPC stack, ParallelCluster gives you that flexibility. You can dig into configs, swap components, and customize the stack extensively. But the operational tax is real—you patch, you upgrade, you troubleshoot. PCS flips that equation: you trade some of that low-level control for simplicity, guaranteed support, and integration into AWS’s broader service model.
Having said that, PCS still allows customization of Slurm settings, such as fair-share scheduling, quality of service levels, and access permissions. For example, PCS will let you implement queue-specific priority policies, configure preemption settings, and set custom time and resource limits. For access controls, you can set permissions at the account level and configure per-job execution behaviors.
Why all this matters
The difference isn’t academic. For production HPC workloads where uptime, compliance, and operational efficiency matter, PCS is the safer bet. It delivers “HPC as a service,” with AWS carrying the pager.
ParallelCluster, meanwhile, remains invaluable for experimentation, research, and custom environments where you need full, deep control and don’t mind rolling up your sleeves.
In short: PCS is HPC without the overhead; ParallelCluster is HPC with full manual control. Both get you to compute at scale, but the road you choose depends on whether you want AWS as your pit crew, or your own toolbox at the ready.
If this has made you curious to know more about PCS, I recommend you have a look at the AWS HPC Recipe Library. It contains several prepared one-click templates that build cluster architectures ranging from the simple to the ambitious. If any of them turn out close to what you need, you can download and tweak the recipes to suit your needs – skipping much of the learning curve. They’re TV dinners you can repurpose and pretend they’re your own gourmet productions. And no one will know.
Let us know how you get on.