AWS for Industries
Accelerating mainframe modernization: How Toyota Motor Europe (TME) uses Amazon Bedrock to automate legacy code documentation
Toyota Motor Europe NV/SA (TME) oversees the wholesale sales and marketing of Toyota, GR (GAZOO Racing), Lexus vehicles, parts and accessories, as well as Toyota’s European manufacturing and engineering operations. As part of their strategic Legacy Modernization program, TME is exploring the use of generative artificial intelligence (generative AI) to accelerate their mainframe migration efforts.
In partnership with Deloitte and AWS Generative AI Innovation Center (GenAIIC), TME built a proof of concept (PoC) using Amazon Bedrock and custom AI orchestration to automatically generate documentation from the source code of a legacy mainframe application for warranty handling. The automated and scalable pipeline translates legacy NCAR Command Language (NCL) code, the core programming language for NatStar, into natural language business and technical documentation. This solution enables TME to modernize decades-old systems while preserving institutional knowledge, improving business logic transparency, reducing migration risk, and establishing a reusable blueprint for future legacy modernization efforts.
The validated PoC has led to a production rollout, providing a foundational approach to documenting legacy codebases across TME’s enterprise modernization portfolio.
“The documentation generated has given us a comprehensive understanding of all the technical and business flows of one of our oldest legacy IT applications, offering a robust foundation for us to make informed decisions about modernizing this application,” shared Philip Rademakers, Technical Senior Manager at Toyota Motor Europe.
The challenge of mainframe modernization
As enterprises modernize their infrastructure, understanding and documenting legacy systems built with proprietary technologies remains a critical barrier—driven by scarce expertise, limited documentation, and the sheer scale of legacy codebases. TME manages more than 70 custom-built applications running on legacy mainframe and AS400 platforms, several of which are built using NCL code with limited or outdated documentation. The core warranty handling business application alone contains over 1.3 million lines of NCL code. As experienced NCL developers retire, TME also faces the risk of permanently losing embedded business logic. The challenge is compounded by the need for documentation serving multiple audiences: technical teams executing migration, business stakeholders validating functionality, and cross-functional teams coordinating the transition. Creating such multi-format documentation manually would require significant time and effort from an increasingly scarce pool of NCL experts.
Solution overview
To address the above challenges, TME partnered with Deloitte and AWS GenAIIC to build a PoC solution focused on 2 of the 10 modules in the warranty handling business application. The resulting AI-powered solution successfully generated comprehensive documentation for the legacy NCL code. Beyond the warranty handling business application, the solution establishes a reusable approach that can generate documentation for other NCL-based applications across TME’s enterprise, accelerating their broader modernization initiatives.
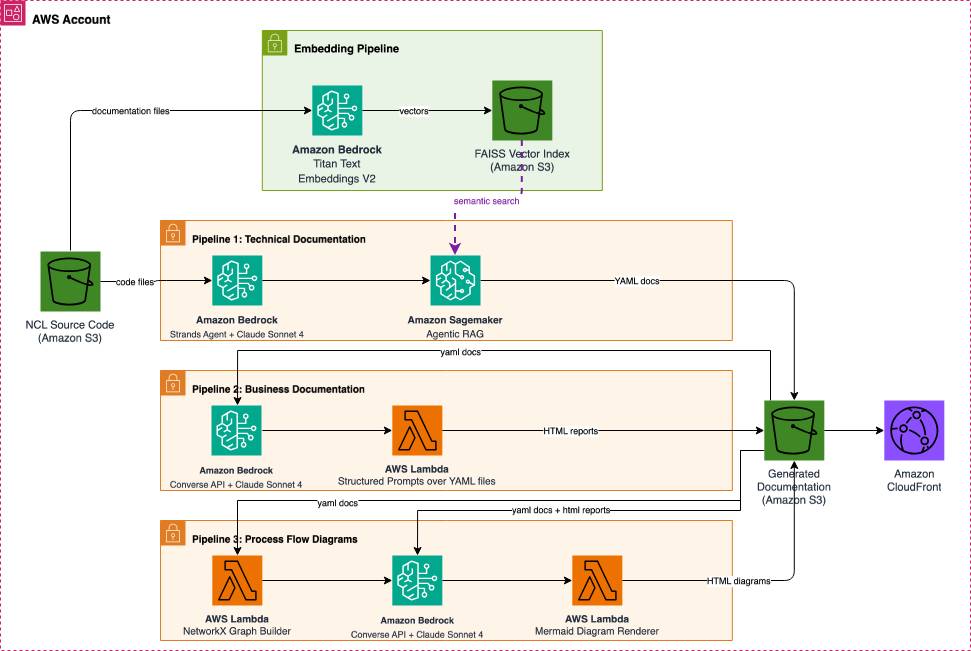
Figure 1: Solution architecture on AWS
The solution uses Amazon Bedrock, orchestrated through the Strands Agents SDK, an open-source framework developed by AWS for building production-ready AI agents. Strands Agents SDK was selected for its model-agnostic design, native AWS service integrations, seamless deployment capabilities, and future scalability with Amazon Bedrock AgentCore, AWS’s agentic platform for enterprise-scale agent operations.
Working with Deloitte and AWS GenAIIC, TME developed a solution that automatically generates multiple types of stakeholder-specific documentation from legacy NCL codebases:
- Technical Documentation helps developers understand the system architecture and prepare for migration. This type of documentation includes structured YAML specifications for each source file, including function purposes, arguments, outputs, dependencies, database queries, execution logic, and exception handling.
- Business Documentation Reports translate technical execution flows into accessible HTML documents that explain hierarchical process structures, business validation rules, database operations, and exception scenarios, enabling business stakeholders to validate system behavior without technical expertise. These reports also document processes in the same hierarchical structure as defined by the business, from L0 (process overview) to L3 (task-level steps).
- Process Flow Diagrams offer visual representations in two variants: technical diagrams showing detailed execution logic with color-coded nodes (actions, conditions, errors, database queries), and business-friendly versions that collapse implementation details while preserving decision points and validation rules, facilitating communication between technical and business teams. The process flows use a notation derived from NCL’s control flow structure—representing actions, conditions, and error handlers—rather than standard BPMN, mapping directly to how business logic is implemented in the source code.
The pipeline shows that technical documentation is generated from source files then converted into YAML files that enable parallel transformation into business reports and process diagrams.
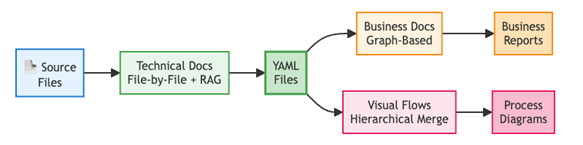 Figure 2: Multi-stage documentation generation pipeline
Figure 2: Multi-stage documentation generation pipeline
TME deploys the solution on Amazon Bedrock, leveraging its managed infrastructure, built-in security controls, and native support for agent orchestration through the Strands Agents SDK.
Technical implementation
Scaling beyond context windows: Multi-stage documentation generation
One of the primary challenges in automating documentation for large legacy codebases is operating within foundation model context limits. Rather than forcing all documentation through a single pipeline, the solution optimizes cost-latency tradeoffs by selectively applying agentic orchestration for dynamic context-dependent operations and streamlined inference for more deterministic code transformations:
- Technical documentation generation benefits from agentic RAG to resolve language-specific constructs on demand.
- Business documentation generation leverages structured prompts over pre-processed YAML files.
- Process flow diagrams generation uses bottom-up diagram composition to handle arbitrary code depth.
| Capability | Architecture | Rationale |
| Technical docs | Strands Agents + RAG | Code comprehension requires retrieving language-specific context |
| Business docs | Direct API + Structured prompts | YAML files already contain necessary structure; no retrieval needed |
| Process flows diagrams | Direct API + Specialized prompts | Diagram transformation is a targeted text-to-text task |
The table above summarizes the architecture approaches and rationale, while the following sections provide further detail about each approach. These architecture choices reflect the different nature of each task. Technical documentation requires the agent to dynamically retrieve context about unfamiliar NCL constructs—hence the RAG approach. Business documentation works from already-structured YAML files that contain the needed information, making retrieval unnecessary. Process flow diagrams involve a deterministic graph-construction step followed by a targeted text-to-text transformation, which is best served by direct API calls with specialized prompts.
Technical documentation: Agentic RAG
For technical documentation, the solution deploys a Strands Agent integrated with an Amazon Bedrock Knowledge Base built on Amazon Titan Text Embeddings V2, containing NCL programming language references, information about the NatStar IDE, and user manuals.
The solution processes NCL source files individually, so each code file becomes an independent unit of work. The agent performs the following actions for each file:
- Contextual code understanding: The agent queries the knowledge base to resolve unknown function signatures and language-specific constructs before generating documentation, retrieving relevant language documentation only when needed, using semantic search via Amazon Titan Text Embeddings V2 against a FAISS vector index stored in Amazon S3.
- Tool-augmented workflow: Three specialized tools enable the agent’s autonomous operation: (1) Code retrieval (
s3_file_read) reads NCL source code files from Amazon S3, (2) Knowledge base search (retrieve_from_faiss_index) performs semantic search over indexed NCL documentation and language references using Amazon Titan Text Embeddings V2, and (3) Documentation writer (s3_file_write) writes the generated YAML documentation back to Amazon S3. - Iterative refinement: The agent orchestrates multiple reasoning steps, retrieving additional context as needed to ensure accuracy. This iterative loop is managed by the Strands Agents SDK, which orchestrates tool calls and conversation turns with Anthropic Claude Sonnet 4 on Amazon Bedrock.
As a result, the system generates a YAML file with technical documentation for each existing code file, detailing multiple important dimensions such as code summary, existing dependencies, identified rules and conditions, and more. The following diagram shows the agentic RAG workflow. Boxes represent the agent’s actions and tools; arrows show the sequence of operations, and the loop illustrates how the agent iteratively retrieves context from the knowledge base before generating documentation for each file.
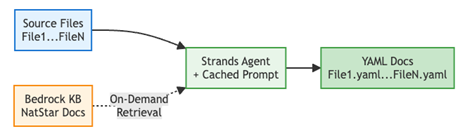
Figure 3: Agentic RAG workflow for technical documentation
Iteratively, the following techniques enable the technical documentation step to scale with larger codebases while minimizing token usage:
- Prompt caching: System prompts cached across batch runs using Amazon Bedrock’s prompt caching feature, yielding approximately 90% savings on system prompt tokens.
- On-demand RAG: Query knowledge base only for unknown constructs, avoiding bloated context.
- Linear scaling: Because each file is documented independently, processing time scales linearly with the number of files. Doubling the file count roughly doubles processing time, without the exponential growth that would result from analyzing all files together.
Business documentation: Prompt-optimized inference
Business documentation is generated using the Amazon Bedrock Converse API with structured prompts with explicit output schemas and domain-specific NCL terminology that extract business-relevant patterns from the previously generated technical YAML files.
Business documentation is split into process branches to establish natural context boundaries:
- Build dependency graph: Parse all YAML files using NetworkX.
- Classify hierarchy: Identify process levels (L0→L1→L2→L3) based on call depth.
- Extract branches: Segment into complete execution paths from L0 (process overview) entry points.
- Analyze per branch: Large Language Model (LLM) receives full call tree + business rules + queries.
Each process branch fits within context limits ensuring the generated diagrams accurately represent the business logic, decision points, and process flows encoded in the original NCL code. The following diagram depicts the business documentation workflow. Boxes represent pipeline stages, arrows indicate data flow, and the branching structure shows how the dependency graph is segmented into process branches before analysis.
![]()
Figure 4: Business documentation generation workflow
The following techniques — implemented in Python with LLM calls to Anthropic Claude Sonnet 4 via the Amazon Bedrock Converse API — enable the business documentation step to scale with larger codebases while staying within context limits:
- Execution order graphs: Processes files in dependency order, loading only what is needed at each step.
- Process boundaries as context limits: Segments analysis at natural boundaries, keeping each prompt within token limits.
- Complete call trees: Summarizes code structure compactly, avoiding the need to include full source in context.
This approach, powered by the Amazon Bedrock Converse API with Anthropic Claude Sonnet 4:
- Synthesizes process hierarchies: Transforms multi-level function dependencies (L0-L3) into business process narratives.
- Surfaces business rules: Extracts validation logic, error conditions, and database operations relevant to business stakeholders.
- Generates comparative analysis: Identifies common patterns and relationships across multiple process flows.
Process flow diagrams: Specialized prompts for diagram transformations
Process visualizations require a multi-step approach. First, the agentic technical documentation generator extracts conditional logic, database queries, and process/system errors from the code. From this extracted information, we create technical process flows using Python-based graph construction, which are then refined with LLM calls. These Mermaid diagrams are produced during the technical documentation step described in the previous section. Then, the pipeline sends specialized prompts to Anthropic Claude Sonnet 4 on Amazon Bedrock to transform technical Mermaid diagrams into simplified, business-friendly flowcharts—collapsing technical functions into meaningful business steps while preserving critical error handling and decision points.
Process flows use bottom-up composition to handle arbitrary execution depth:
- Phase 1 – Individual Diagrams: Each YAML file generates a standalone Mermaid flowchart with color-coded nodes (actions, conditions, errors, queries). These flowcharts are generated via the Amazon Bedrock Converse API with Anthropic Claude Sonnet 4, using structured prompts that specify Mermaid syntax.
- Phase 2 – Hierarchical Merging: Child diagrams are substituted in parent call sites by prefixing node IDs and connecting entry/exit points. Token constraints are mitigated by partially connecting diagrams to the token limit.
- Phase 3 – Business Transformation: LLM simplifies merged diagrams by collapsing technical steps while preserving validation logic and decision points, allowing output diagrams to be connected without token constraints.
The following diagram illustrates the process for generating flow diagrams. Boxes represent processing steps, color-coded nodes in the output correspond to different flow element types (actions, conditions, errors, database queries), and arrows show how individual diagrams are merged bottom-up before business transformation.
![]()
Figure 5: Hierarchical process flow diagram generation
The following techniques — combining Python-based graph operations (via NetworkX) with targeted LLM calls through the Amazon Bedrock Converse API — enable the process flow diagram creation step to scale with larger codebases while minimizing token usage:
- Bottom-up composition: Builds understanding from leaf functions upward, requiring only local context at each step.
- Diagram merging at call sites: Combines pre-computed diagrams at integration points, avoiding redundant analysis.
- Unbounded depth capability: Handles arbitrary call depth without increasing context size, since each layer is processed independently.
Results and business impact
The solution, designed as a PoC, has demonstrated success on a subset of the TME codebase:
- Automated legacy code documentation across 2 of 10 modules in a single core business application using generative AI.
- Generated three documentation types (technical, business, and process flows); all validated positively by TME’s technical and business experts. TME’s remaining NCL experts also reviewed a representative sample of the generated documentation, comparing it against the original source code and domain knowledge. They confirmed the accuracy of extracted business rules, function descriptions, and process flow representations.
- Established a reusable agentic architecture applicable to other legacy systems across TME’s enterprise application portfolio.
Note: This blog post describes a PoC that documented 2 of 10 modules in a single TME application. Results and approaches may vary in production implementations.
Conclusion
TME’s use of Amazon Bedrock for automated legacy code documentation demonstrates how generative AI can be used to address one of the most challenging aspects of enterprise modernization: understanding and documenting decades-old systems. By combining Anthropic Claude Sonnet 4 on Amazon Bedrock with intelligent agent orchestration through Strands Agents SDK, TME has created a scalable platform that transforms months of manual documentation work into an automated process.
As enterprises worldwide face similar modernization challenges, TME’s solution offers a replicable model for leveraging agentic AI to bridge the gap between legacy mainframe applications and cloud-native architectures. Building on these results, TME plans to expand the solution across its full application estate and explore further generative AI capabilities, including conversational code exploration and AI-assisted code modernization.
To learn more about how Amazon Bedrock AgentCore can accelerate your modernization initiatives, visit https://aws.amazon.com/bedrock/agentcore/ or contact your AWS account team to discuss your specific use case.