AWS for Industries
Architecting the Semantic MCP Server: Edge Deployment of Fine-Tuned SLMs to Solve the Data Ingestion Problem for Telco Operations
This post introduces the “Semantic MCP Server” pattern—a hybrid edge architecture designed to solve the “Data Gravity” problem in Telecommunications. It demonstrates how to reduce Cloud inference costs and ensure Data Sovereignty using Fine-Tuned Small Language Models (SLMs) deployed on AWS Outposts or AWS AI Factories.
The Target Audience are Telecommunications Network Architects, MLOps Engineers, and CTOs seeking to implement Autonomous Operations at scale.
The current state of telco operations: challenges and complexity
Communication Service Providers (CSPs) are currently navigating a pivotal transition: moving from traditional, reactive Network Operations Centers (NOCs) toward the vision of fully Autonomous Operations. The goal is clear—self-healing infrastructure that can detect, diagnose, and resolve anomalies with minimal human intervention.
However, as operators are willing to integrate Generative AI to accelerate this journey, they face a problem: the high volume and complexity of telemetry data.
Modern telecommunications networks generate terabytes of data every day. Probes and network elements constantly generate Detailed Records (DRs), exporting every signaling event, user session, and interface handshake. In this environment, noise is the problem, not data availability.
Consider a typical failure scenario: when a User Plane Function (UPF) degrades, It triggers a cascading “storm” of thousands of sympathetic alarms—5GMM_CAUSE_CONGESTION messages, RRC_SETUP_FAIL events, and timeouts—across neighboring gNodeBs and AMFs.
For Telecom Providers attempting to build GenAI-powered Root Cause Analysis (RCA) agents, this presents a dangerous economic problem.
The Cost of “Naive” Intelligence
There is a temptation to pipe these raw filtered logs streams into powerful, frontier Large Language Models (LLMs) to let the AI “figure it out”. While technically feasible, this approach is financially unsustainable.
Token Explosion: Streaming gigabytes of raw data or errors to the frontier LLM consumes millions of input tokens on irrelevant data (noise).
Latency Penalties: Waiting for a model to process thousands of messages just to find one critical error code introduces delays in real-time operations.
To achieve the promise of Autonomous Operations without causing an explosion in operational costs, operators must solve the Signal-to-Noise ratio problem before the data reaches the reasoning layer, leveraging an architecture that balances the intelligence of GenAI with the frugality required for scale.
The Solution Overview
To solve the cost and latency problem, we introduce the “Semantic” MCP Server pattern. This architecture moves the data processing logic from the AWS Region to the edge (AWS AI Factories, AWS Outposts or COTS hardware on-premises), leveraging the Model Context Protocol (MCP) to create a standardized, intelligent interface between your raw data and your AI agents.
With generic COTS hardware, data scientists train models in Amazon SageMaker, but operations teams manage the edge (On-Prem). This forces an handover process where models must be manually exported, converted, and re-containerized using different tools. In contrast, with AWS AI Factories or AWS Outposts the edge becomes a fully managed infrastructure in your data centers, allowing the use of the exact AWS Services, APIs, and deployment scripts for both training and inference, effectively eliminating the friction of moving new models to production. Furthermore, maintaining a bare-metal GPU cluster is difficult, involving complex compatibility matrices of NVIDIA drivers, CUDA versions, and Linux kernel patches. On COTS hardware, this heavy maintenance falls entirely on the IT and operation departments. Leveraging AWS AI Factories and AWS Outposts, AWS handles the entire hardware lifecycle including patching and replacement. This allows telecom providers to focus entirely on improving inference quality and refining the model.
The core innovation is the semantic filtering. Instead of a pipe that streams gigabytes of logs using some static filters, the MCP Server acts as a domain-aware firewall. It uses a locally hosted, fine-tuned Small Language Model (SLM) to read the stream, understand the 3GPP context, and output only the causal chain in a lightweight JSON format.
To experiment with this approach, the recommendation is to use an high-reasoning SLM with a parameter count optimized for execution at the edge, ensuring sufficient memory remains free for parsing the data coming from the network.
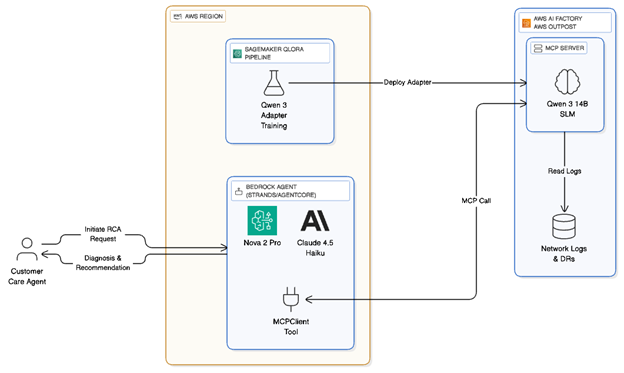
Figure 1: General Architecture
Architectural Considerations: Mitigating MCP Constraints via Semantic Compression
While the MCP establishes a standardized contract for agent-tool interaction, it is not architected to serve as a high-volume data pipeline. Direct integration of raw telemetry streams via MCP frequently introduces critical bottlenecks, including context window saturation, serialization latency, and the query multiplier effect. An LLM is a reasoning engine, not a database, and attempting to utilize the context window for large-scale data joins or anomaly detection degrades both performance and reasoning quality.
Our “Semantic” architecture specifically mitigates these inherent constraints through a strategy of semantic compression.
Standard MCP implementations often suffer from performance degradation when serializing large datasets (e.g., thousands of log rows) into the text-based context window. This new paradigm ensures that raw telemetry (Gigabytes) never traverses the MCP transport. The local SLM performs the heavy reduction, and the MCP server transmits only the synthesized diagnostic signal (Kilobytes). This ensures the cloud agent’s reasoning capacity is focused on decision-making rather than data parsing.
The SLM as a cognitive ETL layer
MCP lacks native ETL (Extract, Transform, Load) capabilities, typically requiring data to be pre-cleaned and normalized—a significant challenge with proprietary, unstructured telco logs (e.g., ASN.1 traces, hex dumps). We leverage the local model as a just-in-time extraction engine. It normalizes heterogeneous vendor logs into a strict JSON schema on-the-fly, effectively handling the “data preparation” requirements at the edge without necessitating complex upstream engineering pipelines.
Reducing Transactional Overhead
To avoid the “query multiplier effect”—where a complex user request triggers a cascade of backend queries that saturate concurrency limits—we encapsulate the analysis logic within the edge node. Instead of the cloud agent performing iterative, low-level data joins over the network, it issues a single high-level intent (e.g., analyze_telemetry). The high-concurrency data correlation occurs locally at the edge, satisfying the latency requirements of operations that would otherwise be impractical over a chat-based protocol.
The Engine: Local SLM Inference
To validate the architecture described in this blog, Qwen 3 14B has been selected as reference LLM. However, the Semantic MCP pattern is inherently model-agnostic; operators can experiment with other open-weight SLMs, to find the optimal balance of performance and compatibility for their specific use cases. In complex RCA scenarios, standard instruction-tuned models often suffer from ‘premature closure’—latching onto the first visible error code (e.g., a sympathetic RRC_SETUP_FAIL) and tagging it as the root cause. By instructing the model to explicitly reason through the timestamp sequence inside a <thought> block before generating the final JSON, the enforcement is it to disqualify consequential errors.
While 4-bit quantization theoretically introduces a minimal perplexity degradation, empirical benchmarks—such as those detailed in ‘The Case for 4-bit Precision: k-bit Inference Scaling Laws’ (Dettmers et al.) —show that the 14B architecture retains over 97% of its reasoning capabilities (MMLU/GSM8K) compared to FP16. Crucially, this compression is what enables us to fit the model’s 14B ‘intelligence’ alongside a massive 16k context window entirely within the VRAM of a single edge GPU NVIDIA A10G or T4 GPU, consuming ~9GB of VRAM (using the Q4_K_M quantization profile). The selection of ‘Medium’ K-quant profile, it employs intelligent mixed-precision—keeping sensitive attention heads at 6-bit, while compressing feed-forward layers to 4-bit—providing a trade-off between perplexity retention and memory footprint. We rely on specific custom CUDA kernels (integrated within llama.cpp) to use the 4-bit arithmetic with A10G/T4 hardware. These kernels perform “on-the-fly” dequantization inside the GPU registers, allowing us to store weights in compressed 4-bit format but compute them in high-precision 16-bit with negligible latency.
For detailed information about how to deploy an SLM at the edge on AWS Outpost you can refer to this blog: Running and optimizing small language models on-premises and at the edge.
The Brain: Fine-Tuning with LoRA on Amazon SageMaker
As a result of its generic pre-training on public datasets, Qwen 3 14B is natively fluent in standard 3GPP protocols (like TS 24.501). However, it lacks the ‘vertical knowledge’ required to interpret the proprietary nuances of a specific carrier’s multi-vendor environment. A generic model interprets a 5GMM_CAUSE_Network_Failure as a generic error, but for different software vendors or different software releases, that error combined with hex sub-codes indicates different problems.
To bridge this gap without the cost of full-parameter training, the selection is to utilize QLoRA (Quantized Low-Rank Adaptation). Adopting the strategy of instruction tuning over continued pre-training, we create an instruction tuning dataset derived from the carrier trouble tickets, leveraging input proprietary log data (e.g., encoded ASN.1 traces, vendor-specific debug codes). The outcome is the “Gold Standard” analysis that solved that specific ticket. An important point is to rigorously mask PII (IMSIs, IP addresses) from the training set. If you train on raw PII, the model might “memorize” specific subscribers and hallucinate them into future diagnoses.
The implementation of specific hyperparameter safeguards to prevent catastrophic forgetting, in some case a pitfall where a model becomes an expert in new technical codes but loses its general ability to structure valid JSON, or construct coherent English sentences:
- Constrained Rank (r=16): By choosing a lower rank for the LoRA adapters, the number of trainable parameters is limited. This acts as a limit on how much the model can change, ensuring the fine-tuning process do not rewrite the model foundational grammar and logic.
- Limited Epochs (1-3): Technical logs are highly repetitive. Training for too long causes the model to overfit, effectively memorizing the specific logs in the training set rather than learning the underlying patterns. Limiting epochs ensures the training is stop at the point of maximum adaptation, just before the model starts losing its reasoning flexibility.
While inference happens at the edge, training requires the compute scale of the AWS Region. The customer can utilize Amazon SageMaker Training Jobs to execute the fine-tuning process.
We utilize QLoRA (Quantized Low-Rank Adaptation) to adapt Qwen 3 14B to proprietary vendor logs.
The QLORA: Efficient Finetuning of Quantized LLMs (Dettmers et al.) paper demonstrated that applying adapters to all linear layers (including feed-forward blocks) is necessary to match the performance of full-parameter fine-tuning. For our specific use case, we found this configuration to be necessary. Unlike natural language, 3GPP traces follow a rigid, non-semantic syntax; by targeting the feed-forward networks (gate_proj, up_proj, down_proj) in addition to attention layers, we ensure the model can effectively internalize these strict formatting rules without underfitting.
The approach is to leveraging grammar-constrained decoding for structural validity, with the fine-tuning to optimize inference efficiency. Our observations align with research on Grammar-Aligned Decoding, specifically ‘The Hidden Cost of Structure’ (Schall & de Melo). While Grammar Constraints limit the possibilities, Fine-Tuning optimizes the probabilities.
As Schall et al. demonstrate, generic instruction-tuned models often exhibit ‘friction’ between their conversational training and strict structural constraints. This conflict forces the model to generate valid-but-unnecessary tokens as it fights to satisfy its internal chat objectives within the grammar’s bounds. On fine-tuned model’s, probability distribution aligns with the schema, enabling the shortest and most direct path to the End-of-Sequence token.
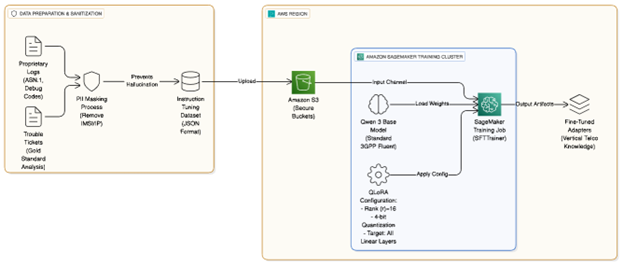
Figure 2: Fine Tuning and Data Ingestion
For the stet-by-step instructions about how to fine tune an open weight model on Amazon SageMaker, you can read this blog: Fine-tune OpenAI GPT-OSS models on Amazon SageMaker AI using Hugging Face.
The Interface: Building the MCP Server
Using the Anthropic MCP Python SDK, we wrap this logic into a server that exposes a “tool”. The Bedrock Agent can leverage this tool to collect only the subset of the logs or data coming from the network that are useful for the investigation. The complexity of the 3GPP analysis is hidden behind a simple function called by the frontier model, without the need of implement any agent to agent protocol communication.
The Orchestration: Claude 4.5 Haiku or Amazon Nova 2 Pro
Now that the “Semantic” filter on the edge is completed, we need a brain to orchestrate the diagnosis. For the agent logic, a possible models to evaluate is Claude 4.5 Haiku on Amazon Bedrock.
Alternatively, for scenarios requiring the deepest possible reasoning capability over pure speed, the customer can experiment with Amazon Nova 2 Pro which achieved superior performances in the τ²-bench-telecom tools use. While Claude 4.5 Haiku excels in latency, Nova 2 Pro provides the highest ‘General Intelligence’ in the AWS family. Its ability to synthesize ambiguous tool outputs makes it the ideal choice for “Level 3” automated troubleshooting where accuracy is non-negotiable.
To manage the interaction between the cloud-based brain and the edge-based tools, the suggestion is to utilize AWS Strands, an open-source framework from AWS designed for building production-grade agentic workflows. Strands abstracts the complexity of state management and tool binding, allowing to focus on the agent’s persona.
For the production deployment of the orchestration agent, the suggested service is Amazon Bedrock AgentCore. Telco troubleshooting is rarely a “single-shot” query; it requires maintaining state across a long diagnostic session. Amazon Bedrock AgentCore provides a managed runtime that handles memory management (context retention across turns), identity propagation (knowing who invoked the agent), and secure networking (PrivateLink connectivity to your VPC). By offloading these infrastructure concerns to Amazon Bedrock AgentCore, the code can be architected as a resilient, serverless microservice capable of handling multiple concurrent troubleshooting sessions without managing a single EC2 instance.
For a deep dive on deploying agents on Amazon Bedrock Agentcore, refer to the guide: Make agents a reality with Amazon Bedrock AgentCore.
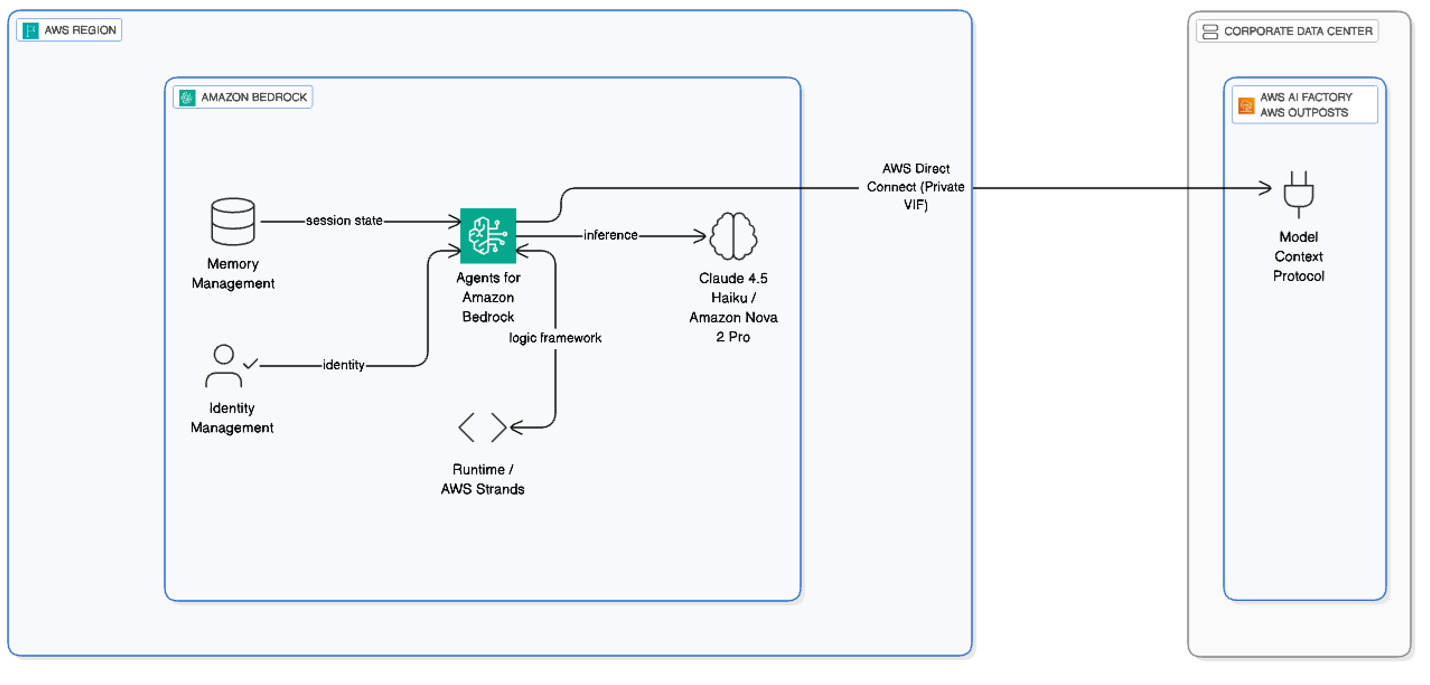
Figure 3: Hybrid Design
The Foundation: Data Preparation and Training Dataset Construction
The training dataset is constructed from resolved trouble tickets by aligning customer complaints with network logs and validated resolutions. For each ticket, can be queried 60 second log window around the symptom onset, filter out routine operations (heartbeats, keepalives) and sympathetic noise (consequential failures), reducing 1,000+ raw log lines to 5-10 causal events. Ground truth labels are derived from the engineer’s resolution notes and mapped to a strict error code taxonomy. Each training example follows an instruction-tuning format with a system prompt defining the analysis rules, the filtered logs as input, and a JSON structure containing the error codes and root cause (“events”) as output. To improve precision and limit false positives in the output of the model, negative examples can be added as part of the dataset. Here two samples JSON:
Real-World Scenario: The “YouTube Freeze”
Let’s see a possible real scenario.
The Symptom:
A customer care agent reports: “Subscriber (IMSI XX2269) is complaining that YouTube buffers constantly, even though they have full signal bars.”
The Semantic RCA Process:
Agent Action (Region): Claude 4.5 Haiku instantly parses the request and calls analyze_network_telemetry(imsi="XX2269", context="YouTube Buffering").
Edge Processing (Qwen 3 14B): The Semantic MCP server at the edge scans megabytes of flow records. Using its “Thinking Mode”, Qwen ignores the successful RRC_CONNECTED signals and correlates a pattern of high TCP_Retransmission with Transport_Jitter.
MCP Output (JSON):
Agent Response (AWS Region): Claude 4.5 Haiku synthesizes the finding:
“The subscriber is experiencing Packet Loss on the Transport Backhaul.
While the radio signal is strong, the N3 interface has 15% retransmission jitter.
Recommendation: “Dispatch Field Tech to inspect Microwave Link ID 44 at the site.”
As Result, a complex soft-failure diagnosed in seconds, with zero PII leaving the premises and minimal cloud costs.
Integration Strategy: Enhancing current OSS/BSS
A common concern for operators is how this new architecture fits with existing investments in Service Assurance (SA) and log Analytics platforms. The Semantic MCP Server is not designed to replace these systems but to act as a semantic sidecar that helps in solving the root cause analysis and trouble tickets problems.
The Semantic MCP Server access the CSPs network data leveraging the current on-premises data lake and infrastructure, and generates a JSON output that can be forwarded to your existing tools.
Deployment: Hybrid Resilience and Data Sovereignty Strategy
For Communication Service Providers (CSPs), latency is an engineering challenge, but data residency is a legal requirement. Regulations like GDPR in Europe or local telecommunications acts often strictly forbid sensitive subscriber data (PII) or raw signaling from leaving the operator’s physical premises.
The Semantic MCP architecture is designed specifically to help with this constraint using a hybrid edge pattern. The data do not move to the model, it is the model that moves where the data are stored.
The Semantic MCP Server runs AWS Outposts or AWS AI Factories. This hardware sits physically within the Telco’s datacenter. The reasoning agent (Bedrock + Strands) runs in the AWS Region to leverage the massive availability of Claude 4.5 or Nova 2 Pro.
Connectivity is established via AWS Direct Connect using a private VIF (Virtual Interface). Traffic never traverses the public internet.
A “Privacy-by-Design” workflow ensuring that no raw PII ever enters the AWS Region is implemented.
The strict data flow
Ingestion (On-Premise): The MCP Server reads the raw data. At this stage, the data contains IMSIs, MSISDNs, and cell locations.
Local Inference (On-Premise): The Qwen 3 model processes the text. The model is instructed via system prompt to abstract identities in its reasoning trace (e.g., referring to ‘The Subscriber’ instead of ‘IMSI 22201’). However, because LLMs are probabilistic, we do not rely on them for GDPR compliance. Before the JSON payload leaves the on-premises, a deterministic Python middleware layer acts as the final gatekeeper. It programmatically intercepts the structured output to remove or hash any specific identifiers found in the fields, ensuring zero-trust data sovereignty regardless of the model’s output. The JSON that travels over AWS Direct Connect contains zero PII. It describes the physics of the failure (e.g., “Jitter on N3 interface”), not the identity of the user.
This architecture ensures that the Reasoning Layer (Amazon Bedrock) acts as an anonymous consultant: it solves the technical problem without ever “knowing” who the subscriber is.
Conclusion
After fine-tuning Qwen 3 14B on 1,300 examples using QLoRA (r=16, α=32, 1 epoch), we validated the model on a sophisticated test set of 1,000 examples requiring threshold detection, causal chain analysis, and temporal reasoning. The model achieved an F1 score of 0.945, with 97.5% precision and 91.7% recall, correctly identifying the root cause in
773 out of 1,000 cases. The model reduced false positives by 93% compared to earlier iterations through the combination of negative examples in training (teaching when not to report errors), optimized generation parameters (repetition_penalty=1.2), and a deterministic post-processing filter for known sympathetic noise patterns. The average inference latency was 6.45 seconds per example on a single NVIDIA A10 GPU using 4-bit quantization.
The journey toward Autonomous Networks is more about building smarter architectures. In this post, we explored how to tackle three main problems of Telco Operations:
Economic Efficiency: In our tests, we reduced the token consumption for Root Cause Analysis by 90%, filtering massive noisy logs and using only kilobytes of semantic data.
Operational Velocity: By processing data at the edge, we eliminated the latency of data transfer, enabling near real-time diagnosis of complex Quality of Experience (QoE) issues like video freezing.
Uncompromising Privacy: We turned the MCP Server into a privacy firewall. By enforcing strict, deterministic hashing and redaction at the code level before any packet leaves the on-premises, we ensure that the cloud-based reasoning agent receives only the physics of the failure (e.g., “Jitter on N3 interface”) without ever touching the identity of the subscriber.
Telco operators can now experiment with this pattern, finding the best model to implement the Semantic MCP Server and leveraging the scaling of the AWS Region for frontier models.